Create environments
Environments represent your deployment targets (QA, Prod, etc). Each environment contains one or more Infrastructure Definitions that list your target clusters, hosts, namespaces, etc.
Create an environment
You can create environments from:
- Within a pipeline
- Outside a pipeline
- An account
- An Organization
- Within a pipeline
- Outside a pipeline
- From organization or account
To create an environment from inside of a pipeline, select New Environment in the Infrastructure tab of a new CD stage.
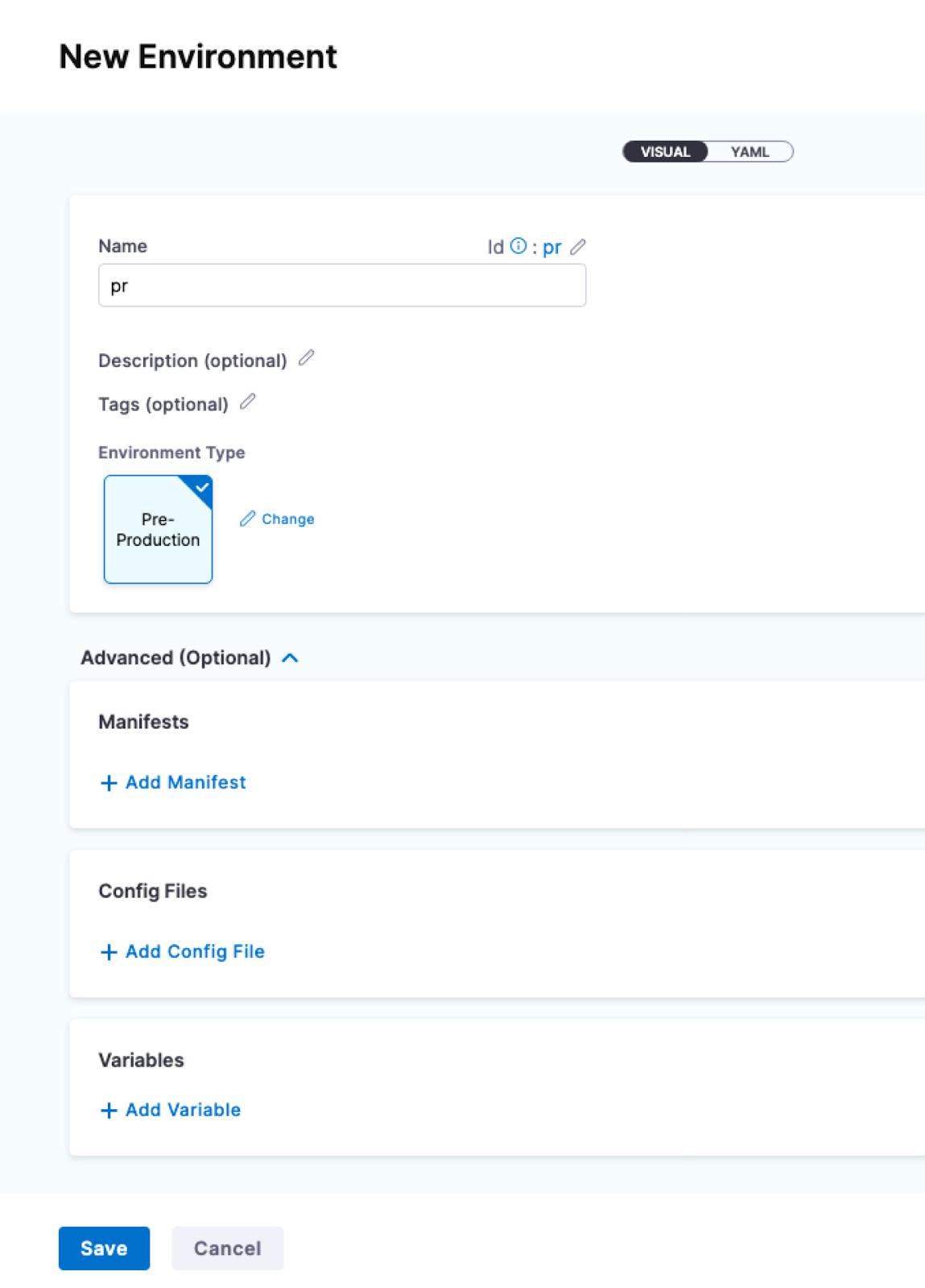
To create an Environment from outside of a pipeline, you use Environments in the navigation pane.

You can create an environment and provide infrastructure definitions at an account or organization level from the Harness UI, using APIs or Terraform.
