Overview
Harness provides several controls to ensure the safe execution of chaos experiments on your infrastructure. This section explains security considerations and associated features across administrative and runtime environments, including:
- Connectivity from target clusters and request authentication
- Kubernetes roles for the chaos infrastructure
- User authentication to the Harness Chaos Engineering module
- Access control and permissions for chaos actions
- Secrets management, including external secret manager support
- Blast radius control using permissions
Further sections provide a quick summary of the internal security controls and processes for the chaos module to help you gain insights into how security is baked into the build process. The processes include:
- Base images
- Vulnerability scanning
- Pen testing
Connectivity from target clusters and authentication of requests
You must connect your Kubernetes infrastructure (clusters or namespaces) to HCE (Harness Chaos Engineering) to discover the microservices and execute chaos experiments on them. The connection between your Kubernetes infrastructure and HCE is enabled by a set of deployments on the Kubernetes cluster. The deployments comprise a relay (subscriber) that communicates with the HCE control plane and custom controllers, which carry out the chaos experiment business logic.
This group of deployments (known as the execution plane) is referred to as the chaos infrastructure.
The chaos infrastructure connects to the control plane by making outbound requests over HTTPS (port number 443) to claim and perform chaos tasks. The connections don't require you to create rules for inbound traffic. A unique ID, named cluster ID, is assigned to the chaos infrastructure. The chaos infrastructure shares a dedicated key, named access-key, with the control plane. Both cluster ID and access key are generated during installation. Every API request made to the control plane includes these identifiers for authentication purposes.
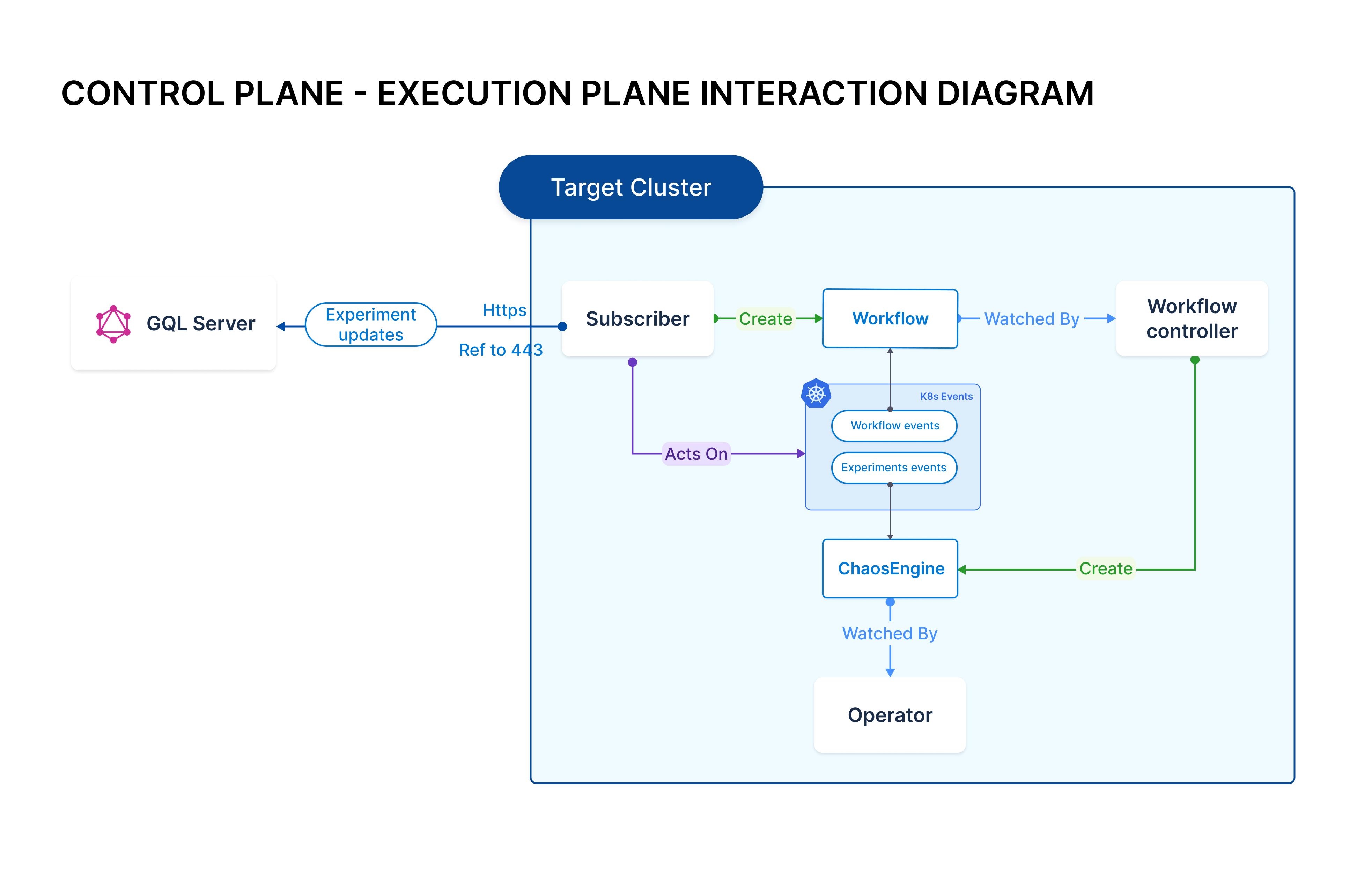
Harness can leverage the same cluster (or namespace) to inject chaos into infrastructure targets (such as VMs, cloud resources etc.) within the user environment, provided that the cluster can access them. For more information on Cloud Secrets, refer to the above diagram.
