Define failure strategies for stages and steps
A failure strategy defines how steps, stages, and step groups handle different failure conditions.
A failure strategy consists of error conditions that must occur to trigger the strategy and the actions to take when those failure conditions occur.
Failure strategies are a critical pipeline design component that determine what fails a step or stage and what to do when the failure occurs.
Video: Configure failure strategies
Configure failure strategies
You can apply failure strategies to:
- Stages: A stage failure strategy applies to all steps and step groups in the stage that don't have step-level failure strategies.
- Steps: This failure strategy overrides (or enhances) the stage failure strategy.
- Step Groups: You can set up a failure strategy for all steps in the group. Individual steps in the group don't have a failure strategy.
- Pipelines: Pipeline rollback is a failure strategy for all stages in a pipeline. The pipeline rolls back if any of the stages in the pipeline fails.
Add a stage failure strategy
The stage failure strategy applies to all steps in the stage that do not have their own failure strategy configured.
-
In your pipeline, select the stage where you want to add the failure strategy.
-
Select the Advanced tab.
-
Under Failure Strategy, the default stage failure strategy is shown:
On all errors other than those specified in failure strategies defined here, perform action.You can't remove the default strategy, but you can edit it to choose a different Action, Timeout, and Post timeout action.
-
To add an additional stage failure strategy, select Add, and then configure the failure strategy settings:
- On failure of type: Select one or more of the error types to trigger the failure strategy.
- Perform Action: Select the action that should occur when the specified failure event happens.
- Timeout and Post timeout action: These are available if you selected Manual Intervention for the Action. The manual intervention action allows a user to intervene and choose an Action when the specified failure event occurs. You can enter a Timeout for the user to select an action, and a Post Timeout Action to fallback on if the user doesn't manually select an action in a certain amount of time.
- Retry Count, Retry Intervals, and Post retry failure action: These are available if you selected Retry for the Action. Enter the number of times to retry the stage, the retry interval between attempts, and the Post retry failure action to specify what action to take when all retry attempts have been exhausted and failed. For example, you can configure the stage to rollback or abort after all retries fail.
Stage failure strategy YAML examples
The following examples demonstrate how to configure stage-level failure strategies in YAML.
Stage rollback on all errors
This example shows a deployment stage configured to automatically roll back when any error occurs during stage execution.
- stage:
name: k8s
identifier: k8s
description: ""
type: Deployment
spec:
...
tags: {}
failureStrategies:
- onFailure:
errors:
- AllErrors
action:
type: StageRollback
Retry stage with rollback on retry failure
This example demonstrates a deployment stage that retries up to 2 times with a 1-hour interval between retries. If all retry attempts fail, the stage performs a rollback.
stages:
- stage:
name: k8s
identifier: k8s
description: ""
type: Deployment
spec:
...
tags: {}
failureStrategies:
- onFailure:
errors:
- AllErrors
action:
type: Retry
spec:
onRetryFailure:
action:
type: StageRollback
retryCount: 2
retryIntervals:
- 1h
Add a step failure strategy
Steps don't have a default failure strategy. Instead, steps inherit the stage failure strategy if there is no step-level failure strategy.
When you add a step failure strategy, you override the stage failure strategy for that step.
To add a step failure strategy:
-
Edit the step where you want to add the failure strategy.
-
Select the Advanced tab.
-
Select Failure Strategy, select Add, and then configure the failure strategy settings:
- On failure of type: Select one or more of the error types to trigger the failure strategy.
- Perform Action: Select the action that should occur when the specified failure event happens.
- Timeout and Post timeout action: These are available if you selected Manual Intervention for the Action. The manual intervention action allows a user to intervene and choose an Action when the specified failure event occurs. You can enter a Timeout for the user to select an action, and a Post Timeout Action to fallback on if the user doesn't manually select an action in a certain amount of time.