- Pipeline Studio
- API
- Terraform
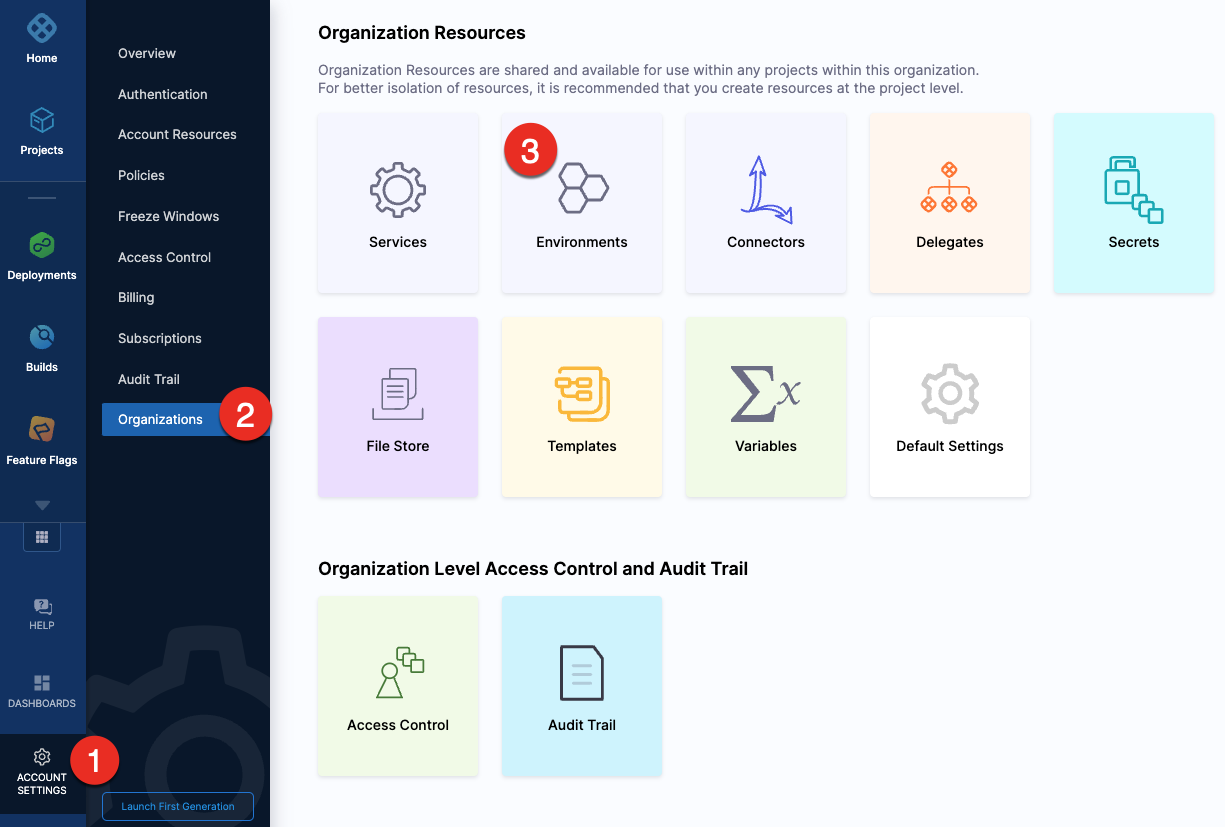
To create an environment at an account or organization level, go to Organization Resources >Environments.
Expand the section below to see a sample account level environment YAML.Account level environment YAML
Expand the section below to see a sample account level infrastructure definition YAML.Account level infrastructure definition YAML
Expand the section below to see a sample organization level environment YAML.Organization level environment YAML
Expand the section below to see a sample organization level infrastructure definition YAML.Organization level infrastructure definition YAML
For information about creating an environment API, go to create an environment.
For information about creating infrastructure definition API, go to create an infrastructure in an environment.
The orgIdentifier and projectIdentifier field definitions are optional, and depend on where you want to create the environment. For example, if you create an environment at an account level, you will not need org or project identifiers in the post API call payload.
For information about creating a Harness platform environment, go to harness_platform_environment (Resource).
Expand the section below to see a sample platform environment in Terraform.Harness platform environment
For information about creating a Harness platform infrastructure definition, go to harness_platform_infrastructure (Resource).
Expand the section below to see a sample platform infrastructure definition in Terraform.Harness platform infrastructure definition
The org_id and project_id field definitions are optional, and depend on where you want to create the environment. For example, if you create an environment at an account level, you will not need org or project identifiers.
Define the environment configuration
In the environment Configuration, you can manage the Name, Description, Tags, and Environment Type of the environment.
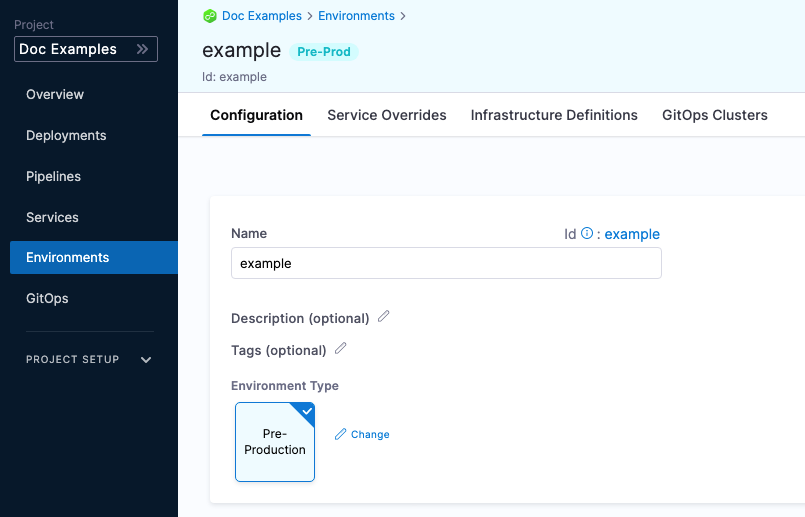
You can also set default manifests, specifications, config files, and variables to use whenever Harness deploys a service to this environment.
For example, a stage has a Kubernetes service with a manifest but whenever that service is deployed to the QA environment, the manifest in that environment's Configuration overwrites the namespace of with the manifest in the service with QA.
Create service overrides
Service overrides are different from Environment Configuration in the following ways:
- Environment Configuration: applies to every service that is used with the environment.
- Environment Service Overrides: applies to specific services you select. Whenever that service is used with that environment, the Service Override is applied.