Kubernetes roles for chaos infrastructure
You can install the deployments that make up the chaos infrastructure with cluster-wide scope or namespace-only scope. These deployments are mapped to a dedicated service account that can execute all supported chaos experiments for that scope. To learn more about connecting to a chaos infrastructure in cluster or namespace mode, refer to connect chaos infrastructures. Mapping deployments to dedicated service accounts is considered as the first level of blast radius control.
The permissions are listed below for reference.
The permissions listed an be tuned for further minimization based on environments connected, type of experiments needed etc. Refer to blast radius control using permissions to learn more.
| Resource | Permissions | Uses |
|---|---|---|
| deployments, replicationcontrollers, daemonsets, replicasets, statefulsets | get, list | For asset discovery of available resources on the cluster so that you can target them with chaos experiments. |
| secrets, configmaps | get, list | To read authentication information (cluster-id and access-keys), configuration tunables. |
| jobs | create, get, list, delete, deletecollection | Chaos experiments are launched as Kubernetes jobs. |
| pods, events | get, create, update, patch, delete, list, watch, deletecollectio |
|
| pod/logs | get, list, watch |
|
| nodes | patch, get, list, update |
|
| network policies | create, delete, list, get | Cause chaos through network partitions. |
| services | create, update, get, list, watch, delete, deletecollection |
|
| custom resource definitions, chaosengines, finalizers, chaosexperiments, chaosresults | get, create, update, patch, delete, list, watch, deletecollection | Lifecycle management of chaos custom resources in CE. |
| leases (CRDs) | get, create, list, update, delete | Enable high availability of chaos custom controllers via leader elections. |
Secrets management
HCE leverages secrets for administrative or management purposes as well as at runtime (during execution of chaos experiments). On the Harness control plane, secrets such as connector credentials and probe authentication keys are stored and encrypted by a secret manager. At runtime, the secrets that are injected into chaos pods within your own Kubernetes clusters are managed by you.
By default, control plane secrets are backed by the built-in Harness Secret Manager. You can also use an external secret manager to store and resolve these secrets. Go to Use an external secret manager to understand how this works.
Use an external secret manager
You can store the secrets that chaos experiments consume, such as connector credentials and APM or cloud probe authentication keys, in an external secret manager instead of the Harness Secret Manager. External secret managers are referenced exactly the same way as the Harness Secret Manager, so your existing experiments and probes do not change.
Until now, the Resilience Testing module could only use the Harness Secret Manager. You can now use external secret managers within Resilience Testing the same way you already use them across other Harness modules.
Harness Secret Manager compared with external secret managers
| Secret manager | Description | When to use |
|---|---|---|
| Harness Secret Manager | The secret manager built into Harness. | Use when you do not already operate your own secret manager to store credentials. |
| External secret manager | A third-party secret manager that you already operate, such as HashiCorp Vault, Google Cloud Secret Manager, or Azure Key Vault. | Use when you already store credentials in your own secret manager, which is the case for most teams. |
This is useful when you already manage credentials in your own secret manager and you want chaos experiments to resolve secrets from the same source as your other Harness modules. Harness provides comprehensive setup guidance for every supported option. Go to Secrets management to review all supported secret managers.
How it works:
- Chaos experiments that run through Harness Delegate use a dedicated chaos delegate task to decrypt secrets at runtime.
- The delegate resolves each referenced secret from whichever secret manager you configured for it, whether that is the Harness Secret Manager or an external one.
External secret manager support is behind the feature flag CHAOS_DEDICATED_DELEGATE_TASK. Contact Harness Support to enable it for your account. When the flag is enabled, chaos workflows that use the Harness NG Manager /chaos/... endpoints start using the dedicated chaos delegate task.
All secret managers that Harness supports work with chaos experiments. Support has been validated with HashiCorp Vault and Google Cloud KMS.
