Harness Chaos Engineering (HCE) overview
Welcome to Harness Chaos Engineering (HCE)! This section introduces you to the basics of chaos engineering, its importance, and its advantages.
Overview
Cloud-native applications are highly distributed, elastic, resistant to failure, and loosely coupled. You need to ensure that your application performs as expected under different failure conditions.
Chaos engineering is a technique that is relevant to all types of systems, including legacy applications and infrastructure. This is particularly important for cloud-native applications since they carry multiple points of failure due to their distributed, and elastic nature.
What is chaos engineering?
In simple terms, Chaos engineering is the technique of inducing chaos, that is, unexpected failures in the application.
The consensus is that something will go wrong in an application, so it would be better to practice what actions to take when something goes wrong and ensure that everything recovers.
The idea is that the design of an application should be resilient and handle any failure. By introducing constant chaos during the engineering phase and the production phase, you may come across issues and potential failure points that you never thought of.
A formal definition is: "Chaos engineering is the discipline of performing experiments on software to build confidence in the system's capability to withstand turbulent and unexpected conditions. Failures are intentionally injected into applications to build resilience. By proactively introducing controlled chaos into systems, you can identify weaknesses in your application and prevent catastrophic failures."
Chaos engineering isn't the same as software testing (manual or automated) which verifies that your system is working as expected. This brings you to a new concept- Chaos Engineering.
Why is chaos engineering important?
In the current landscape of fast-paced technology, system failures have a significant impact on businesses, customers, and stakeholders. Chaos engineering is a way to identify potential issues before they become major problems, helping organizations minimize downtime, mitigate risks, and improve reliability.
Shift left chaos engineering
The initial principles of chaos engineering suggest performing experiments in production (which is relevant and recommended), which is viewed as a means to validate resilience beforehand, that is, as a quality gate for larger deployment environments. This is accelerated by a need to build confidence in a highly dynamic environment in which application services and infrastructure are subject to frequent and independent upgrades. The resulting paradigm is:
- Increased ad-hoc/exploratory chaos testing by application developers and QA teams;
- Automating chaos experiments within continuous delivery (CD) pipelines.
How to implement chaos engineering to build resilient applications?
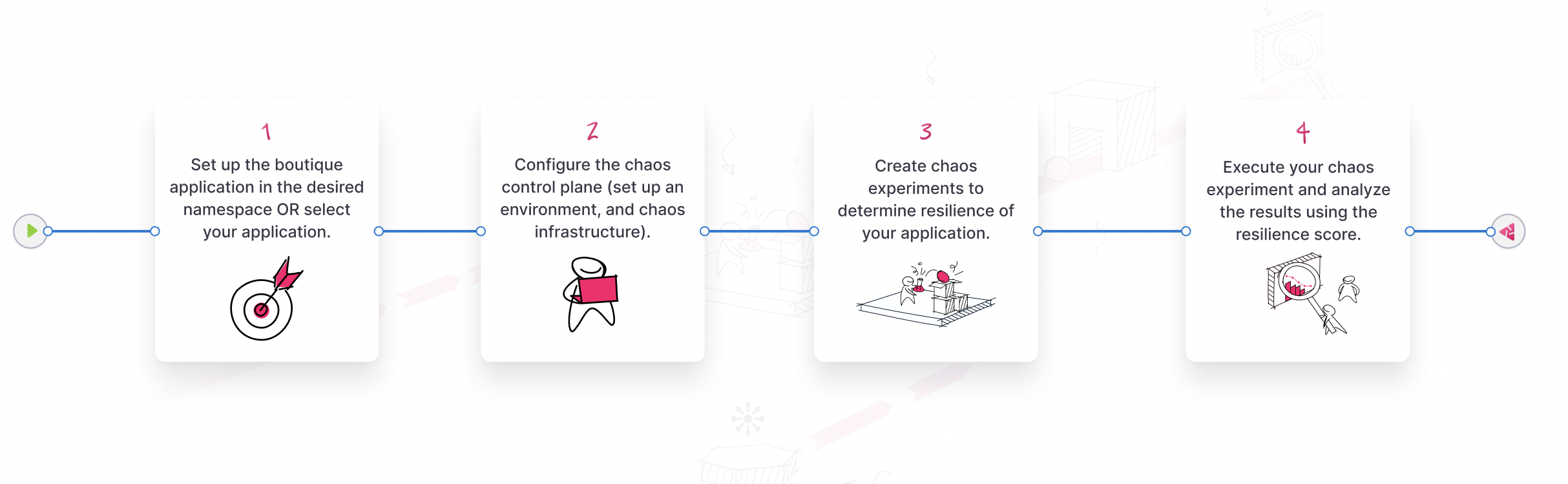
You can build resilient applications using the following steps:
- Choose or build your application;
- Configure the chaos control plane, that is:
- Set up an environment;
- Set up a chaos infrastructure;
- Create chaos experiments in your application;
- Execute the chaos experiments;
- Analyze the result.
This suggests that chaos experiments need the appropriate observability infrastructure to aid the validation of the hypotheses around the steady state. The practice of chaos engineering consists of performing experiments repeatedly, by injecting a variety of potential failures (called chaos faults) to simulate real-world failure conditions carried out against different resources (called targets).