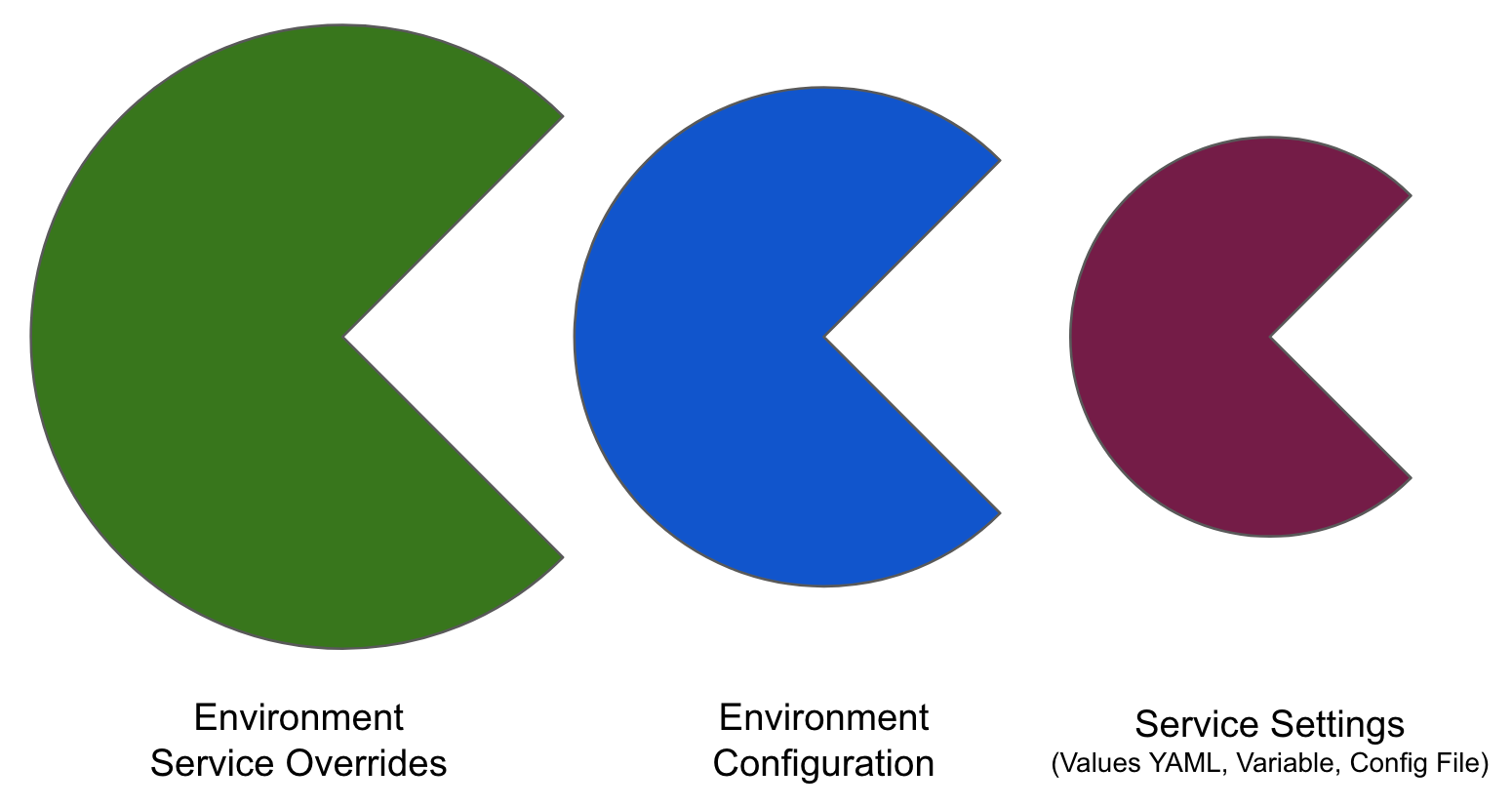
Override priority
When you are using environment configuration and service override to override service settings, it's important to understand the priority of the overrides.
The priority from top to bottom is:
- Environment service overrides
- Environment configuration
- Service settings
Overriding values.yaml
You can specify values YAML files at the environment's Service Overrides and Configuration, and the service itself.
Here is an example of specifying it at the environment's Configuration:
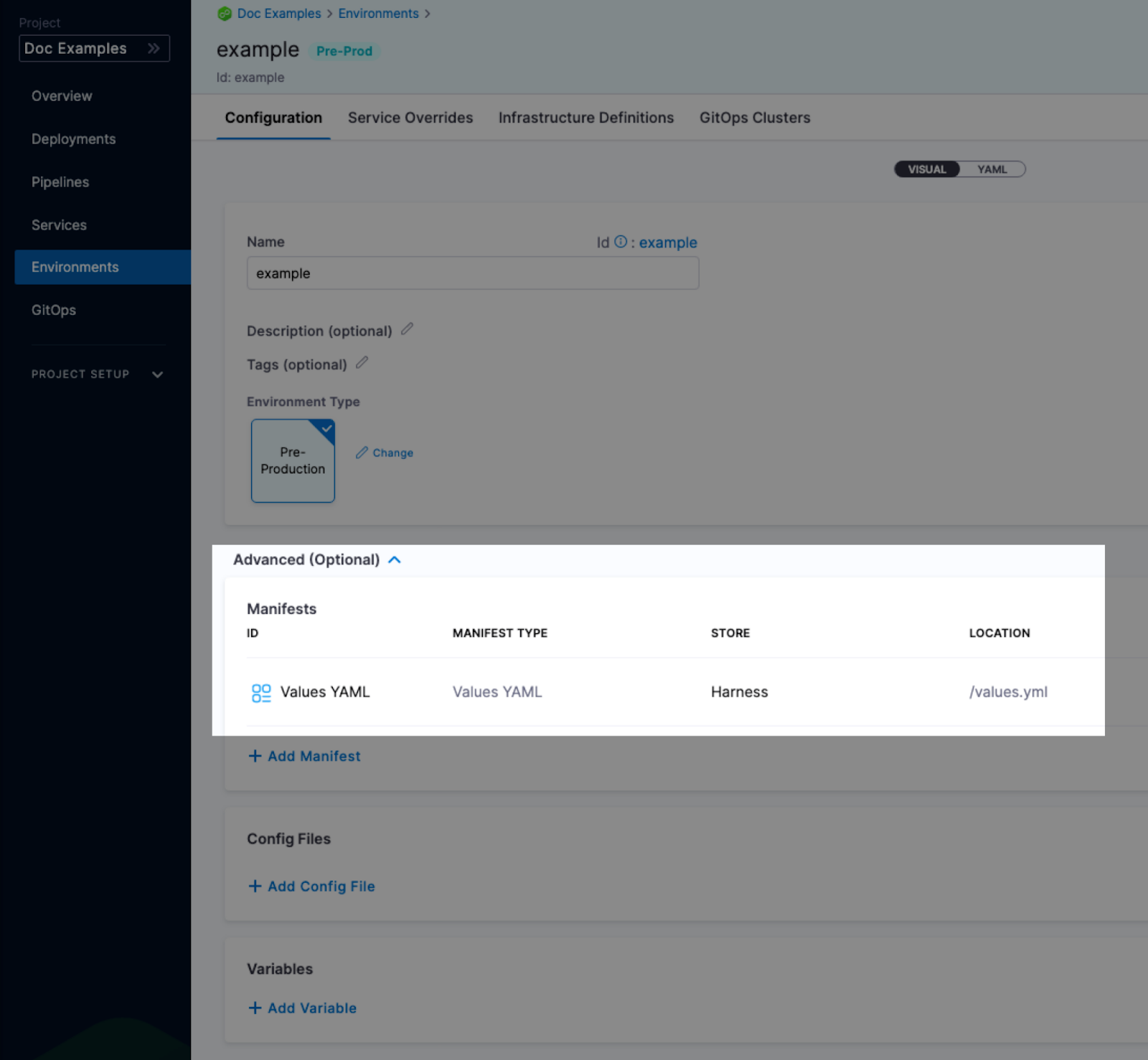
