Data Sources
Harness IDP allows you to integrate various data sources to collect specific data points for each software component. Once a data source is enabled, you can use it to create checks for your scorecards.
Data Sources are third-party providers that supply specific types of data for software components. Examples include GitHub, GitLab, Bitbucket, Harness, PagerDuty, Jira, and Kubernetes. Data Points are the specific pieces of information that each data source provides for a software component. Data points can be numbers, strings, or booleans.
A Data Sources tab is available on the Scorecards page where you can view all supported data sources and their corresponding data points.
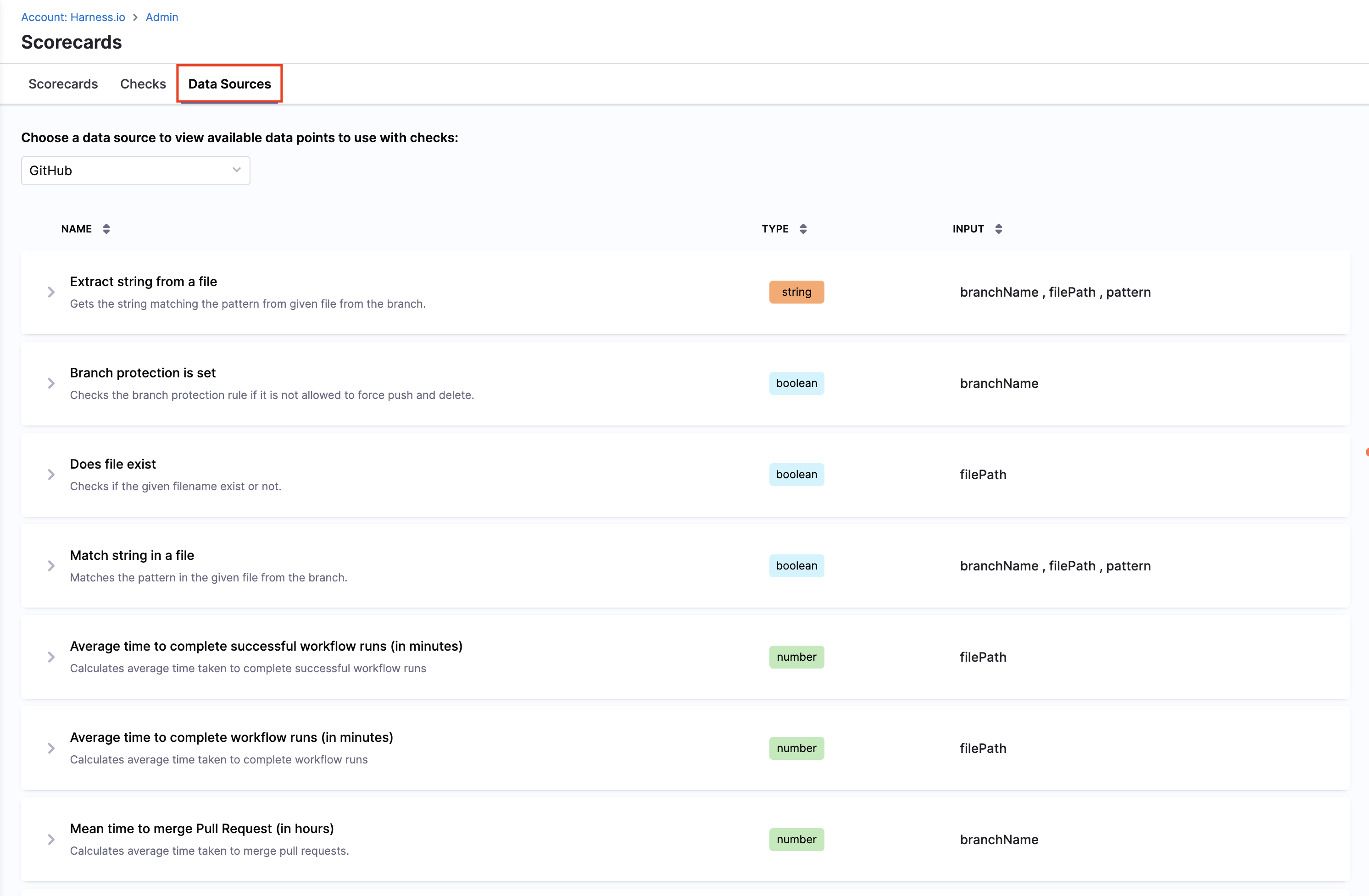
Data sources
GitHub
The following data points are available for the GitHub data source.
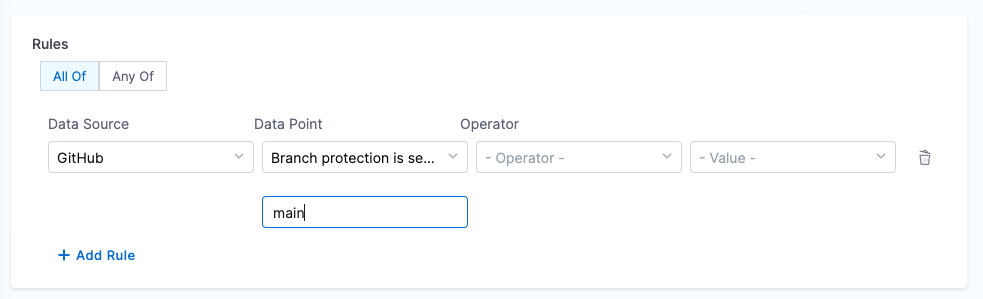
1. Branch protection
Objective: Ensure that branch protection rules disallow force push and delete.
Calculation Method: Fetches the backstage.io/source-location annotation from the catalog YAML file to find repository details and verify the branch protection rules.
Prerequisites:
- GitHub Connector with Admin access
- Provide suitable
backstage.io/source-locationannotation if the catalog YAML file is present outside the source GitHub repository
Example YAML:
kind: "Component"
apiVersion: "backstage.io/v1alpha1"
metadata:
name: order-service
annotations:
backstage.io/source-location: 'url:https://github.com/kubernetes/kubernetes/tree/master'
...
spec:
...
