Prometheus
- Prometheus queries must include filters (enclosed in curly braces) to specify the nodes or data points you want to sample.
- Prometheus queries must produce a single value (scalar). To learn more about Prometheus queries, go to QUERYING PROMETHEUS.
- The Prometheus connector and health source provided by Harness are compatible with Mimir, Cortex, Thanos, Coralogix, and VictoriaMetrics platforms.
Before you begin
This page assumes you have followed the rest of the steps to set up CV. To learn more, go to Configure CV
Add Prometheus as a health source
This option is available only if you have configured the service and environment as fixed values.
A Health Source is basically a mapping of a Harness Service to the service in a deployment environment monitored by an APM or logging tool.
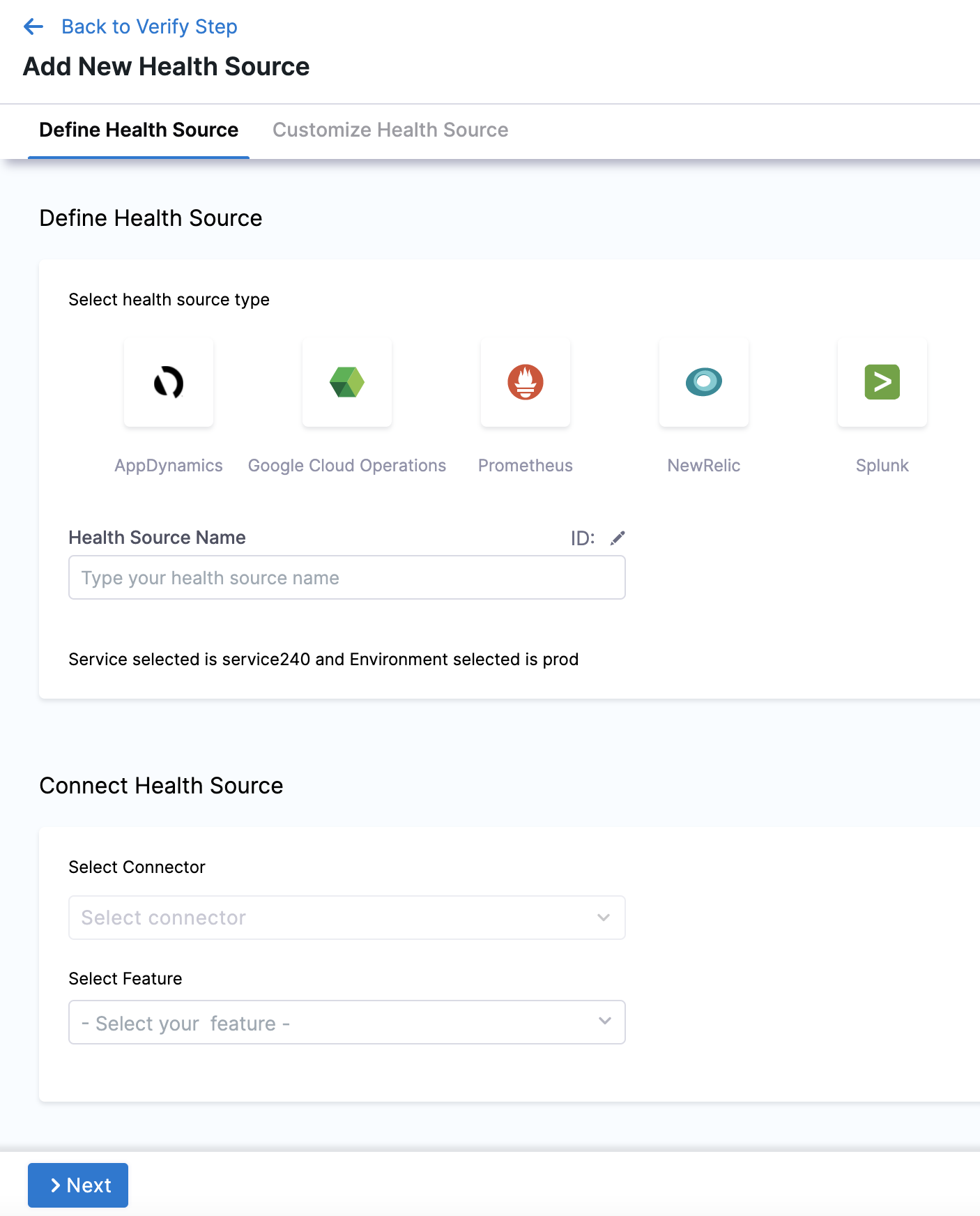
In Health Sources, click Add. The Add New Health Source settings appear.