When you have a values yaml file at two or more of the environment Service Overrides, Environment Configuration, and the service itself, Harness merges the files into a single values YAML for deployment. This merging is performed at pipeline execution runtime.
Overriding occurs when the higher priority setting has the same name:value pair as a lower priority setting.
Let's look at two examples.
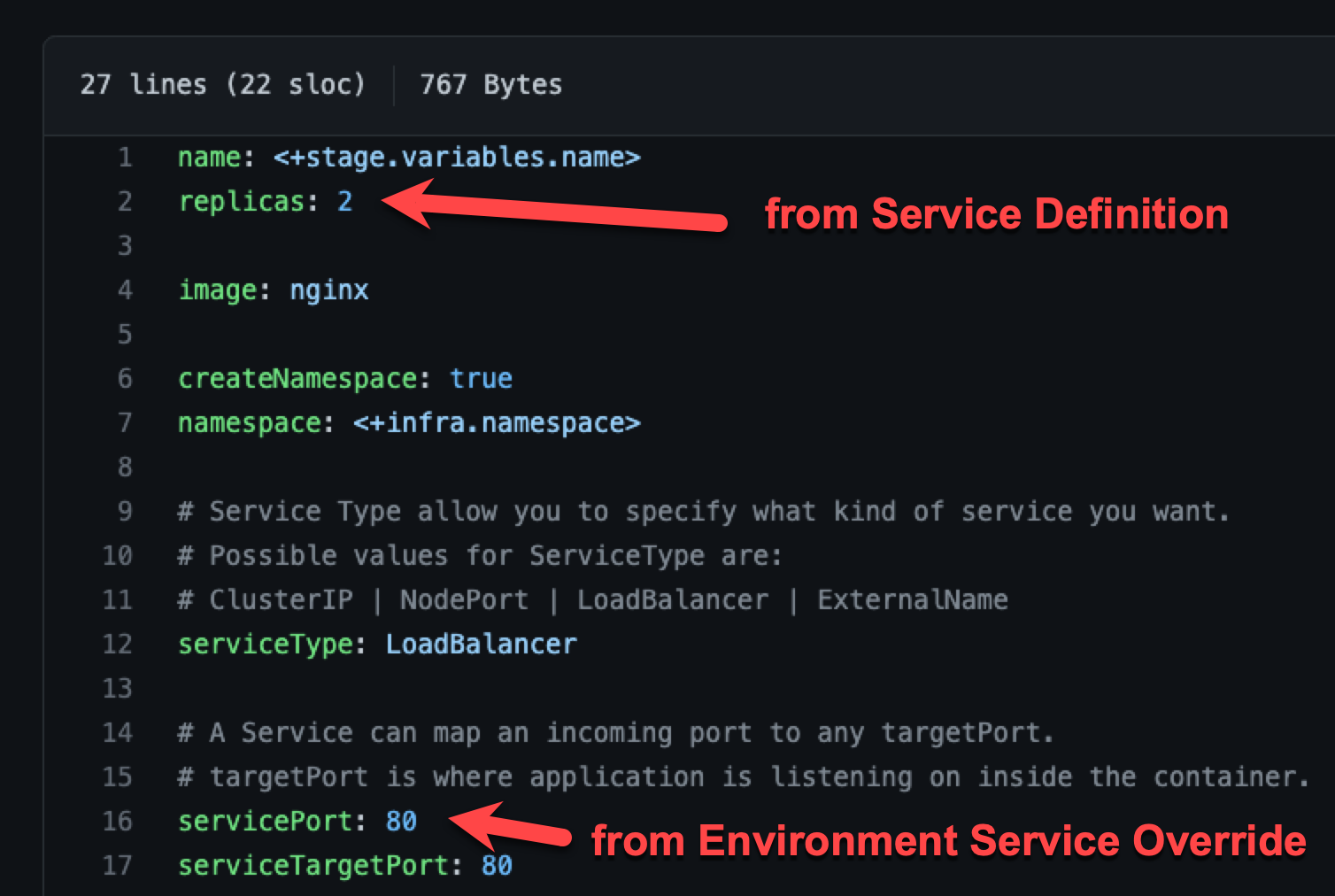
Merging values.yaml name:value pairs
An environment's Service Overrides values YAML has the name:value pair servicePort: 80 but no replicas name:value.