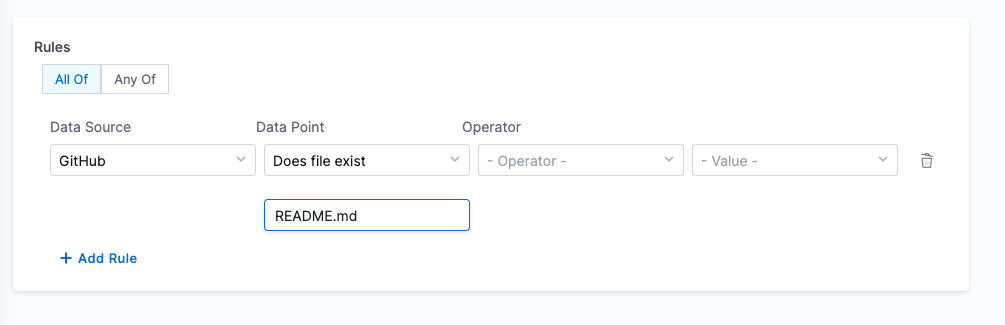
2. File existence
Objective: Verify the existence of a specified file in the repository.
Calculation Method: Uses the backstage.io/source-location annotation to locate the repository and check for the file's presence. Make sure to mention the filename with extension or relative path from the root folder (e.g., README.md or docs/README.md) in the conditional input field.
Prerequisites: Provide suitable backstage.io/source-location annotation if the catalog YAML file is present outside the source GitHub repository.
Example YAML:
kind: "Component"
apiVersion: "backstage.io/v1alpha1"
metadata:
name: order-service
annotations:
backstage.io/source-location: 'url:https://github.com/kubernetes/kubernetes/tree/master'
...
spec:
...
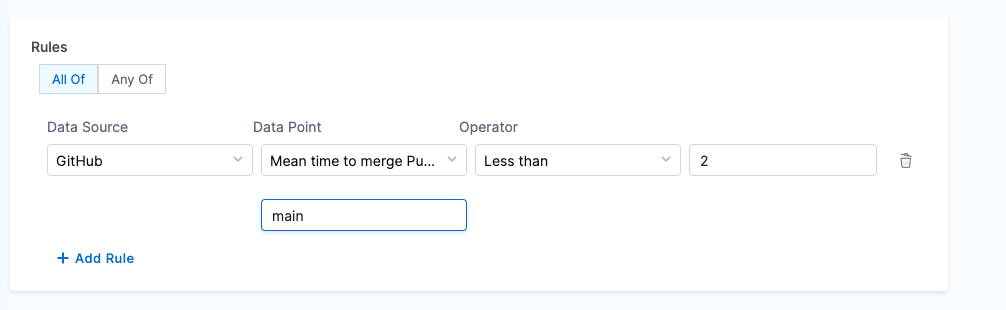
3. Mean time to merge pull request
Objective: Calculate the average time taken to merge the last 100 pull requests.
Calculation Method: Retrieves repository details using backstage.io/source-location and calculates the average merge time.
Prerequisites:
- Provide suitable
backstage.io/source-locationannotation if the catalog YAML file is present outside the source GitHub repository - Make sure to mention the branch name in the conditional input field
Example YAML:
kind: "Component"
apiVersion: "backstage.io/v1alpha1"
metadata:
name: order-service
annotations:
backstage.io/source-location: 'url:https://github.com/kubernetes/kubernetes/tree/master'
...
spec:
...
4. Average time to complete successful workflow runs (in minutes)
Objective: Calculate the average time taken to complete successful workflow runs (in minutes).
Calculation Method: Fetches backstage.io/source-location annotation from catalog YAML file to find repository details and calculates the average time for the last 100 successful workflow runs to complete.
Prerequisites:
- Provide suitable
backstage.io/source-locationannotation if the catalog YAML file is present outside the source GitHub repository - Make sure to mention the workflow ID or filename in the conditional input field
5. Average time to complete workflow runs (in minutes)
Objective: Calculate the average time taken to complete workflow runs (in minutes).
Calculation Method: Fetches backstage.io/source-location annotation from catalog YAML file to find repository details and calculates the average time for the last 100 workflow runs to complete.
Prerequisites:
- Provide suitable
backstage.io/source-locationannotation if the catalog YAML file is present outside the source GitHub repository - Make sure to mention the workflow ID or filename in the conditional input field
6. Workflow success rate
Objective: Calculates success rate for the given workflow.
Calculation Method: Fetches backstage.io/source-location annotation from catalog YAML file to find repository details and calculates the success rate for the workflow.
Prerequisites:
- Provide suitable
backstage.io/source-locationannotation if the catalog YAML file is present outside the source GitHub repository - Make sure to mention the workflow ID or filename in the conditional input field
7. Workflows count
Objective: Calculates total number of workflows.
Calculation Method: Fetches backstage.io/source-location annotation from catalog YAML file to find repository details and calculates the total number of workflows.
Prerequisites: Provide suitable backstage.io/source-location annotation if the catalog YAML file is present outside the source GitHub repository.
8. Open code scanning alerts
Objective: Calculates the total number of open alerts reported in code scanning for the given severity.
Calculation Method: Fetches backstage.io/source-location annotation from catalog YAML file to find repository details and calculates the total number of open alerts reported in code scanning.
Prerequisites:
- GitHub Connector with read access for code scanning alerts
- Provide suitable
backstage.io/source-locationannotation if the catalog YAML file is present outside the source GitHub repository - Make sure to mention the severity type in the conditional input field
9. Open dependabot alerts
Objective: Calculates the total number of open alerts reported by Dependabot for the given severity.
Calculation Method: Fetches backstage.io/source-location annotation from catalog YAML file to find repository details and calculates the total number of open alerts reported by Dependabot.
Prerequisites:
- Provide suitable
backstage.io/source-locationannotation if the catalog YAML file is present outside the source GitHub repository - Make sure to mention the severity type in the conditional input field
10. Open secret scanning alerts
Objective: Calculates the total number of open alerts reported in secret scanning.