-
In Select health source type, select Prometheus.
-
In Health Source Name, enter a name for the Health Source.
-
Under Connect Health Source, click Select Connector.
-
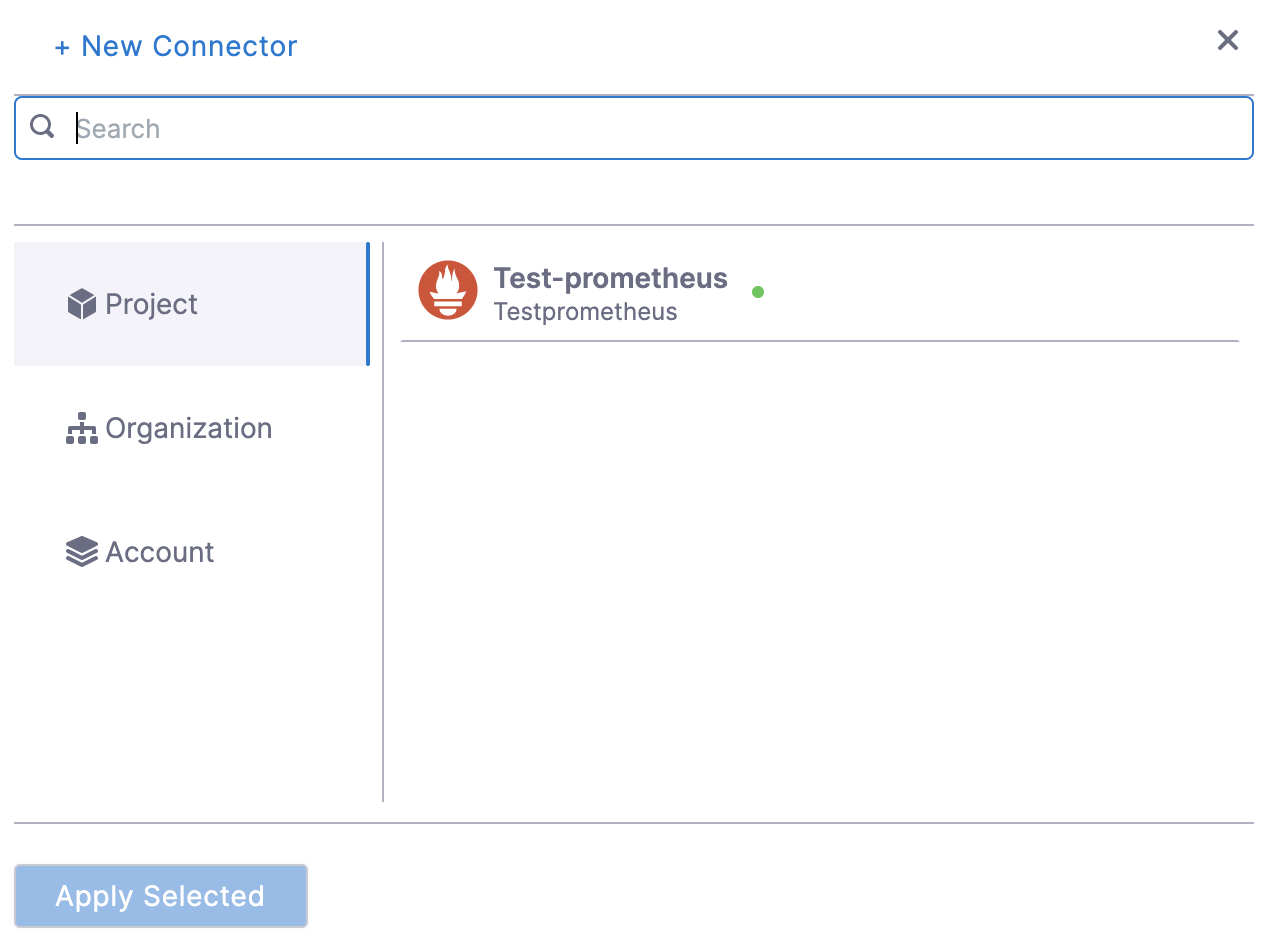
In Connector settings, you can either choose an existing connector or click New Connector.