To set up a secret manager and add secrets, go to Harness Secret Manager overview to use the built-in option. To connect an external secret manager, go to Add HashiCorp Vault or Add a Google KMS secret manager.
Secrets to access chaos artifact (Git) repositories
Git-based ChaosHubs have been removed. The Git connector and PAT/SSH key setup described below is no longer required for new deployments. Use Templates and Resilience Probes to manage reusable chaos artifacts instead.
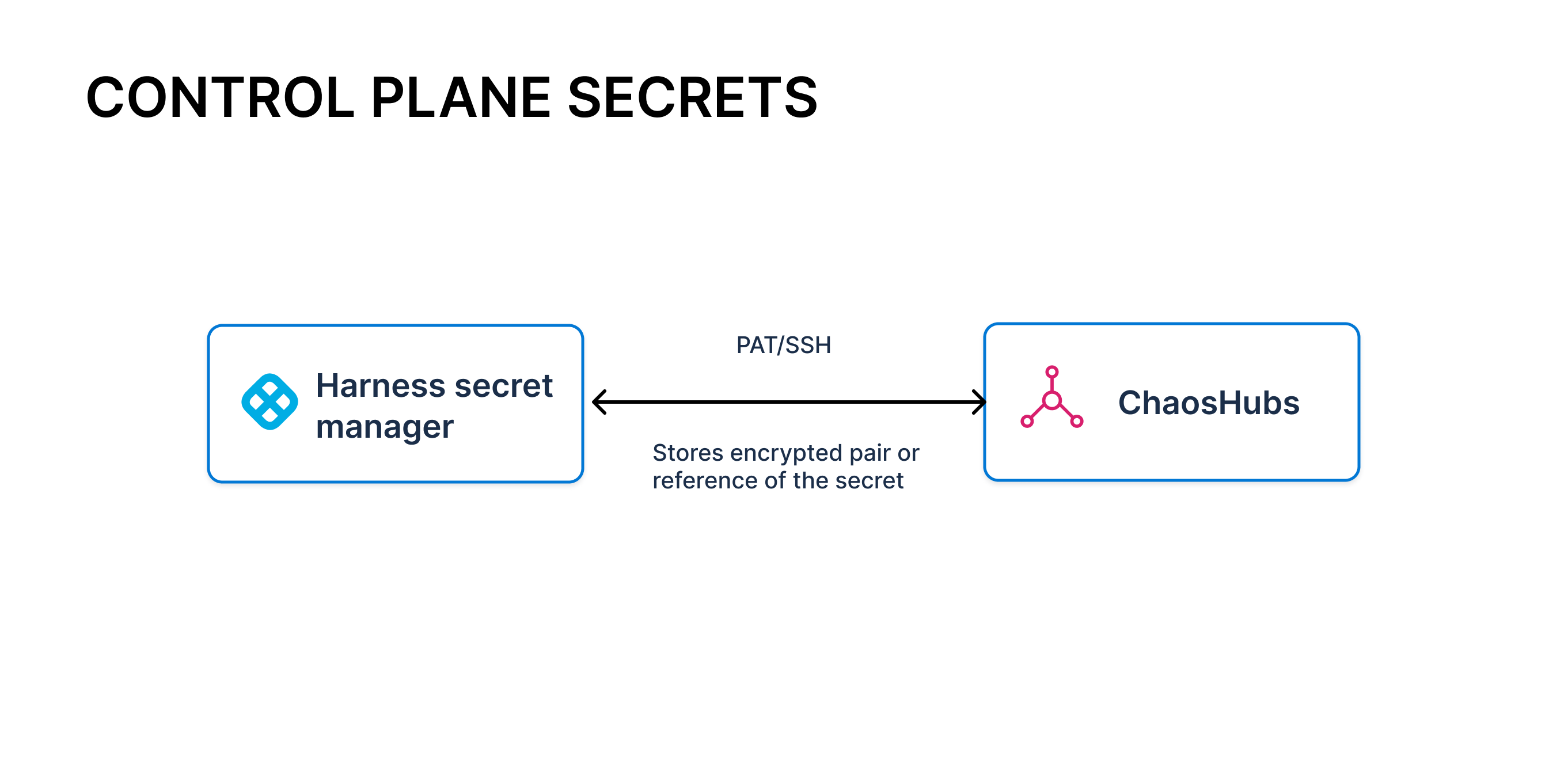
HCE previously allowed you to add one or more ChaosHubs to enable users to select stored chaos artifacts such as fault and experiment templates. Setting up a chaos hub involved connecting to a Git repository by using Personal Access Tokens (PAT) or SSH keys.
The chaos module leveraged the native Git Connectors provided by the Harness platform to achieve this connectivity, which in turn leveraged the Harness Secret Manager to store the PAT or SSH keys.