- Retry Count, Retry Intervals, and Post retry failure action: These are available if you selected Retry for the Action. Enter the number of times to retry the step, the retry interval between attempts, and the Post retry failure action to specify what action to take when all retry attempts have been exhausted and failed. For example, you can configure the step to perform a stage rollback or abort after all retries fail.
Step failure strategy YAML examples
The following examples demonstrate how to configure step-level failure strategies in YAML.
Manual intervention on failure
This example shows a Kubernetes rolling deployment step with a failure strategy that triggers manual intervention when any error occurs. If no manual action is taken within 1 hour, the pipeline automatically aborts.
- step:
name: Rollout Deployment
identifier: rolloutDeployment
type: K8sRollingDeploy
timeout: 10m
spec:
skipDryRun: false
pruningEnabled: false
failureStrategies:
- onFailure:
errors:
- AllErrors
action:
type: ManualIntervention
spec:
onTimeout:
action:
type: Abort
timeout: 1h
Ignore failure
This example shows a deployment step configured to ignore all errors and continue pipeline execution. In the UI, the step will be marked as success (failure ignored), and the pipeline will proceed to the next step.
- step:
name: Rollout Deployment
identifier: rolloutDeployment
type: K8sRollingDeploy
timeout: 10m
spec:
skipDryRun: false
pruningEnabled: false
failureStrategies:
- onFailure:
errors:
- AllErrors
action:
type: Ignore
Retry with stage rollback on retry failure
This example demonstrates a deployment step that retries up to 2 times with a 1-hour interval between retries. If all retry attempts fail, the stage performs a rollback.
- step:
name: Rollout Deployment
identifier: rolloutDeployment
type: K8sRollingDeploy
timeout: 10m
spec:
skipDryRun: false
pruningEnabled: false
failureStrategies:
- onFailure:
errors:
- AllErrors
action:
type: Retry
spec:
retryCount: 2
onRetryFailure:
action:
type: StageRollback
retryIntervals:
- 1h
Failure strategies as runtime input
You can also define stage, step, and step group failure strategies at runtime by configuring them as runtime inputs.
To do this, go to the Failure Strategy settings where you want to configure a failure strategy to be specified at runtime, select the Thumbtack icon, and change the input type to Runtime Input.
When you run the pipeline, you'll be prompted to define the failure strategy settings for that run.
Due to the potential complexity of failure strategies, input sets are useful for failure strategies as runtime input. Input sets contain pre-defined runtime inputs that you select at runtime. This eliminates the need to manually define the entire failure strategy each time.
Failure strategies for CD steps and stages
For guidance on configuring failure strategies for CD stages and steps, go to Define a failure strategy on Harness CD stages and steps.
Failure strategy settings
Error types
The following error types can be selected in a failure strategy.
| Error Type | Description |
|---|---|
| Authentication Errors | Credentials provided in a connector are not valid. Typically, the Harness secret used for one of the credentials is incorrect. If Harness cannot determine if the error is for authentication or authorization, it is treated as an authentication error. |
| Authorization Errors | The credentials are valid but the user permissions needed to access the resource are not sufficient. If Harness cannot determine if the error is for authentication or authorization, it is treated as an authentication error. |
| Connectivity Errors | A Harness Delegate can't connect to a specific resource, such as a repository, VM, or secrets manager. |
| Delegate Provisioning Errors | No available delegate can accomplish the task, or the task is invalid. For example, if an HTTP step attempts to connect to a URL but there is no available delegate to perform the task. |
| Timeout Errors | A Harness Delegate fails to complete a task within the stage/step timeout limit. For example, if the Kubernetes workload you are deploying fails to reach a steady state within the step timeout limit. |
| Unknown Errors | Errors that don't fall into any other category. This includes Harness application errors. |
| Verification Failures | A Harness Continuous Verification step fails. |
| Policy Evaluation Failures | An Open Policy Evaluation (OPA) applied on a step fails. |
| Execution-time Inputs Timeout Errors | A step times out when running a pipeline due to the unavailability of a runtime input. |
| Approval Rejection | An approval step is rejected. You can select specific failure strategies for approval rejection across steps and stages. |
| Delegate Restart | An error triggered when the delegate is unreachable when running a pipeline. |
| All Errors | An error whether defined by the other error types or not. |
Error scope
The scope of a failure strategy is confined to where it is set.