-
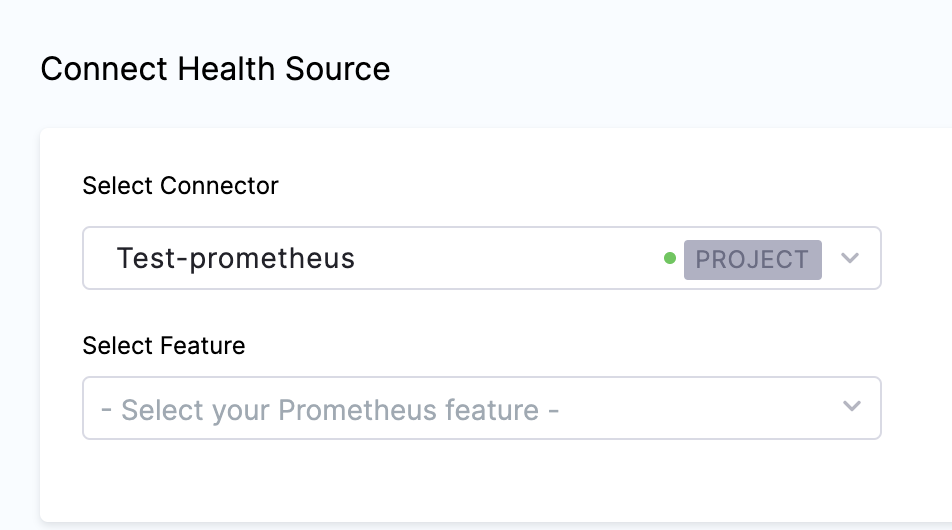
After selecting the connector, click Apply Selected. The Connector is added to the Health Source.
-
In Select Feature, select the Prometheus feature to be used.
-
Click Next. The Customize Health Source settings appear.
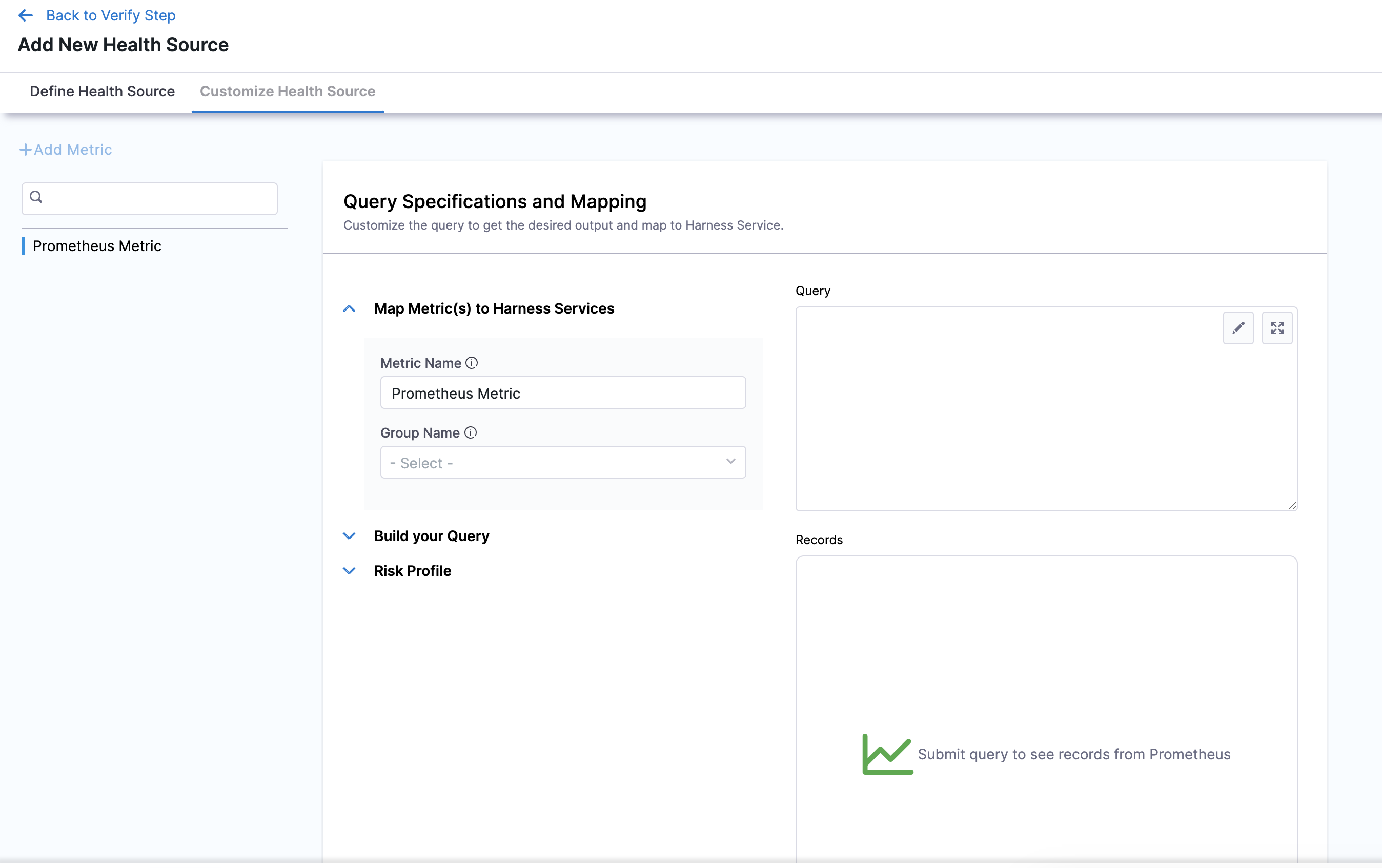
The subsequent settings in Customize Health Source depend on the Health Source Type you selected. You can customize the metrics to map the Harness Service to the monitored environment.
-
In Query Specifications and Mapping, first click Map Metric(s) to Harness Services.
-
Enter the desired metric name in Metric Name.
-
Enter a name for the Prometheus group in Group Name.
-
Click Build your Query drop down.
-
In Prometheus Metric, select the Prometheus metric.
-
In Filter on Environment, select a filter.
-
In Filter on Service, select a filter. To add more filters, click Additional Filter which is optional.
-
To add an aggregator for the metric, click Aggregator which is also optional.
