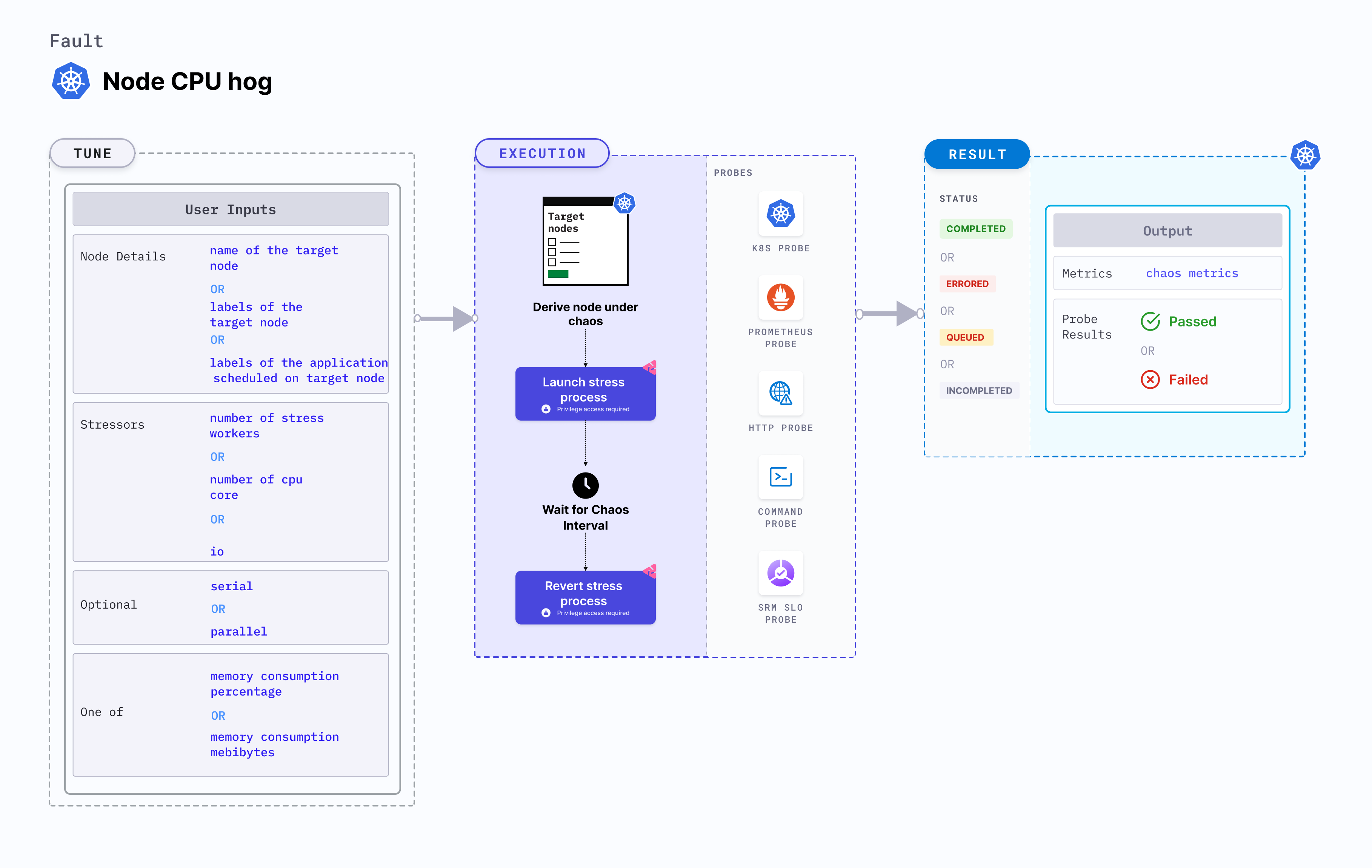
Node CPU hog
Last updated on
Node CPU hog exhausts the CPU resources on a Kubernetes node.
- The CPU chaos is injected using a helper pod running the Linux stress tool.
- The chaos affects the application for a specific duration.
Use cases
Node CPU hog fault:
- Verifies the resilience of applications whose replicas get evicted on the account of the nodes turning unschedulable (in NotReady state) or new replicas unable to be scheduled due to a lack of CPU resources.
