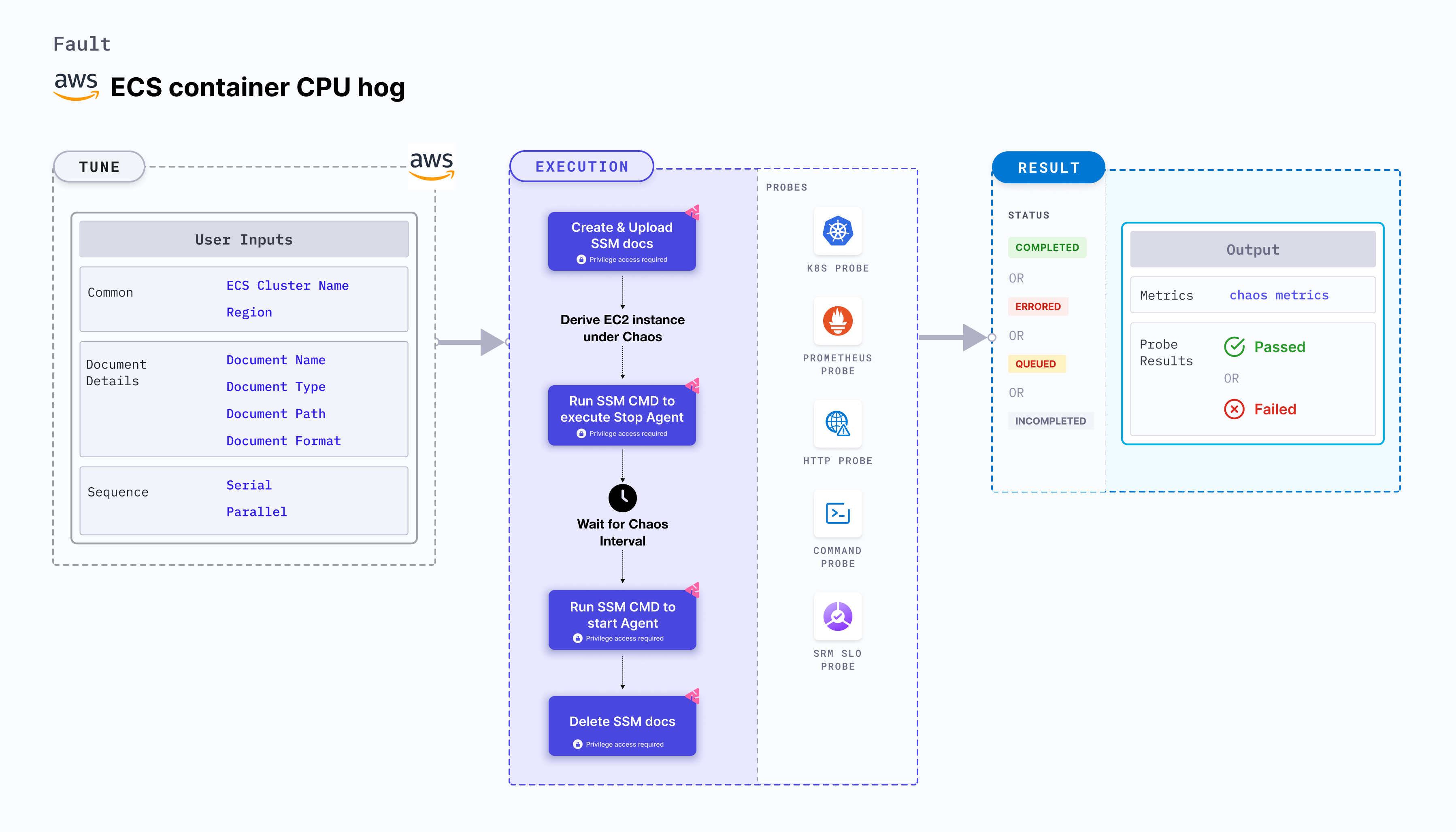
ECS container CPU hog
ECS container CPU hog disrupts the state of infrastructure resources. It induces stress on the AWS ECS container using Amazon SSM Run command, which is carried out using SSM documentation that is in-built into the fault. This fault:
- Causes CPU chaos on the containers of the ECS task using the given
CLUSTER_NAMEenvironment variable for a specific duration. - To select the Task Under Chaos (TUC), use the service name associated with the task. If you provide the service name along with the cluster name, all the tasks associated with the given service will be selected as chaos targets.
- This experiment induces chaos within a container and depends on an EC2 instance. Typically, these are prefixed with "ECS container" and involve direct interaction with the EC2 instances hosting the ECS containers.
Use cases
ECS Container CPU hog:
- Evicts the application (task container) thereby impacting its delivery. These issues are known as noisy neighbour problems.
- Simulates a lack of CPU for processes running on the application, which degrades their performance.
- Verifies metrics-based horizontal pod autoscaling as well as vertical autoscale, that is, demand-based CPU addition.
- Scales the nodes based on growth beyond budgeted pods.
- Verifies the autopilot functionality of (cloud) managed clusters.
- Verifies multi-tenant load issue, wherein when the load increases on one container, it does not cause downtime in other containers.
- Tests the ECS task sanity (service availability) and recovery of the task containers subject to CPU stress.