-
In Assign, you can select the services for which you want to apply the metric.
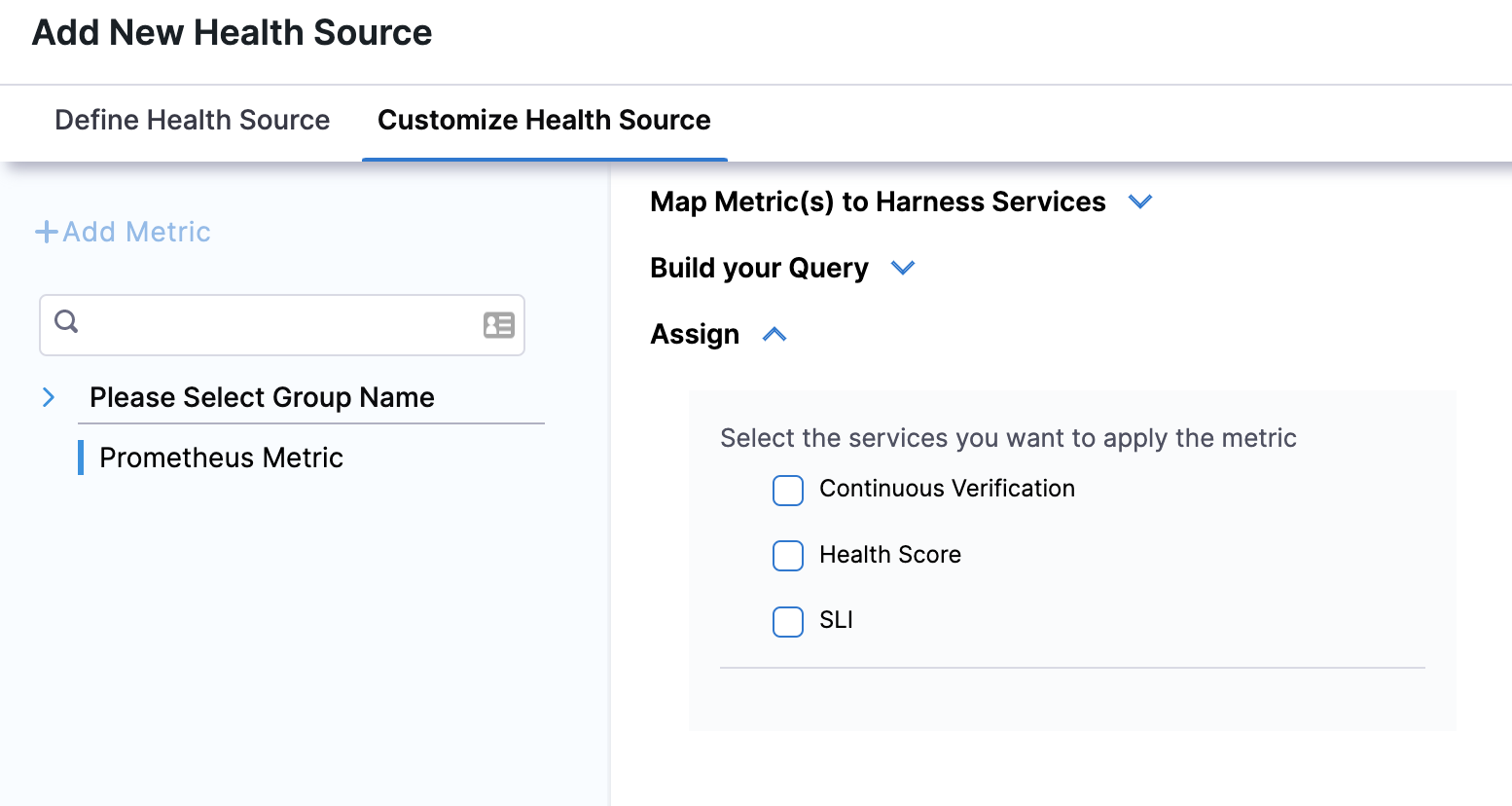
-
Click Submit. The Health Source is displayed in the AI Verify (v1) step.
You can add one or more Health Sources for each APM or logging provider.
Add Amazon Managed Service for Prometheus as health source
Harness now supports Amazon Managed Service for Prometheus as health source. To select Amazon Managed Service for Prometheus as health source:
-
In Health Sources, click Add.
The Add New Health Source settings appear. -
In Select health source type, select Prometheus.
-
In Health Source Name, enter a name for the Health Source.
-
Under Connect Health Source > Via Cloud Provider, select Amazon web services.
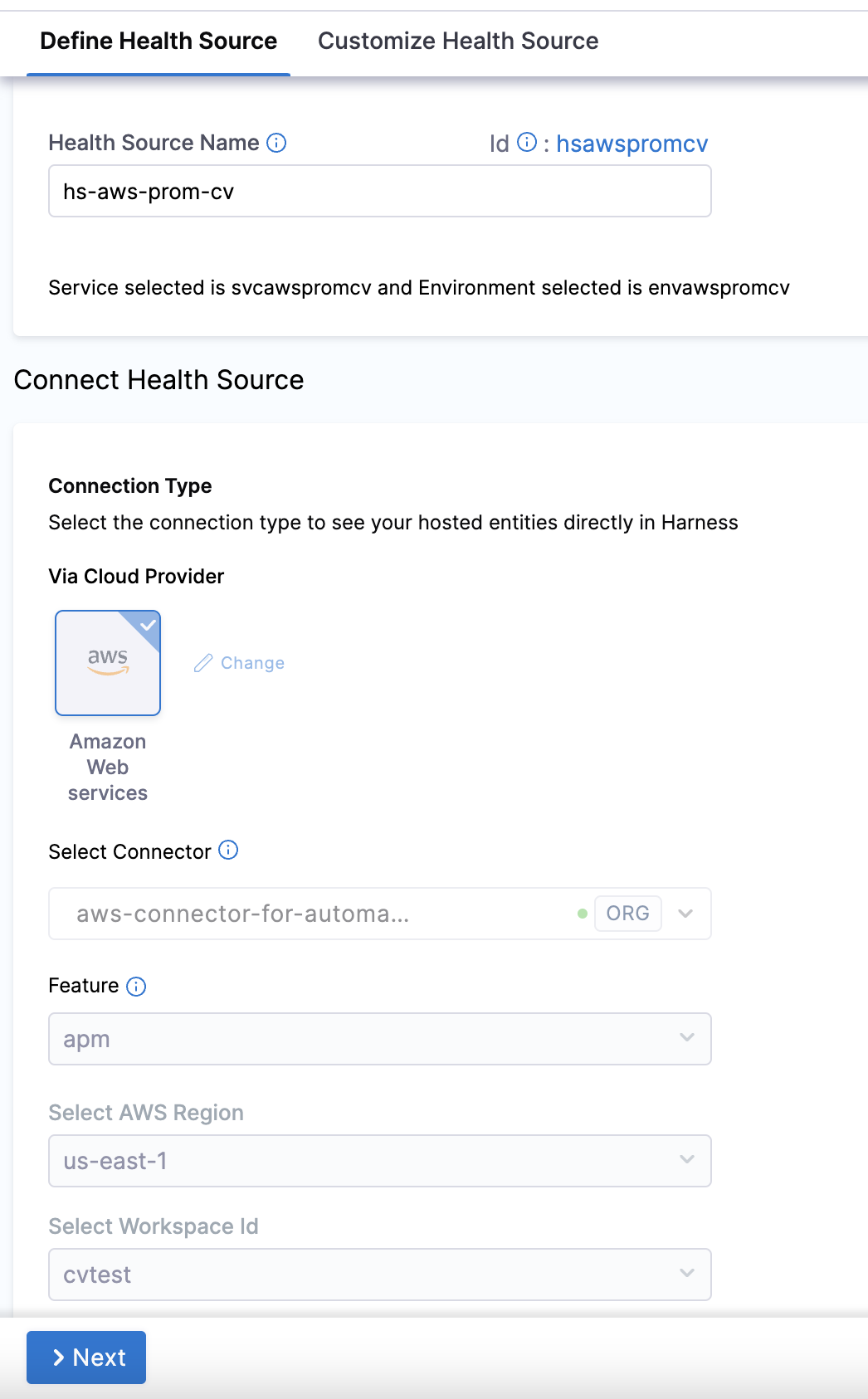
-
Under Connect Health Source, click Select Connector.
-
In Connector settings, you can either choose an existing connector or click New Connector.
-