A service's Service Definition has a values YAML with replicas: 2 but no servicePort name:value.
At runtime, the two values YAML files are merged into one.
The servicePort: 80 from the environment Service Overrides values YAML is merged with the Service Definition's replicas: 2 in the values YAML:
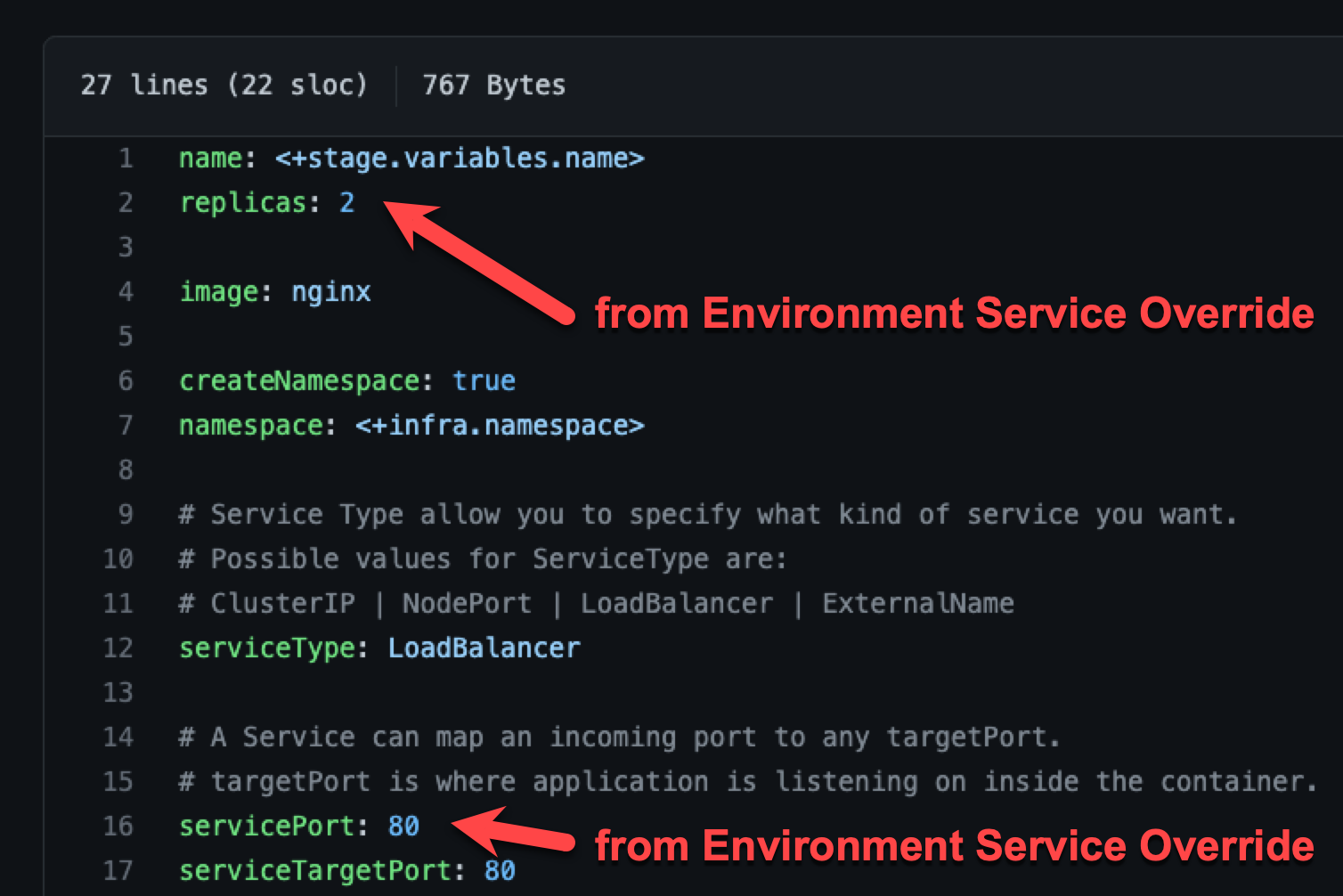
Fully overriding values.yaml name:value pairs
An environment's Service Overrides values YAML has the name:value pairs replicas: 2 and servicePort: 80.
A service's Service Definition has a values YAML with replicas: 4 and servicePort: 8080.
At runtime, the name:value pairs from the environment Service Overrides values YAML fully override the service values YAML. The replicas: 2 and servicePort: 80 from the environment Service Overrides are used.
Fully overriding config files and variables
Config files are a black box that can contain multiple formats and content, such as YAML, JSON, plain text, etc. Consequently, they cannot be overridden like Values YAML files.
Variables cannot be partially overridden either. They are completely replaced.
When you have Config files at two or more of the environment Service Overrides, Configuration, and the service itself, the standard override priority is applied.
When you have Variables with the same name at two or more of the environment Service Overrides, Configuration, and the service itself, the standard override priority is applied.
Add infrastructure definitions
Infrastructure definitions represent an environment's infrastructures physically. They are the actual clusters, hosts, namespaces, etc, where you are deploying a service.
An environment can have multiple Infrastructure Definitions.
When you select an environment in a stage, you can select the Infrastructure Definition to use for that stage.