Calculation Method: Fetches backstage.io/source-location annotation from catalog YAML file to find repository details and calculates the total number of open alerts reported in secret scanning.
Prerequisites:
- GitHub Connector with read access for secret scanning alerts
- Provide suitable
backstage.io/source-locationannotation if the catalog YAML file is present outside the source GitHub repository
11. Open pull requests by Account
Objective: Calculates the total number of open pull requests raised by the given account.
Calculation Method: Fetches backstage.io/source-location annotation from catalog YAML file to find repository details and calculates the total number of open pull requests raised by account.
Prerequisites:
- Provide suitable
backstage.io/source-locationannotation if the catalog YAML file is present outside the source GitHub repository - Make sure to mention the username in the conditional input field
12. Extract string from a file
Objective: Gets the string matching the pattern from given file from the branch.
Calculation Method: If a branch name is specified, it is utilized. However, if no branch name is provided, the system retrieves information from the catalog YAML file using the backstage.io/source-location annotation to determine the branch name and repository details. It is essential to specify the filename with its extension or provide the relative path from the root folder (e.g., README.md or docs/README.md) in the conditional input field. The filename can also be provided as a regex pattern. For example, for a file path /backstage/blob/master/scripts/log-20240105.anyextension, the regex would be /backstage/blob/master/scripts/log-20240105\..