Prerequisites
- Kubernetes >= 1.17
- ECS container instance should be in a healthy state.
- ECS container metadata is enabled (disabled by default). To enable it, go to container metadata. If your task is running from before, you may need to restart it to get the metadata directory.
- You and the ECS cluster instances have a role with the required AWS access to perform the SSM and ECS operations. Go to systems manager documentation.
- The Kubernetes secret should have the AWS access configuration(key) in the
CHAOS_NAMESPACE. Below is a sample secret file:apiVersion: v1
kind: Secret
metadata:
name: cloud-secret
type: Opaque
stringData:
cloud_config.yml: |-
# Add the cloud AWS credentials respectively
[default]
aws_access_key_id = XXXXXXXXXXXXXXXXXXX
aws_secret_access_key = XXXXXXXXXXXXXXX
HCE recommends that you use the same secret name, that is, cloud-secret. Otherwise, you will need to update the AWS_SHARED_CREDENTIALS_FILE environment variable in the fault template with the new secret name and you won't be able to use the default health check probes.
Below is an example AWS policy to execute the fault.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ecs:UpdateContainerInstancesState",
"ecs:RegisterContainerInstance",
"ecs:ListContainerInstances",
"ecs:DeregisterContainerInstance",
"ecs:DescribeContainerInstances",
"ecs:ListTasks",
"ecs:DescribeClusters"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"ssm:GetDocument",
"ssm:DescribeDocument",
"ssm:GetParameter",
"ssm:GetParameters",
"ssm:SendCommand",
"ssm:CancelCommand",
"ssm:CreateDocument",
"ssm:DeleteDocument",
"ssm:GetCommandInvocation",
"ssm:UpdateInstanceInformation",
"ssm:DescribeInstanceInformation"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"ec2messages:AcknowledgeMessage",
"ec2messages:DeleteMessage",
"ec2messages:FailMessage",
"ec2messages:GetEndpoint",
"ec2messages:GetMessages",
"ec2messages:SendReply"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"ec2:DescribeInstances"
],
"Resource": [
"*"
]
}
]
}
- Go to AWS named profile for chaos to use a different profile for AWS faults and the superset permission/policy to execute all AWS faults.
- Go to the common tunables and AWS-specific tunables to tune the common tunables for all faults and AWS-specific tunables.
Mandatory tunables
| Tunable | Description | Notes |
|---|---|---|
| CLUSTER_NAME | Name of the target ECS cluster. | For example, cluster-1. |
| REGION | Region name of the target ECS cluster | For example, us-east-1. |
Optional tunables
| Tunable | Description | Notes |
|---|---|---|
| TOTAL_CHAOS_DURATION | Duration that you specify, through which chaos is injected into the target resource (in seconds). | Default: 30 s. For more information, go to duration of the chaos. |
| CHAOS_INTERVAL | Interval between successive instance terminations (in seconds). | Default: 30 s. For more information, go to chaos interval. |
| AWS_SHARED_CREDENTIALS_FILE | Path to the AWS secret credentials. | Default: /tmp/cloud_config.yml. |
| SERVICE_NAME | Target ECS service name. | For example, app-svc. For more information, go to ECS service name. |
| CPU_CORE | Number of CPU cores to consume. | Default: 0. For more information, go to CPU core. |
| CPU_LOAD | Percentage of the CPU to consume. | Default: 100. For more information, go to CPU load. |
| SEQUENCE | Sequence of chaos execution for multiple instances | Default: parallel. Supports serial and parallel. For more information, go to sequence of chaos execution. |
| RAMP_TIME | Period to wait before and after injecting chaos (in seconds). | For example, 30 s. For more information, go to ramp time. |
CPU cores
Number of cores of the CPU to consume for the target container instances. Tune it by using the CPU_CORE environment variable. When this environment variable is set to 0, all the available CPU resources are consumed.
The following YAML snippet illustrates the use of this environment variable:
# cpu cores for the stress
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: ecs-container-cpu-hog
spec:
components:
env:
# provide the cpu core to be hogged
- name: CPU_CORE
value: '0'
- name: REGION
value: 'us-east-2'
- name: TOTAL_CHAOS_DURATION
VALUE: '60'
CPU load
Percentage of CPU to be consumed for the target container instances. Tune it by using the CPU_LOAD environment variable. When CPU load is set to 100, 100 percent of the CPU core is consumed.
The following YAML snippet illustrates the use of this environment variable:
# cpu load for the stress
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: ecs-container-cpu-hog
spec:
components:
env:
# provide the cpu load percentage
- name: CPU_LOAD
value: '100'
- name: CPU_CORE
value: '0'
- name: TOTAL_CHAOS_DURATION
VALUE: '60'
ECS service name
Service name whose tasks are stopped. Tune it by using the SERVICE_NAME environment variable.
The following YAML snippet illustrates the use of this environment variable:
# stop the tasks of an ECS cluster
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: ecs-task-stop
spec:
components:
env:
# provide the name of ECS cluster
- name: CLUSTER_NAME
value: 'demo'
- name: SERVICE_NAME
vale: 'test-svc'
- name: REGION
value: 'us-east-1'
- name: TOTAL_CHAOS_DURATION
VALUE: '60'