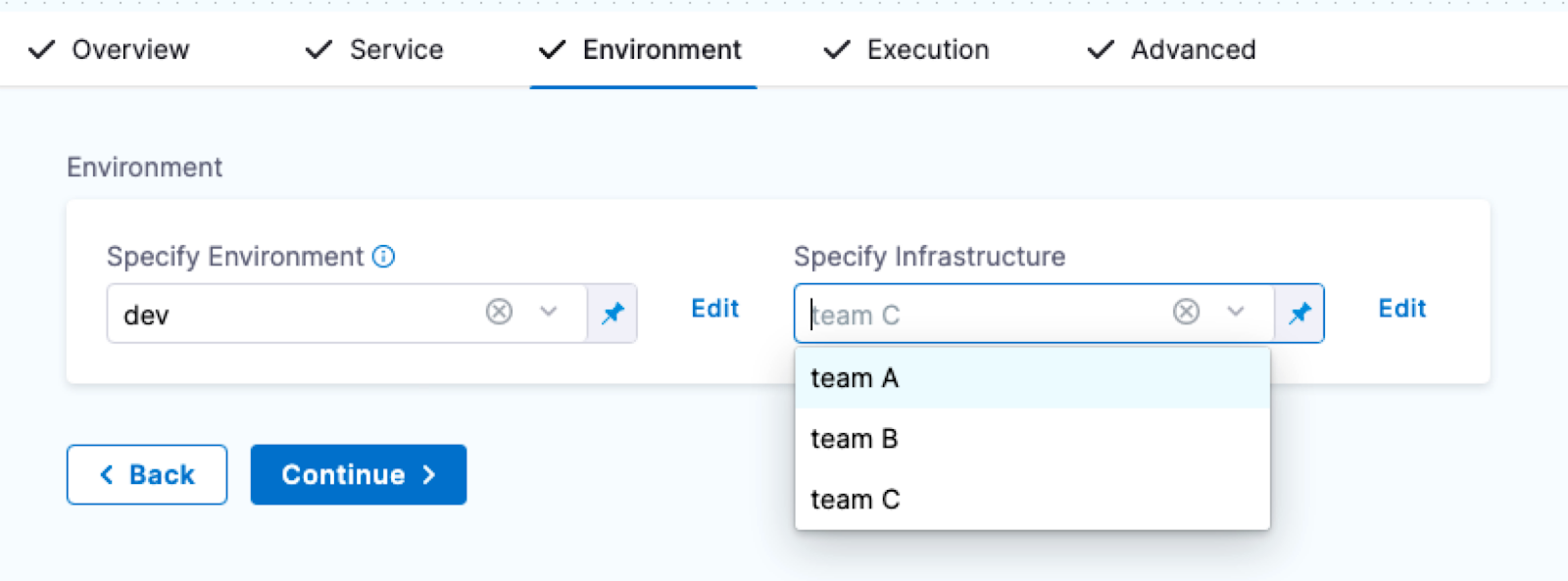
Propagating environments through multiple stages
When modeling multiple Deploy stages in a pipeline, you can propagate the environment and infrastructure definition selected in one stage to one or more subsequent stages.
When you propagate an environment, you can either use the same infrastructure definition that was used in the parent stage or you can select a different infrastructure definition.
You can also propagate services between stages. For more information, go to Propagate CD services.
Important notes
-
Propagation is only supported for Deploy stages. Custom stages do not have environments.
-
You cannot propagate environments between different deployment types. For example, you cannot propagate a Kubernetes environment between a Kubernetes deployment stage and a Shell Script deployment stage.
-
Environment propagation is not supported when using multiple environments in a single stage (multi environment deployments).
-
Environment propagation is progressive. You can only propagate environments from stage to stage in a forward direction in your pipeline. For example, Stage 2 cannot propagate an environment from a subsequent Stage 3.
-
In a pipeline's Advanced Options, in Stage Execution Settings, you can set up selective stage executions. This allows you to select which stages to deploy at runtime.
- If you select a stage that uses a propagated environment (a child environment), that stage will not work. This is because the parent environment's settings must be resolved as part of the deployment.
-
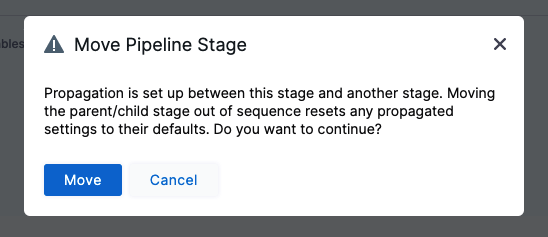
When propagation is set up between a parent stage and child stage, moving the parent or child stage out of sequence resets any propagated settings to their defaults. If you do this, you are prompted to confirm. If you confirm, the stages are reset to their defaults.
-
You cannot propagate environment from a stage which also propagates environment from another stage.
Propagate an environment
-
Open a pipeline that contains at least one Deploy stage.
-
Add a subsequent Deploy stage.
-
In Service, select a service for the stage, and then select Continue.
-
In Environment, select Propagate Environment From.
-
In Propagate Environment From, select the environment of a previous stage.
The environment and infrastructure definition from the previous stage is now configured in this stage.

Select a different infrastructure when propagating environment from a previous stage
When you propagate an environment from a previous stage, you have the option to select a different infrastructure definition.
-
Select a stage for which you want to propagate the environment and infrastructure. Make sure that the selected stage has at least one previous Deploy stage.
-
In the Environment tab, select Propagate Environment From and select the environment of a previous stage.
-
Select Deploy to Different Infrastructure and select an infrastructure. This option allows you to select a different infrastructure definition.
-
Select + New Infrastructure to create a new infrastructure definition for use in your stage.

- Harness doesn't support nested propagation. For example, if Stage 2 is propagated from Stage 1, you cannot propagate Stage 3 from Stage 2.
- This feature is not supported when deploying to multiple environments or infrastructures.