For example, a failure strategy set on a step doesn't impact the failure strategy set on a stage. Likewise, the failure strategy set at the stage doesn't override any failure strategies on its steps.
Rollback stage
Both step and stage failure strategies include the Rollback Stage action option. There is no rollback step option.
Failure strategy actions
The following table lists the failure strategy actions and how they work at the step, step group, and stage levels.
These actions can be applied to the failure strategy as primary action and timeout action.
| Action | Step | Step Group | Stage |
|---|---|---|---|
| Manual Intervention | A Harness user can perform a manual intervention when the error type occurs. There are several options to select from: Mark as Success Ignore Failure Retry Abort Rollback StageHarness pauses the pipeline execution when waiting for manual intervention. The pipeline execution state appears as Paused. | Same as step. | Same as step, but applies to all steps. |
| Mark as Success | The step is marked as Successful and the stage execution continues. | Same as step. | The failed step is marked as Successful and the pipeline execution continues. |
| Ignore Failure | The stage execution continues. In the UI, the step is marked as success (failure ignored), and rollback is not triggered. | Same as step. | Same as step. |
| Retry Step | Harness retries the execution of the failed step automatically. You can set Retry Count and Retry Intervals. You can also configure a Post retry failure action to specify what happens when all retry attempts fail (for example, abort or rollback stage). Additionally, you can define a JEXL condition to retry the step only when a specific condition is met. | Same as step. | Same as step. |
| Retry Step Group | N/A | Harness will retry the execution of the complete step group automatically, from the beginning. You can set Retry Count and Retry Intervals. You can also configure a Post retry failure action to specify what happens when all retry attempts fail. | N/A |
| Abort | Pipeline execution is aborted. If you select this option, no timeout is needed. | Same as step. | Same as step. |
| Rollback Stage | The stage rolls back to the state prior to stage execution. How the stage rolls back depends on the type of build or deployment it was performing. | Same as step. | Same as step. |
| Rollback Step Group | N/A | The step group rolls back to the state prior to step group execution. How the step group rolls back depends on the type of build or deployment it was performing. | N/A |
| Mark As Failure | Harness marks the step as Failed. | Harness marks the step group as Failed. | Harness marks the stage as Failed and executes the next stage. |
Mark As Failure as a Failure Strategy marks the stage/stepGroup/step as failed and moves the execution to next step/stage according to when conditions applied on the next step/stage.
Manual interventions
Here is what a Manual Intervention action looks like when a failure occurs:
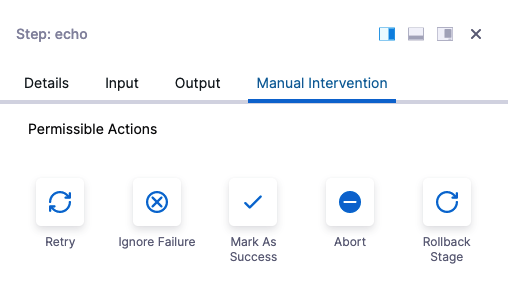
The user can select an Action. If the Manual Intervention exceeds the Timeout setting, Harness automatically selects the Post Timeout Action.
Customize Available Actions for Manual Intervention
Currently, this feature is behind the feature flag CDS_MANUAL_INTERVENTION_CUSTOM_ACTIONS. Contact Harness Support to enable the feature.
You can now restrict the set of available actions shown to the pipeline executor during a manual intervention. This applies when a step or stage fails and the configured Failure Strategy is Manual Intervention.
By customizing the available actions, you can:
- Prevent unsafe actions like Retry or Pipeline Rollback
- Ensure consistency and control over failure handling
- Tailor manual intervention choices based on stage or step specific requirements
At pipeline design time, you can whitelist the allowed manual intervention actions using a new Allowed Actions dropdown.