*. After fetching the file, the designated pattern is then searched within the file contents, and its value is extracted and returned.
URL priority for branch name field
In some data points, we take branchName as input. It is an optional field if the branch is mentioned in source-location in your entity YAML. It is suggested to provide a branchName if you want to use the same for all repositories; otherwise, we use the branch name mentioned in the source-location.
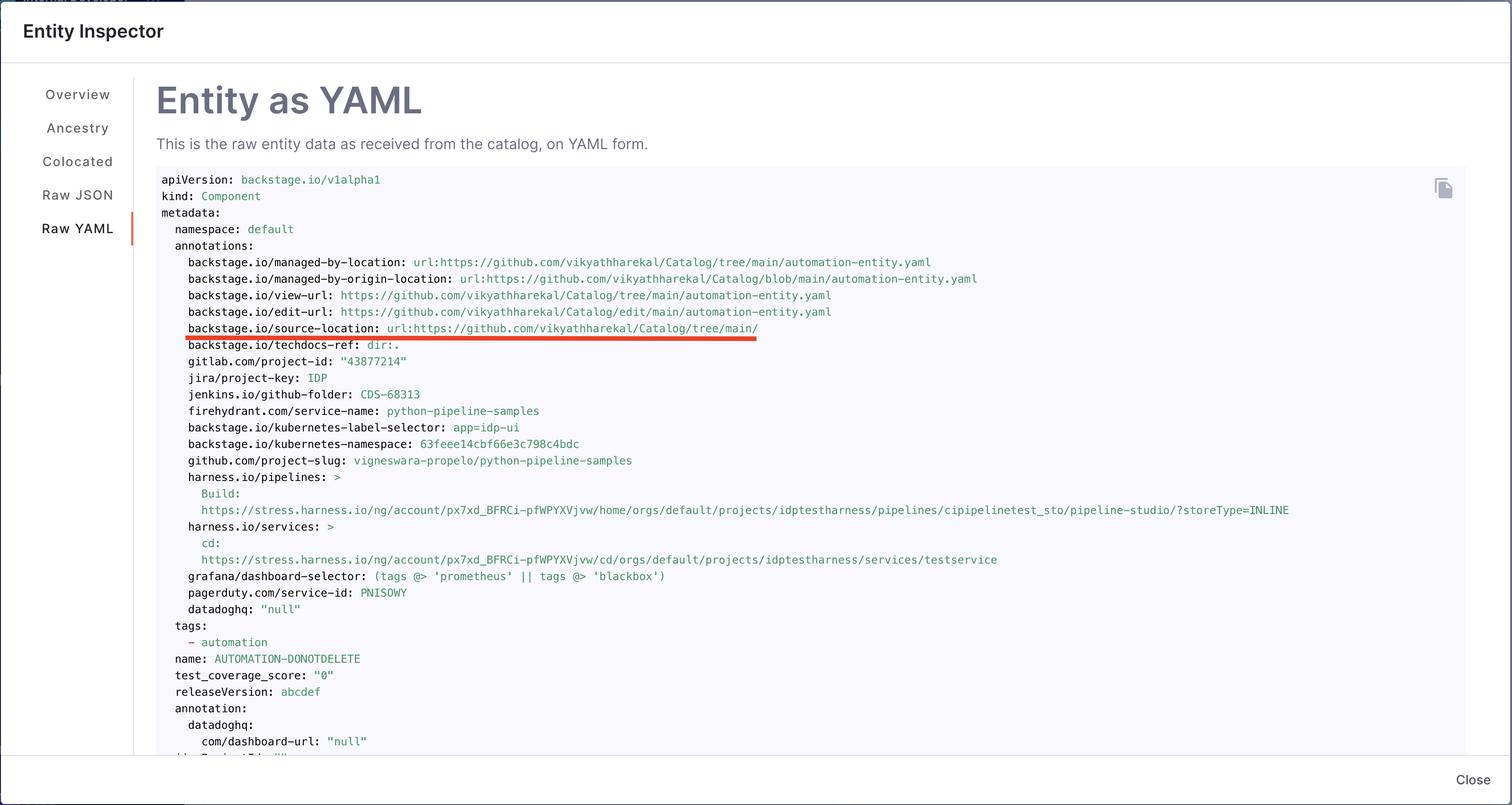
If you mention the branchName field as a check config other than what is present in the source-location, the priority order conditions are:
- If it is in both, the check configuration will take precedence
- If it is in only one, we will use that value
- If it is in neither, the check will fail
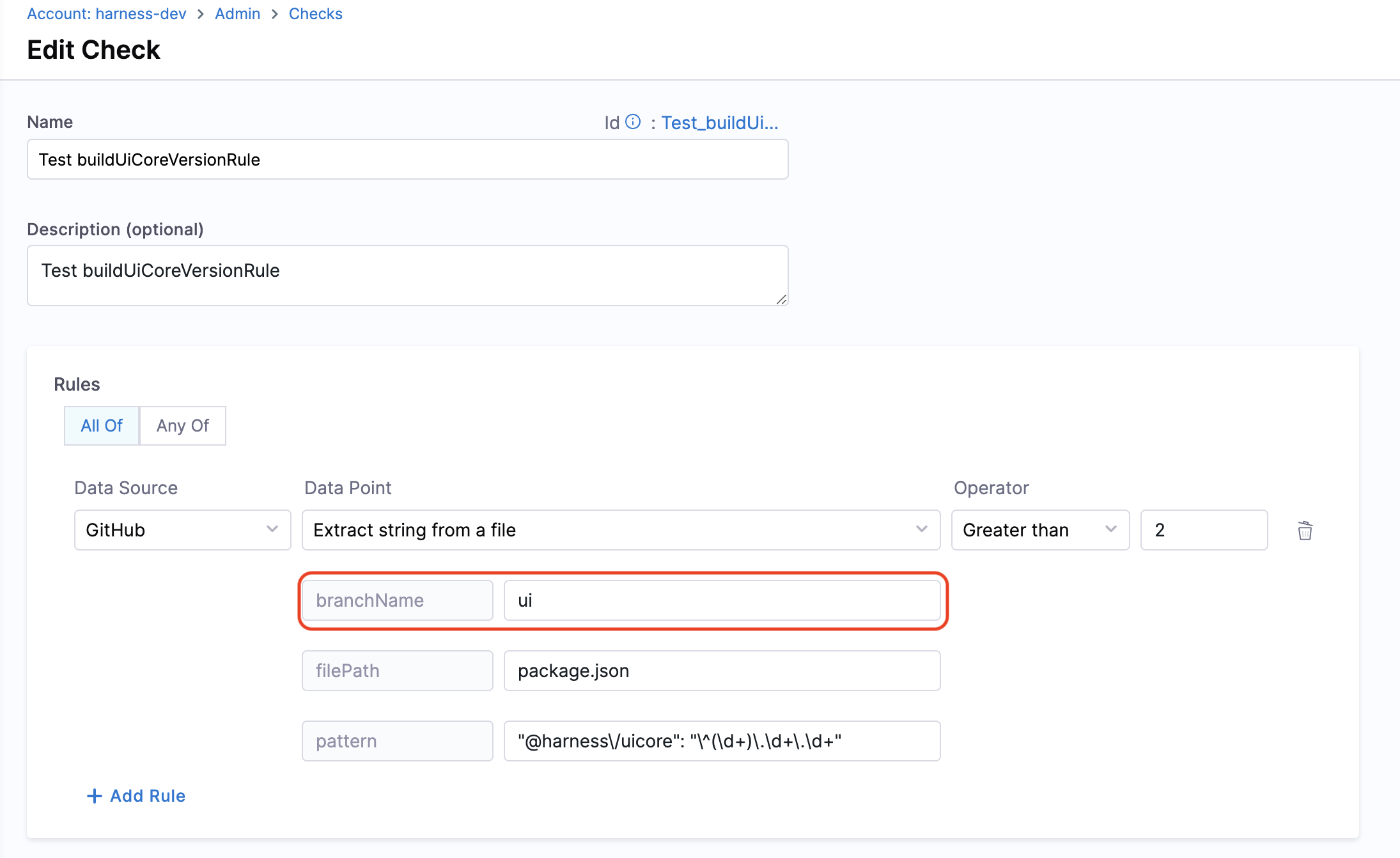
Prerequisites: Provide suitable backstage.io/source-location annotation if the catalog YAML file is present outside the source GitHub repository.
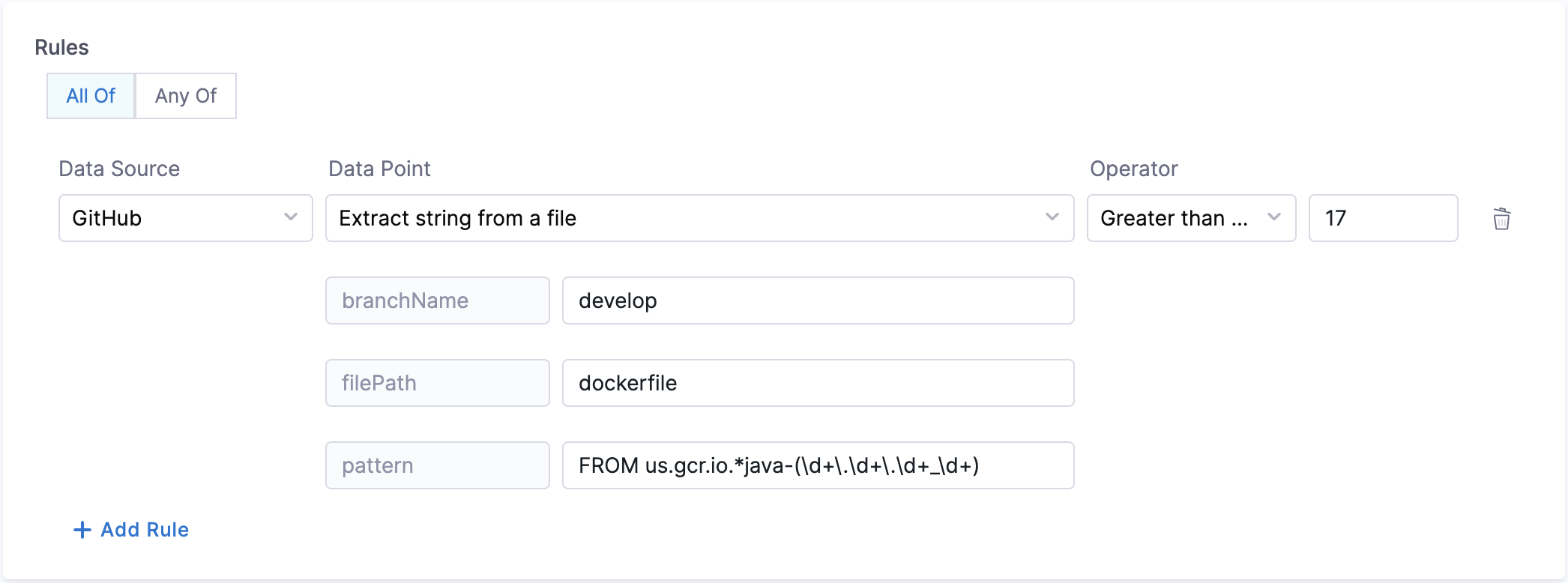
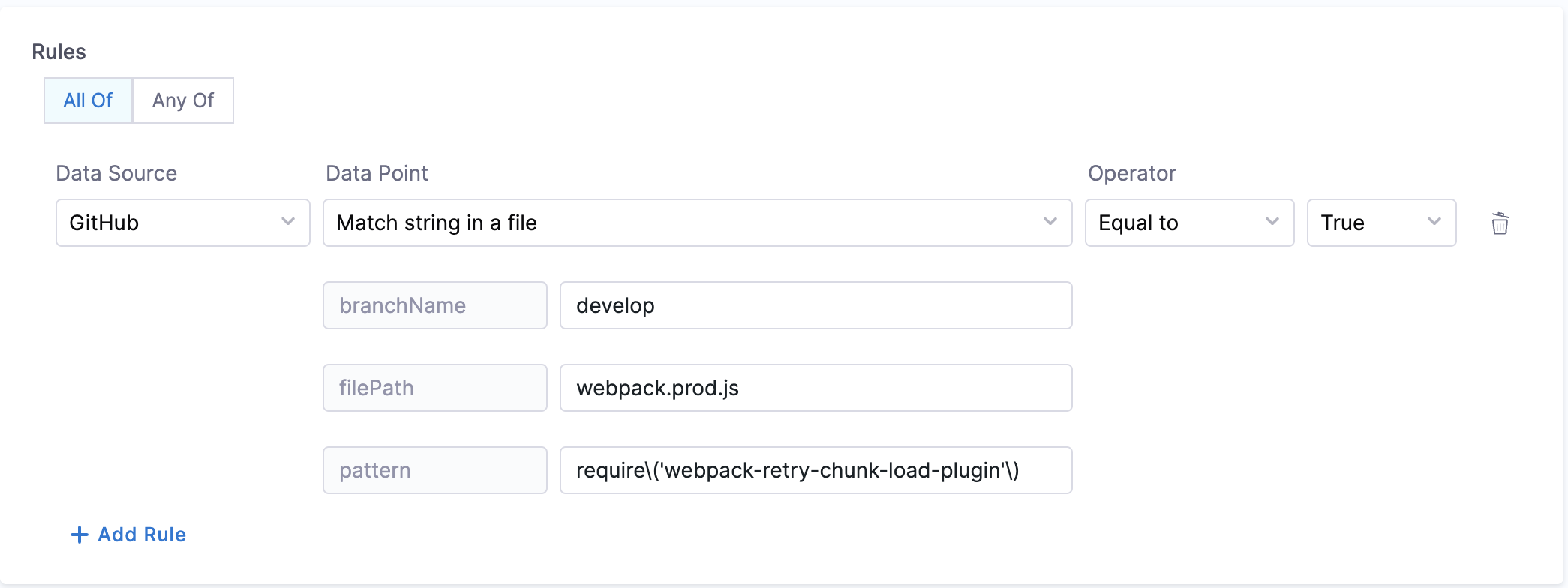
13. Match string in a file
Objective: Matches the pattern in the given file from the branch.