Here's a sample YAML snipped when a different infrastructure definition is propagated:
environment:
useFromStage:
stage: s1
infrastructureDefinitions:
- identifier: infra_1
inputs:
identifier: infra_1
type: KubernetesDirect
spec:
connectorRef: <+input>
Define GitOps clusters
When you use Harness GitOps you can add GitOps clusters to an environment.
To learn more about Harness GitOps, go to Harness GitOps basics.
Next, when you create a pipeline, you can select the environment and the GitOps cluster(s) to use.
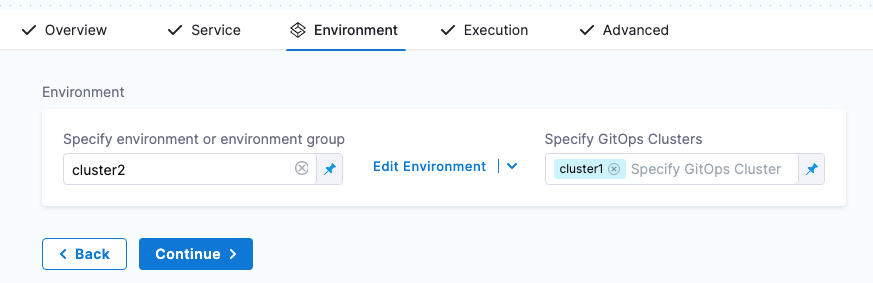
GitOps clusters are used in a PR pipeline. A PR pipeline creates and merges a Git PR on the config.json for a destination cluster as part of an ApplicationSet. The PR Pipeline runs, merges a change to the config.json, and a GitOps sync on the ApplicationSet is initiated.
GitOps Clusters are not used in standard CD pipelines. They're used when using GitOps only.
Clone Environments
You can clone environment across scopes (i.e from one project to another, project to organization, account to project etc.).
Select More Options.
Select Clone
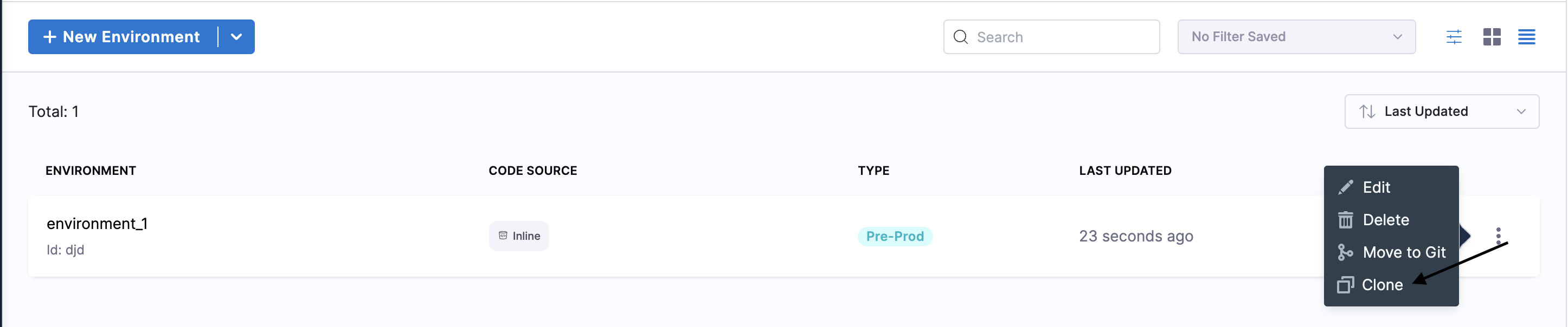
Once you click on Clone, you will see the Clone Environment setting:
You can change the Name, and add tags, or descriptions for this clone environment.
You can modify the destination of your clone environment using the Organization and Project fields.
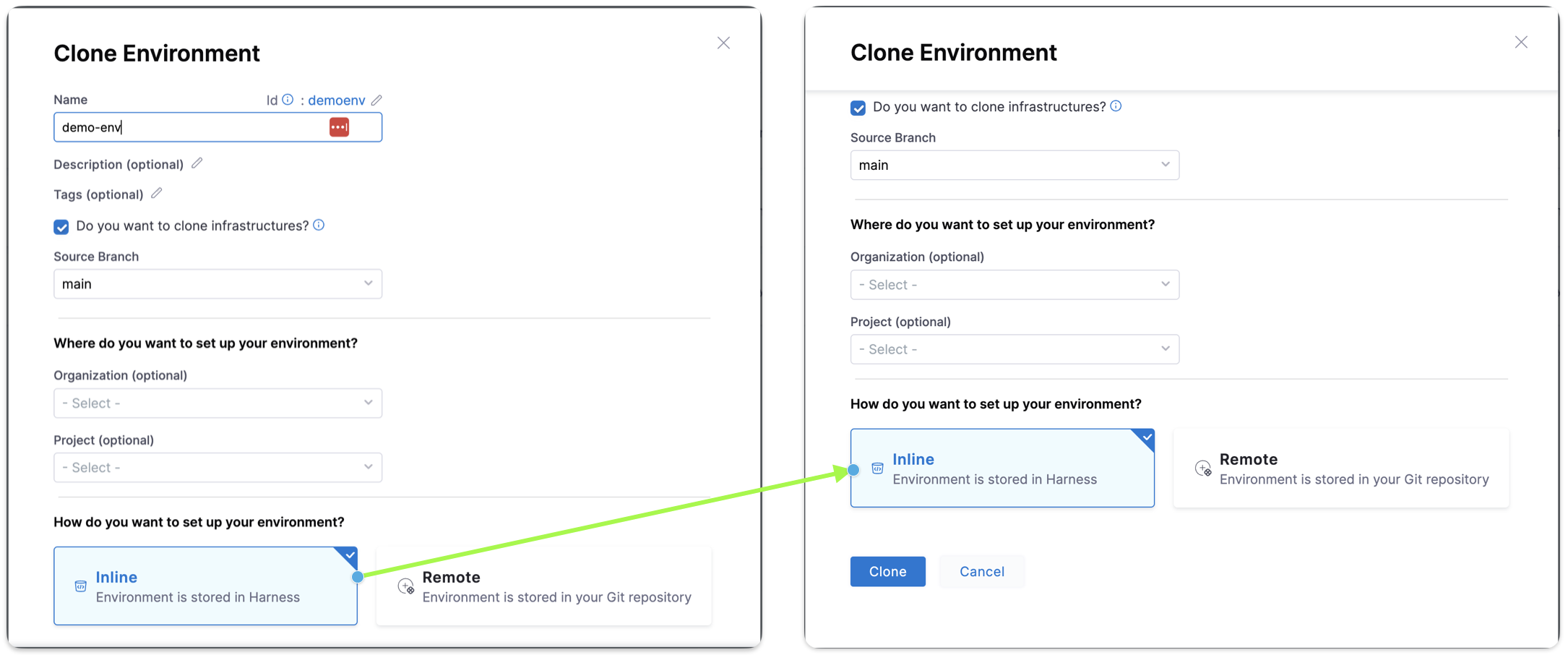
The checkbox Do you want to clone infrastructures? is checked by default. The infrastructures in the environment will be cloned as inline by default, regardless of the destination being remote or inline environment. Uncheck the checkbox if you do not want to clone all the infrastructures in the environment.