Available Actions
- Retry Step
- Mark as Success
- Mark as Failure
- Ignore Failure
- Retry from Stage
- Rollback Pipeline
The list of available actions may vary slightly based on the stage type (e.g., Deploy, Approval, Custom stage, etc.).
You can also use the checkbox All Actions to allow all available actions.
After selecting the allowed actions, you must also configure the following:
- Timeout: Duration to wait for manual intervention.
- Post-Timeout Action: Action to take automatically if no manual decision is made within the timeout.

Prioritization and handling
How and when failure strategies are resolved depends on a number of conditions.
Failure strategies take precedence over conditional executions
Harness pipeline stages and steps can include both conditional executions and failure strategies.
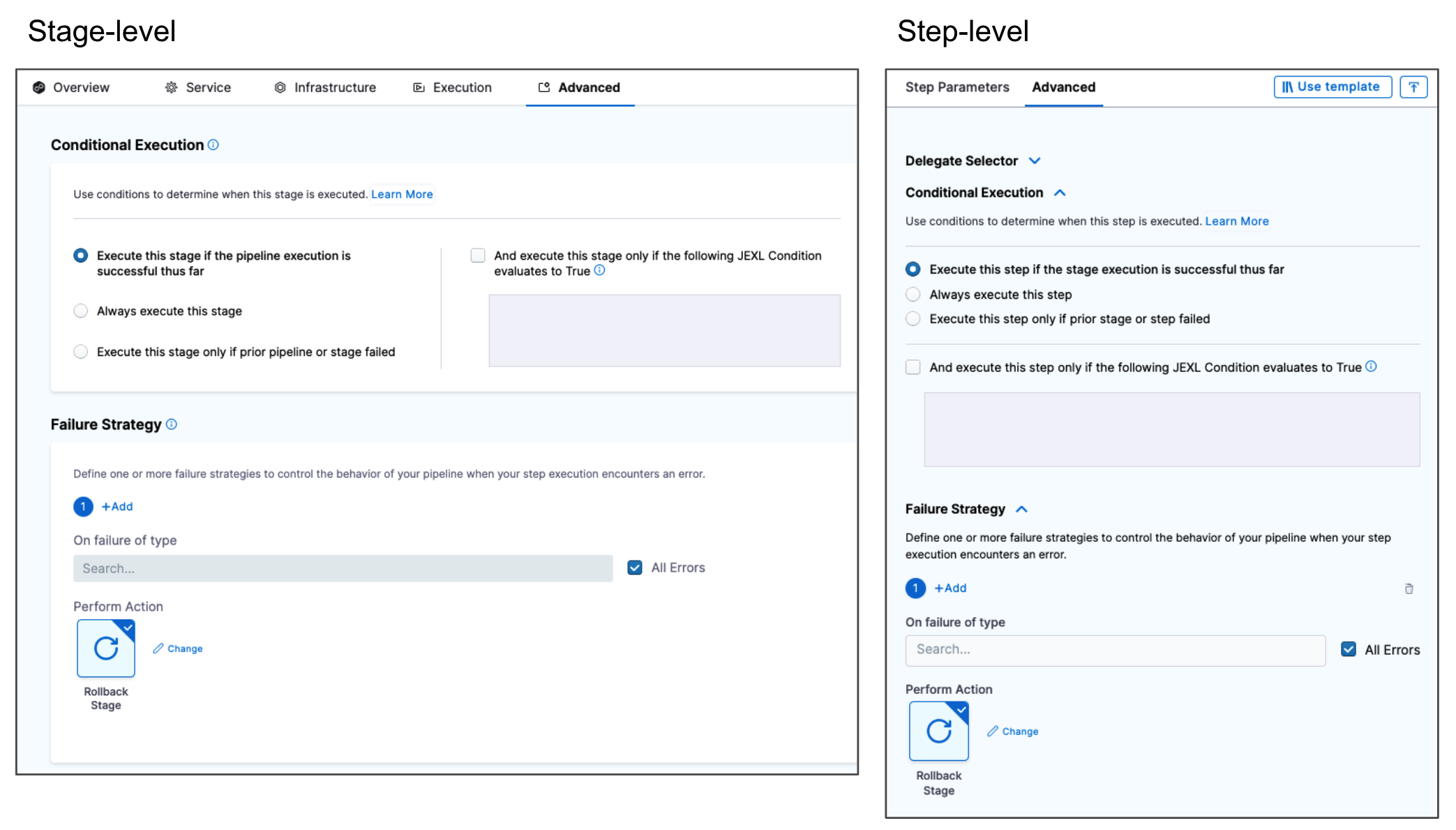
When using these settings together in multiple stages, you must consider how they could interact.