Calculation Method: If a branch name is specified, it is utilized. However, if no branch name is provided, the system retrieves information from the catalog YAML file using the backstage.io/source-location annotation to determine the branch name and repository details. It is essential to specify the filename with its extension or provide the relative path from the root folder (e.g., README.md or docs/README.md) in the conditional input field. After fetching the file, the contents are examined to find the pattern. Returns true/false based on whether the pattern was found or not.
URL priority for branch name field
In some data points, we take branchName as input. It is an optional field if the branch is mentioned in source-location in catalog-info.yaml. It is suggested to provide a branchName if you want to use the same for all repositories; otherwise, we use the branch name mentioned in the source-location.
If you mention the branchName field as a check config other than what is present in the source-location, the priority order conditions are:
- If it is in both, the check configuration will take precedence
- If it is in only one, we will use that value
- If it is in neither, the check will fail
Prerequisites: Provide suitable backstage.io/source-location annotation if the catalog YAML file is present outside the source GitHub repository.
GitLab
The following data points are available for the GitLab data source.
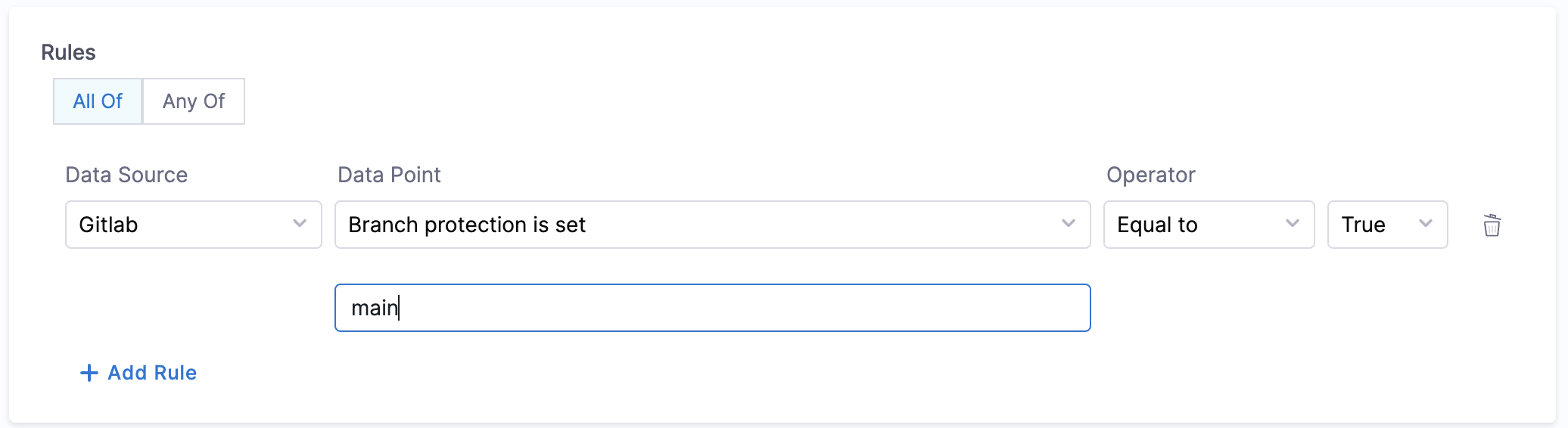
1. Branch protection
Objective: Ensure that branch protection rules disallow force push and delete.