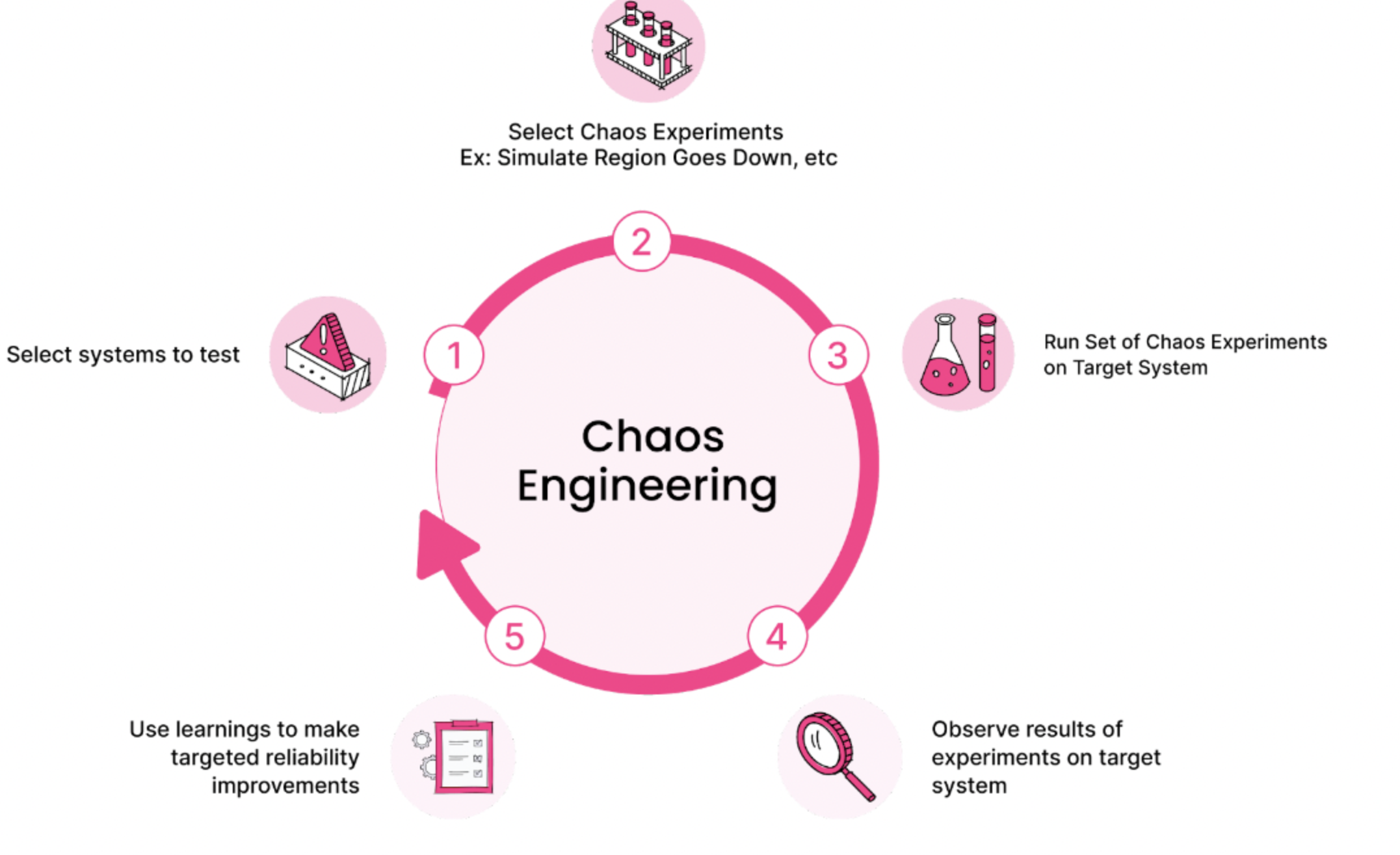
Harness Chaos Engineering (HCE) simplifies the chaos engineering practices for your organization. The diagram below describes the steps that you can perform to induce chaos into an application.
Standard chaos experiment flow of control
The standard chaos experimentation flow involves the following steps:
- Identify the steady state of the system or application under test;
- Hypothesize around the impact a particular fault or failure would cause;
- Inject this failure (or chaos fault) in a controlled manner (with a pre-determined and minimal blast radius);
- Validate whether the hypothesis is proven, and take appropriate actions if a weakness is found.
Benefits of HCE
HCE doesn't simply focus on fault injection, it helps you set up a fully operational chaos function that is based on the original principles of chaos, and addresses several enterprise needs around its practice, which include:
- Cloud native approach to chaos engineering which supports declarative definition of experiments and Git-based chaos artifact sources (chaos-experiments-as-code).
- Extensive fault library and robust suite of ready-to-use experiments, with support to construct complex custom experiments with multiple faults in the desired order.
- Centralized control plane that supports varied targets (Kubernetes-based microservices, cloud services, VMware infrastructure).
- Governance enforcement for chaos experimentation using dedicated workspaces, chaos teams, and access control.
- Native integration with Harness Continuous Delivery (CD) pipelines.
- Hypothesis validation using probes and SLO management using integration with Harness Continuous Verification (CV).
- Guided GameDay execution with detailed analytics and reporting based on experiment execution and application resilience.
- Chaos events, metrics, and logs (audit and execution) to aid in the instrumentation of APM dashboards with chaos context.