- Causes CPU stress on the target node(s).
- Simulates the situation of lack of CPU for processes running on the application, which degrades their performance.
- Verifies metrics-based horizontal pod autoscaling as well as vertical autoscale, that is, demand based CPU addition.
- Helps the scalability of nodes based on growth beyond budgeted pods.
- Verifies the autopilot functionality of cloud managed clusters.
- Verifies multi-tenant load issues; that is, when the load increases on one container, it does not cause downtime in other containers.
Permissions required
Below is a sample Kubernetes role that defines the permissions required to execute the fault.
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: hce
name: node-cpu-hog
spec:
definition:
scope: Cluster
permissions:
- apiGroups: [""]
resources: ["pods"]
verbs: ["create", "delete", "get", "list", "patch", "deletecollection", "update"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "get", "list", "patch", "update"]
- apiGroups: [""]
resources: ["chaosEngines", "chaosExperiments", "chaosResults"]
verbs: ["create", "delete", "get", "list", "patch", "update"]
- apiGroups: [""]
resources: ["pods/log"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["pods/exec"]
verbs: ["get", "list", "create"]
- apiGroups: ["batch"]
resources: ["jobs"]
verbs: ["create", "delete", "get", "list", "deletecollection"]
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list"]
Prerequisites
- Kubernetes > 1.16 is required to execute this fault.
- The target nodes should be in the ready state before and after injecting chaos.
Supported environments
| Platform | Support Status |
|---|---|
| GKE (Google Kubernetes Engine) | ✅ Supported |
| EKS (Amazon Elastic Kubernetes Service) | ✅ Supported |
| AKS (Azure Kubernetes Service) | ✅ Supported |
| GKE Autopilot | ❌ Not supported |
| Self-managed Kubernetes | ✅ Supported |
Mandatory tunables
| Tunable | Description | Notes |
|---|---|---|
| TARGET_NODES | Comma-separated list of nodes subject to node CPU hog. | For more information, go to target nodes. |
| NODE_LABEL | It contains the node label used to filter the target nodes. | It is mutually exclusive with the TARGET_NODES environment variable. If both are provided, TARGET_NODES takes precedence. For more information, go to node label. |
Optional tunables
| Tunable | Description | Notes | |
|---|---|---|---|
| TOTAL_CHAOS_DURATION | Duration that you specify, through which chaos is injected into the target resource (in seconds). | Default: 60 s. For more information, go to duration of the chaos. | |
| LIB_IMAGE | Image used to inject stress. | Default: harness/chaos-go-runner:main-latest. For more information, go to image used by the helper pod. | |
| RAMP_TIME | Period to wait before and after injecting chaos (in seconds). | For example, 30 s. For more information, go to ramp time. | |
| NODE_CPU_CORE | Number of cores of the CPU to be consumed. | Default: 2. For more information, go to node CPU cores. | |
| NODES_AFFECTED_PERC | Percentage of total nodes to target, that takes numeric values only. | Default: 0 (corresponds to 1 node). For more information, go to node affected percentage. | |
| SEQUENCE | Sequence of chaos execution for multiple target pods. | Default: parallel. Supports serial sequence as well. For more information, go to sequence of chaos execution. |
Node CPU cores
Number of cores of CPU that will be consumed. Tune it by using the NODE_CPU_CORE environment variable.
The following YAML snippet illustrates the use of this environment variable:
# stress the CPU of the targeted nodes
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: node-cpu-hog
spec:
components:
env:
# number of CPU cores to be stressed
- name: NODE_CPU_CORE
value: '2'
- name: TOTAL_CHAOS_DURATION
VALUE: '60'
Node CPU load
Percentage of CPU that will be consumed. Tune it by using the CPU_LOAD environment variable.
The following YAML snippet illustrates the use of this environment variable:
# stress the CPU of the targeted nodes by load percentage
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: node-cpu-hog
spec:
components:
env:
# percentage of CPU to be stressed
- name: CPU_LOAD
value: "100"
# node CPU core should be provided as 0 for CPU load
# to work otherwise it will take CPU core as priority
- name: NODE_CPU_CORE
value: '0'
- name: TOTAL_CHAOS_DURATION
VALUE: '60'