Calculation Method: Fetches backstage.io/source-location annotation from the catalog YAML file to find repository details and verify the branch protection rules.
Prerequisites:
- GitLab Connector with Admin access
- Provide suitable
backstage.io/source-locationannotation if the catalog YAML file is present outside the source GitLab repository
Example YAML:
kind: "Component"
apiVersion: "backstage.io/v1alpha1"
metadata:
name: order-service
annotations:
backstage.io/source-location: 'url:https://gitlab.com/kubernetes/kubernetes/tree/master'
...
spec:
...
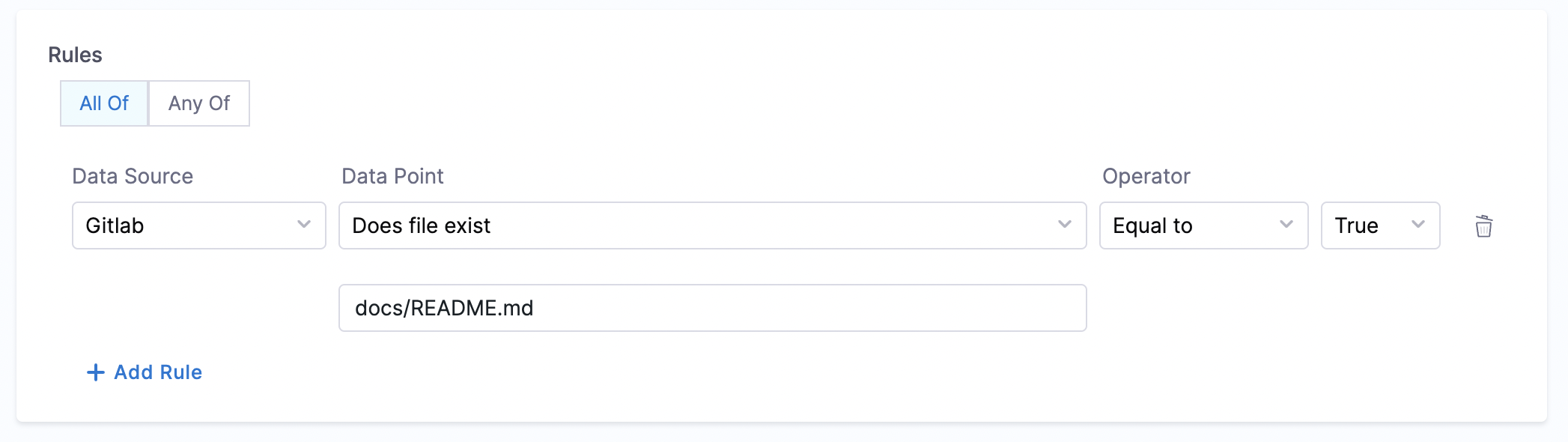
2. File existence
Objective: Verify the existence of a specified file in the repository.
Calculation Method: Uses the backstage.io/source-location annotation to locate the repository and check for the file's presence. Make sure to mention the filename with extension or relative path from the root folder (e.g., README.md or docs/README.md) in the conditional input field.
Prerequisites: Provide suitable backstage.io/source-location annotation if the catalog YAML file is present outside the source GitLab repository.
Example YAML:
kind: "Component"
apiVersion: "backstage.io/v1alpha1"
metadata:
name: order-service
annotations:
backstage.io/source-location: 'url:https://gitlab.com/kubernetes/kubernetes/tree/master'
...
spec:
...
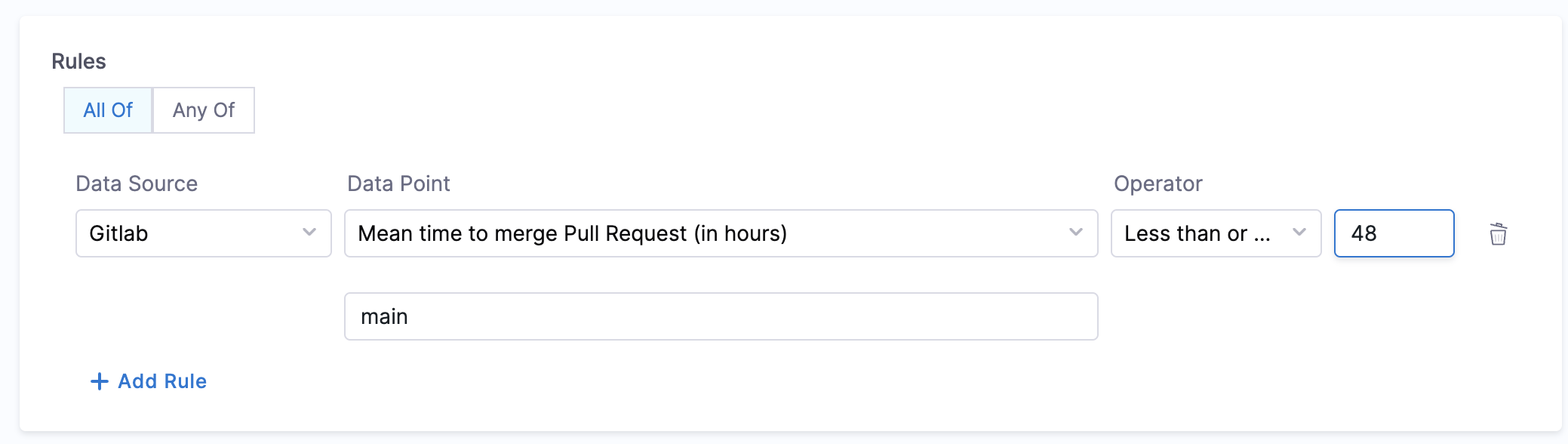
3. Mean time to merge pull request
Objective: Calculate the average time taken to merge the last 100 pull requests.