In the Select Feature field, select the Prometheus feature that you want to use.
-
In the Select AWS Region field, select the appropriate region.
-
In the Select Workplace Id field, select the appropriate workplace id.
-
Click Next. The Customize Health Source settings appear.
You can customize the metrics to map the Harness Service to the monitored environment in Query Specifications and Mapping settings.The subsequent settings in Customize Health Source depend on the Health Source Type you selected. Click Map Queries to Harness Services drop down.
-
Click Add Metric.
-
Enter a name for the query in Name your Query.
-
Click Select Query to select a saved query. This is an optional step. You can also enter the query manually in the Query field.
-
Click Fetch Records to retrieve the details. The results are displayed under Records.
Commonly used Prometheus queries
Performance
- P90:
histogram_quantile(0.90, sum(rate(flask_http_request_duration_seconds_bucket{datacenter="preprod", status=~"2.*", pod=~"harness-dummy-.*"}[5m])) by (le)) - P50:
histogram_quantile(0.50, sum(rate(flask_http_request_duration_seconds_bucket{datacenter="preprod", status=~"2.*", pod=~"harness-dummy-.*"}[5m])) by (le))
API
- 5xx response:
sum(rate(flask_http_request_total{datacenter="preprod", status=~"5.*", pod=~"harness-dummy-.*"})) by (le) - 4xx response:
sum(rate(flask_http_request_total{datacenter="preprod", status=~"4.*", pod=~"harness-dummy-.*"})) by (le)
Infrastructure
- CPU:
(sum(rate(container_cpu_usage_seconds_total{namespace="<namespace_name>",pod=~"dummy-.*",source_cluster="<cluster_name>",image!='',container!='POD'}[1m])) by (le) / sum(kube_pod_container_resource_requests_cpu_cores{}) by (le)) * 100 - Memory:
(sum(container_memory_usage_bytes{namespace="<namespace_name>",pod=~"harness-dummy-.*",source_cluster="<cluster_name>", container!="POD", container!=""}) by (le) / sum(kube_pod_container_resource_requests_memory_bytes{}) by (le)) * 100