Deployment Architecture
Before you begin, review the following
System Architecture Overview
To determine and improve the resilience of an application, you need to execute certain steps (known as chaos experiments) on your cluster. This involves two essential components interacting with each other:
- Control Plane (HCE SaaS)
- Execution Plane (Your host/cluster)
Depending on the version of HCE (SaaS or Self-Managed Platform), the control plane is hosted by Harness (for SaaS) or within your domain (for example, harness.your-domain.io).
The diagram below illustrates the relationship between HCE SaaS (the control plane) and its components (such as chaos experiments, ChaosHub, database, and so on) interact with your host or cluster (the execution plane components such as Kubernetes or Linux infrastructure), demonstrating how experiments are conducted using HCE.
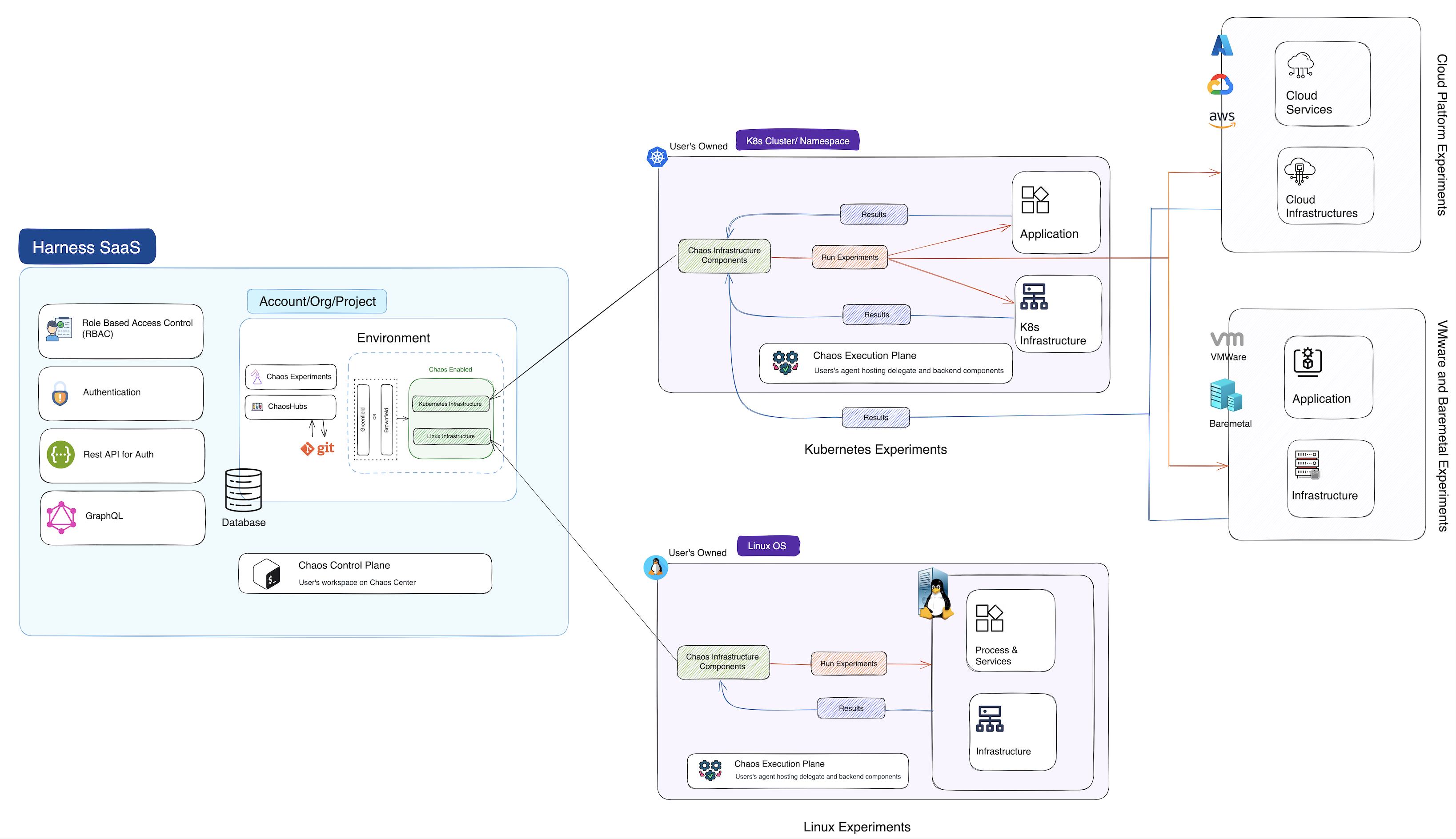
From the diagram, you can infer the following at a high level:
- A connection is established between the execution plane and the control plane.