Calculation Method: Retrieves repository details using backstage.io/source-location and calculates the average merge time.
Prerequisites:
- Provide suitable
backstage.io/source-locationannotation if the catalog YAML file is present outside the source GitLab repository - Make sure to mention the branch name in the conditional input field
Example YAML:
kind: "Component"
apiVersion: "backstage.io/v1alpha1"
metadata:
name: order-service
annotations:
backstage.io/source-location: 'url:https://gitlab.com/kubernetes/kubernetes/tree/master'
...
spec:
...
4. Extract string from a file
Objective: Gets the string matching the pattern from given file from the branch.
Calculation Method: If a branch name is specified, it is utilized. However, if no branch name is provided, the system retrieves information from the catalog YAML file using the backstage.io/source-location annotation to determine the branch name and repository details. It is essential to specify the filename with its extension or provide the relative path from the root folder (e.g., README.md or docs/README.md) in the conditional input field. After fetching the file, the designated pattern is then searched within the file contents, and its value is extracted and returned.
URL priority for branch name field
In some data points, we take branchName as input. It is an optional field if the branch is mentioned in source-location in catalog-info.yaml. It is suggested to provide a branchName if you want to use the same for all repositories; otherwise, we use the branch name mentioned in the source-location.
If you mention the branchName field as a check config other than what is present in the source-location, the priority order conditions are:
- If it is in both, the check configuration will take precedence
- If it is in only one, we will use that value
- If it is in neither, the check will fail
Prerequisites: Provide suitable backstage.io/source-location annotation if the catalog YAML file is present outside the source GitLab repository.
5. Match string in a file
Objective: Matches the pattern in the given file from the branch.
Calculation Method: If a branch name is specified, it is utilized. However, if no branch name is provided, the system retrieves information from the catalog YAML file using the backstage.io/source-location annotation to determine the branch name and repository details. It is essential to specify the filename with its extension or provide the relative path from the root folder (e.g., README.md or docs/README.md) in the conditional input field. After fetching the file, the contents are examined to find the pattern. Returns true/false based on whether the pattern was found or not.
URL priority for branch name field
In some data points, we take branchName as input. It is an optional field if the branch is mentioned in source-location in catalog-info.yaml. It is suggested to provide a branchName if you want to use the same for all repositories; otherwise, we use the branch name mentioned in the source-location.
If you mention the branchName field as a check config other than what is present in the source-location, the priority order conditions are:
- If it is in both, the check configuration will take precedence
- If it is in only one, we will use that value
- If it is in neither, the check will fail
Prerequisites: Provide suitable backstage.io/source-location annotation if the catalog YAML file is present outside the source GitLab repository.
Bitbucket
The following data points are available for the Bitbucket data source. All data points follow similar patterns to GitHub and GitLab, requiring the backstage.io/source-location annotation for repository identification.
Available data points:
- Branch Protection - See GitHub section for detailed description.
This check works with repository-level branch restrictions. Bitbucket Cloud allows branch restrictions to be configured at both the repository and project levels. However, Bitbucket Cloud's REST API only exposes repository-level branch restrictions. Project-level restrictions, while enforced by Bitbucket across all repositories in a project, are not accessible via the API and therefore cannot be detected programmatically by any tool. To ensure this check works as expected, configure branch restrictions at the repository level.
- File Existence - See GitHub section for detailed description
- Mean Time to Merge Pull Request - See GitHub section for detailed description
- Extract String from a File - See GitHub section for detailed description
- Match String in a File - See GitHub section for detailed description
URL priority for branch name field
For Bitbucket data points that require a branch name, the same priority rules apply as mentioned in the GitHub URL Priority section above.
Prerequisites for Bitbucket connector
Configure the Bitbucket connector using Email and API Token authentication to ensure Scorecards can fetch Bitbucket data without permission-related issues.

Use the following credentials when setting up the connector:
- Email: Your Bitbucket account email address
- API Token: A Bitbucket API token with the required scopes
To create an API token, go to Atlassian account security settings.
The API token must include the following scopes:
read:repository:bitbucketread:project:bitbucketread:pullrequest:bitbucketread:workspace:bitbucketadmin:project:bitbucketadmin:repository:bitbucketadmin:workspace:bitbucket
Harness
The Harness data source provides insights into your CI/CD pipelines and deployments.
Before you begin
To use Harness as a data source for Scorecards, you need to:
- Add the Harness annotation in your
catalog-info.yamlfile:
metadata:
annotations:
harness.io/pipelines: |
labelA: <harness_pipeline_url>
labelB: <harness_pipeline_url>
- The pipeline URL format should be:
https://app.harness.io/ng/account/<ACCOUNT_ID>/module/ci/orgs/<ORG_ID>/projects/<PROJECT_ID>/pipelines/<PIPELINE_ID>/
Available data points:
-
Deployment Frequency (Per Day)
- Calculates the average number of deployments per day over the last 30 days
-
Deployment Frequency (Per Week)
- Calculates the average number of deployments per week over the last 12 weeks
-
Deployment Frequency (Per Month)
- Calculates the average number of deployments per month over the last 6 months
-
Change Failure Rate
- Calculates the percentage of deployments that failed in the last 30 days
-
Mean Time to Restore (MTTR)
- Calculates the average time taken to restore service after a failed deployment
-
CI Pipeline Success Rate (Last 7 Days)
- Percentage of successful CI pipeline executions in the past 7 days
-
CI Pipeline Success Rate (Last 30 Days)
- Percentage of successful CI pipeline executions in the past 30 days
Error scenarios
Missing Harness Annotation:
If the harness.io/pipelines annotation is missing from the catalog-info.yaml file, the check will fail with an appropriate error message indicating that the annotation is required.