For example, assume you have a pipeline with two stages: stage1 and stage2. Assume stage2 has a Conditional Execution set to Execute this stage only if prior pipeline or stage failed, and stage1 has a Failure Strategy set to Rollback Stage on All Errors. With this configuration, if stage1 has any error, it rolls back and it isn't marked as failed; therefore, the Conditional Execution for stage2 isn't triggered and stage2 doesn't run. To get stage2 to run, you can set the Failure Strategy for stage1 to Ignore Failure. This causes the pipeline to proceed (instead of rolling back) when stage1 fails, and, since stage1 is now marked as failed, the Conditional Execution for stage2 is triggered and stage2 runs.
If you want to run particular steps when a stage fails, make sure you add those steps to the stage's Rollback failure strategy settings. Typically, you don't want a rollback to continue when there is an error. However, if you want to force a step to run whether or not the rollback fails, include the required step in the stage's Rollback settings, configure the required step's conditional execution to Always, and then set the preceding step's failure strategy to Mark as failure for All errors. This ensures the required step runs even if the previous step fails.
Stage, step, and step group failure strategy priority
The stage failure strategy applies to all steps that do not have their own failure strategy. A step's failure strategy takes precedence over a step group's failure strategy, which takes precedence over a stage's failure strategy.
Step failure strategies are evaluated before step group's and stage's failure strategy.
The order of the steps determines which failure strategy is evaluated first.
If the step is not part of a step group, and the first step in the execution doesn't have a failure strategy, the stage's failure strategy is used. If the second step has its own failure strategy, it is used. And so on.
Multiple failure strategies in a stage
A stage can have multiple failure strategies.
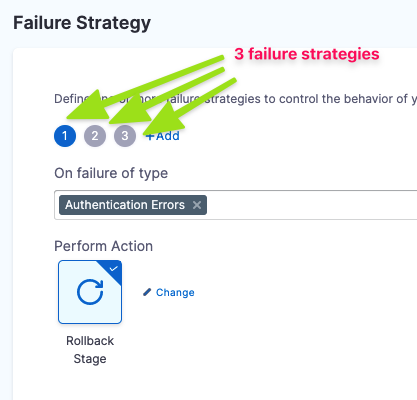
When using multiple failure strategies in a stage, consider the following:
- For failure strategies that don't overlap (different types of failures selected), they behave as expected.
- Two failures cannot occur at the same time. Whichever error occurs first, that failure strategy is used.
Failure strategy conflicts
Conflicts might arise between failure strategies on the same level or different levels (meaning stage or step level).
Same level
If there is a conflict between multiple failures in strategies on the same level, the first applicable strategy is used and the remaining strategies are ignored.
For example, consider these two strategies:
- Abort on verification failure or authentication failure.
- Ignore on verification failure or connectivity error.
Here is what will happen:
- On a verification failure, the stage is aborted.
- On an authentication failure, the stage is aborted.
- On a connectivity error, the error is ignored.
Different levels
If there is a clash between selected errors in strategies on different levels, the step-level strategy is used and the stage-level strategy is ignored.