- The control plane sends chaos experiments to the execution plane for execution.
- Results from the execution plane are sent back to the control plane.
For detailed steps on this interaction, refer to interaction between the control plane and execution plane.
Kubernetes Execution Plane
The Kubernetes execution plane consists of chaos infrastructure components like workflow controllers, and subscribers that are described earlier, and backend execution infrastructure components like ChaosExperiment CR, ChaosEngine CR, etc.
Linux Execution Plane
The Linux execution plane consists of only the Linux chaos infrastructure daemon service.
Linux chaos infrastructure daemon service is a Systemd service responsible for injecting faults into a Linux machine as a part of a chaos experiment.
- The infrastructure relies on a polling model to fetch and execute the experiments or tasks from the control plane.
- It uses a rotating access token based authorization along with TLS encryption to ensure secure communication with the control plane.
- Multiple faults in an experiment can execute serially or in parallel to each other, depending on how the faults have been defined.
- Every machine has a one-to-one mapping with the infrastructure daemon service, and all of these infrastructure(s) communicate with the control plane to:
- Fetch experiments for execution
- Update experiment execution status
- Stream experiment logs
- Send experiment execution result
Compatibility with Linux Distribution
The chaos infrastructure has been tested for compatibility in the following Linux OS distributions:
- Ubuntu 16+
- Debian 10+
- CentOS 7+
- RHEL 7+
- Fedora 30+
- openSUSE LEAP 15.4+ / SUSE Linux Enterprise 15+
Control Plane
The Harness control plane comprises microservices that enable the web-based portal to perform its functions.
You can sign in (or receive an invitation) to the Harness Platform and use the interactive UI dashboard to:
- Create a chaos environment.
- Create chaos infrastructure and enable chaos within your infrastructure.
- Define chaos experiments.
- Connect to Enterprise ChaosHubs and execute chaos experiments.
- Target resources in your infrastructure.
- Monitor experiments during execution.
Why is a Control Plane Required?
The control plane helps create, schedule, and monitor chaos experiments. It includes chaos faults that achieve the desired chaos impact on target resources.
Execution Plane
- Dedicated Chaos Infrastructure
- Harness Delegate
The Harness execution plane contains components responsible for orchestrating chaos injection into target resources. These components include:
- Operator
- Exporter (optional)
- Subscriber
- Workflow Controller
Harness Delegate introduces centralized execution plane with the component DDCR (Delegate Driven Chaos Runner), which is transient. It uses transient (short-lived) pods to implement Harness Chaos Engineering.
Why is an Execution Plane Required?
The execution plane sets up the resources (clusters) where chaos experiments are run. You will use the control plane to interact with these clusters and create chaos experiments.
You can install the execution plane components through the chaos infrastructure in clusters (either external or internal, depending on the type of chaos infrastructure used).
Interaction Between the Execution Plane and the Control Plane
Here's how the interaction unfolds when you schedule an experiment:
- After scheduling the experiment, the control plane sends it to the execution plane.
- The subscriber (part of execution plane) installs the chaos experiment on the cluster.
- Upon installation, the workflow controller identifies the experiment and triggers it.
- The operator searches for the chaos faults within the experiment and initiates their execution.
- Once the experiment completes, data (such as the experiment name, faults, probes, etc.) is sent back to the Kubernetes infrastructure server by the execution plane.
Resource Utilization Matrix
The resource utilization matrix for execution plane components is summarized below. These components are installed in the target cluster as a part of the Kubernetes-based chaos infrastructure.
The table below is indicative of low to medium-load working conditions. As chaos activity increases, more resources will be required, and the values represented here may vary.
| Deployment | container | CPU (Requested) | Memory (Requested) | Image |
|---|---|---|---|---|
| chaos-operator-ce | chaos-operator-ce | 125m | 300M | docker.io/harness/chaos-operator:1.31.0 |
| chaos-exporter | chaos-exporter | 125m | 300M | docker.io/harness/chaos-exporter:1.31.0 |
| subscriber | subscriber | 125m | 300M | docker.io/harness/chaos-subscriber:1.31.0 |
| workflow-controller | workflow-controller | 125m | 300M | docker.io/harness/chaos-workflow-controller:v3.4.16 |