Invalid Pipeline URL: If the pipeline URL format is incorrect or the pipeline does not exist, the check will fail with an error message.
Catalog
The Catalog data source allows you to create checks based on the entity definitions in your Catalog entity YAML file.
Available data points:
-
Annotation Exists
- Checks if a specific annotation exists in the catalog entity
- Example:
catalog.annotationExists."jira/project-key"
-
PagerDuty Annotation Exists
- Checks if the PagerDuty annotation exists
- Example:
catalog.pagerdutyAnnotationExists
-
Kubernetes Annotation Exists
- Checks if Kubernetes-related annotations exist
- Example:
catalog.annotationExists."backstage.io/kubernetes-id"
-
Custom Metadata Fields
- Access any custom metadata fields defined in your catalog
- Example:
catalog.metadata.testCoverageScore
Example usage
catalog.annotationExists."jira/project-key" == true &&
catalog.annotationExists."backstage.io/techdocs-ref" == true
Example catalog-info.yaml
apiVersion: backstage.io/v1alpha1
kind: Component
metadata:
name: my-service
description: My awesome service
annotations:
jira/project-key: MYPROJ
backstage.io/techdocs-ref: dir:.
backstage.io/kubernetes-id: my-service
pagerduty.com/integration-key: abc123
testCoverageScore: 85
spec:
type: service
lifecycle: production
owner: team-a
Kubernetes
The Kubernetes data source provides insights into your Kubernetes deployments and resources.
Before you begin
-
Enable Kubernetes Plugin:
- The Kubernetes plugin must be enabled in your IDP
- Configure the plugin with appropriate cluster access
-
Add Kubernetes Annotation:
- Add the
backstage.io/kubernetes-idannotation to yourcatalog-info.yaml:
- Add the
metadata:
annotations:
backstage.io/kubernetes-id: my-service
Available data points:
-
Pod Count
- Returns the number of pods running for the service
-
Deployment Status
- Checks if the deployment is healthy and running
-
Resource Utilization
- Monitors CPU and memory usage
-
Replica Count
- Returns the number of replicas configured
Jira
The Jira data source provides insights into your project management and issue tracking.
Available data points:
-
Open Issues Count
- Calculates the total number of open issues for a project
-
Issues by Priority
- Counts issues based on priority (High, Medium, Low)
-
Issues by Status
- Counts issues based on status (To Do, In Progress, Done)
-
Average Time to Close Issues
- Calculates the average time taken to close issues
-
Overdue Issues Count
- Counts the number of issues past their due date
Prerequisites:
- Add the Jira project key annotation in your
catalog-info.yaml:
metadata:
annotations:
jira/project-key: MYPROJ
PagerDuty
The PagerDuty data source provides insights into your incident management and on-call schedules.
Before you begin
-
Enable PagerDuty Plugin:
- The PagerDuty plugin must be enabled in your IDP
-
Add PagerDuty Annotation:
- Add the PagerDuty integration key to your
catalog-info.yaml:
- Add the PagerDuty integration key to your
metadata:
annotations:
pagerduty.com/integration-key: <your-integration-key>
Available data points:
-
Open Incidents Count
- Returns the number of currently open incidents
-
Mean Time to Acknowledge (MTTA)
- Calculates the average time taken to acknowledge incidents
-
Mean Time to Resolve (MTTR)
- Calculates the average time taken to resolve incidents
-
Incidents in Last 30 Days
- Counts the total number of incidents in the past 30 days
-
On-Call Schedule Status
- Checks if an on-call schedule is configured
Error scenarios
Missing PagerDuty Annotation: If the PagerDuty annotation is missing from the catalog-info.yaml file, the check will fail with an error message indicating that the annotation is required.
Custom data sources
Custom data sources enable you to extend Harness IDP's scorecard capabilities beyond the out-of-the-box integrations. This is particularly useful when you want to build scorecards for tools that aren’t natively supported or when you need to enrich existing catalog entities with additional metadata.
There are two primary approaches to working with data sources in Harness IDP:
- Out-of-the-Box Data Sources: Native integrations (GitHub, GitLab, Jira, PagerDuty, etc.) that automatically fetch data from connected tools
- Custom Data Sources: User-defined data ingested via the Catalog Ingestion API, allowing you to bring in data from any source
When to use custom data sources
Consider using custom data sources when:
- Tool Not Natively Supported: You’re using a tool that doesn’t have an out-of-the-box integration (e.g., custom testing frameworks, proprietary tools, internal systems)
- Multiple Data Sources: You want to combine data from multiple tools into a single metric
Use the Catalog Ingestion API to programmatically update your catalog entities with custom data. The API accepts the full entity YAML and updates the catalog.
Steps
-
Create a Custom Check using the Catalog Expressions Data Point
- Navigate to Configure → Scorecards → Checks
- Create a new check and select Catalog as the data source
- Use catalog expressions to reference your custom data
-
Ingest Data into the Catalog using the API
- Use the Catalog Ingestion API to push your custom data
- You can use a Python script or any other method to automate this process
-
Schedule Periodic Data Updates
- Set up a cron job or scheduled process to push data periodically and keep your catalog up-to-date
- You can use a scheduled Harness pipeline, a cron job, or any other automation to trigger the ingestion API at regular intervals (e.g., hourly, daily)
- This ensures your custom data remains current and reflects the latest information from your data sources
Watch this video to see a working example. Here is a sample Harness pipeline with a Python script for ingestion.
Next steps
- Learn how to create custom checks using these data sources
- Explore scorecard tutorials for advanced use cases:
- Review how to manage your scorecards