You can choose between Inline and Remote to set up your environment. Choose Inline when you want your environments to be stored in Harness. Choose Remote when storing your environment in a Third-party Git repository or Harness Code Repository.
To clone a remote environment to an inline environment, you have to specify the source branch where the remote environment is stored.
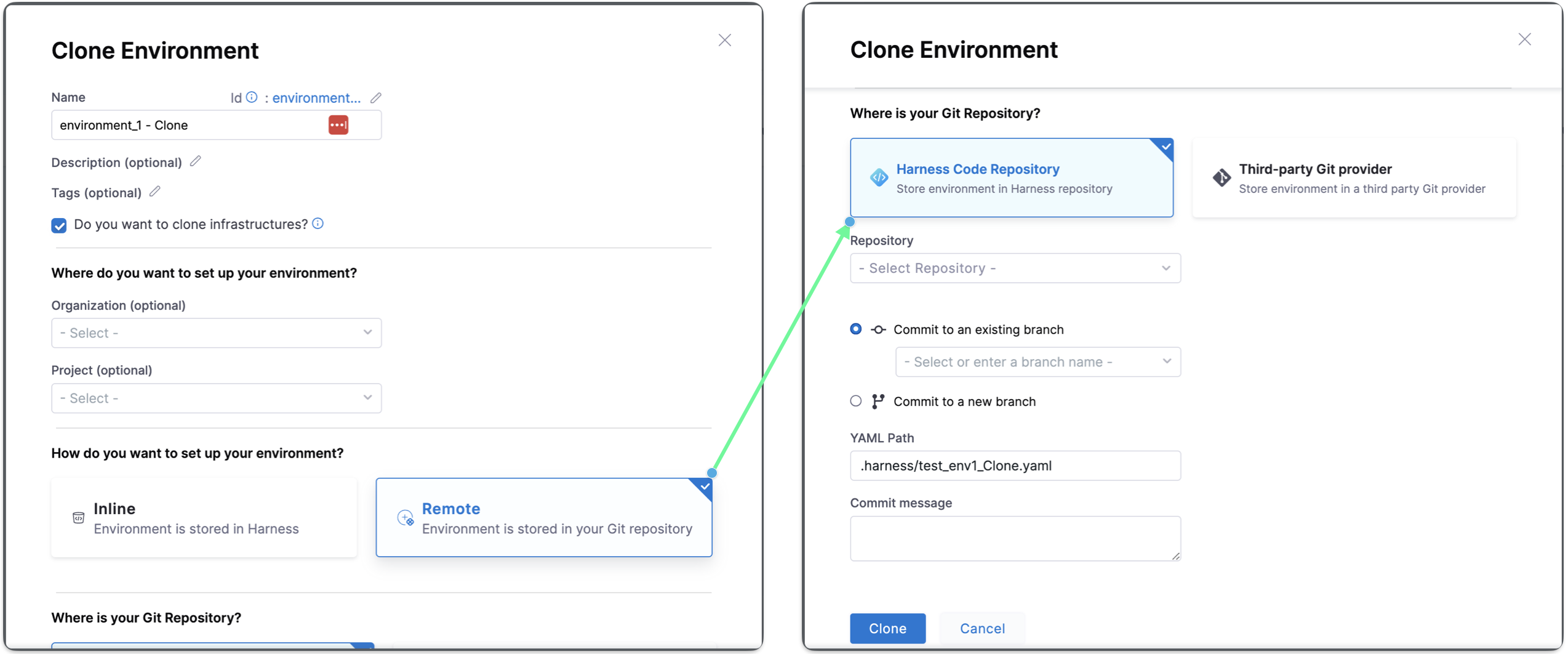
To clone an inline environment or remote environment to a remote environment, you must specify the target repository, Harness Code Repository, to store the environment in the Harness repository or Third-party Git provider, to store the environment in a third party Git provider, define the Git Connector if Third-party Git provider. Specify the Repository name, the YAML path, and the commit message.
When you clone an environment from a different organization or project, the connector referenced in the infrastructure doesn't get cloned and must be explicitly created.
Runtime inputs and expressions in environments
If you use runtime inputs in your environments, you will need to provide values for these when they run pipeline using these environments.
If you use expressions in your environments, Harness must be able to resolve these expressions when users run pipeline using these environments.
Select Runtime input for the environment.
When you run the pipeline, you can select the environment for their runtime inputs.
For more information on runtime inputs and expressions, go to fixed values, runtime inputs, and expressions.