Secrets to access and inject chaos on public and on-prem cloud resources
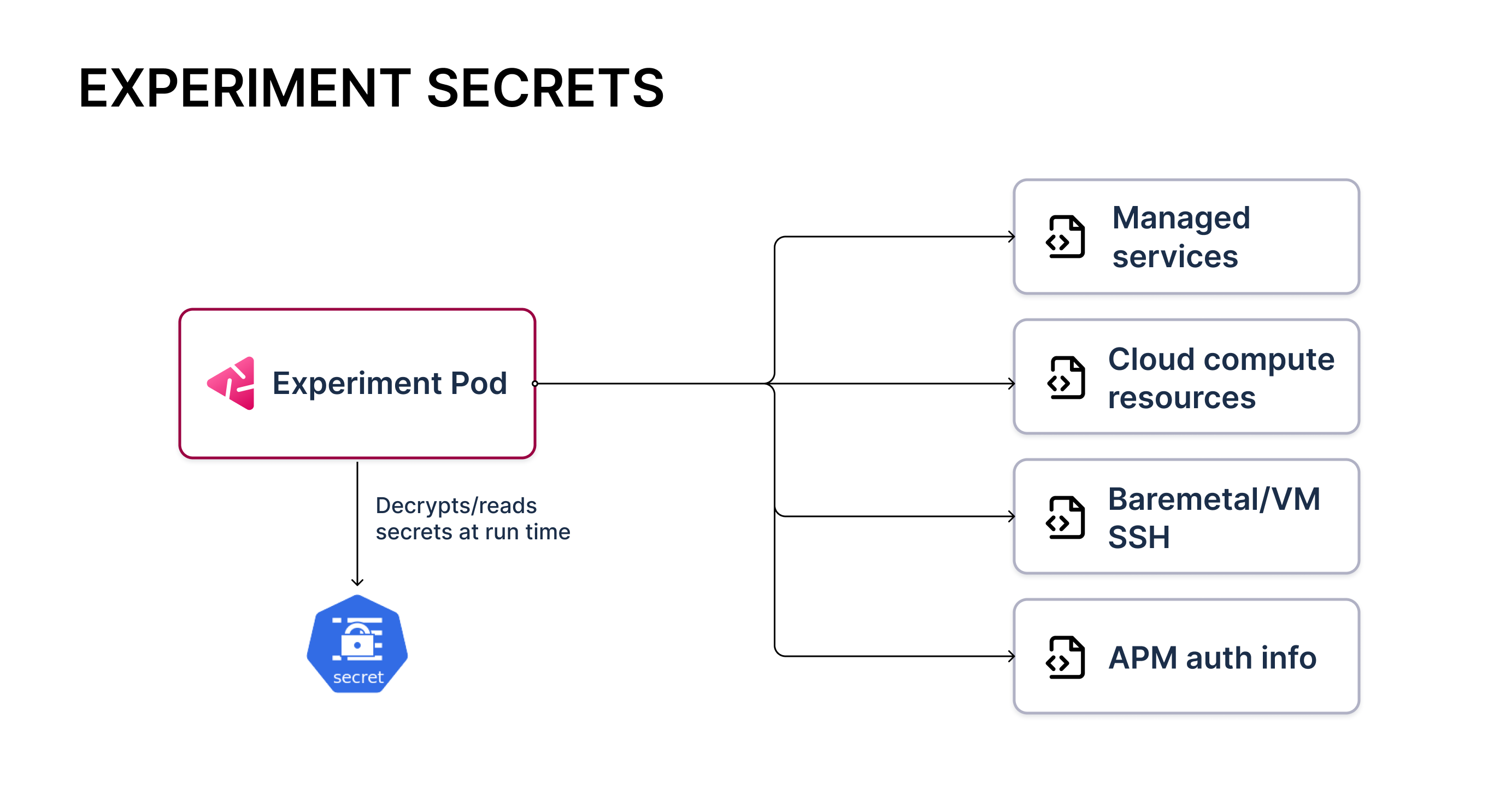
HCE supports fault injection into non-Kubernetes resources such as on-premises VMs, bare-metal machines, cloud infrastructure resources (compute, storage, and network), and cloud-managed services. It leverages provider-specific APIs to inject chaos.
Additionally, HCE supports custom validation tasks such as retrieving metrics from an APM, making API calls for health status, and running background processes for data integrity.
Both of the aforementioned actions require specific access to the infrastructure or service in question. This information is expected to be fed as Kubernetes secrets to the transient chaos pod resources that are launched during experiment execution. To learn more about how experiments are executed, go to chaos architecture.
The experiment artifact that is stored in a chaos hub or supplied when you create an experiment only references the names of secrets. You can fully manage the life cycle of the secrets within their clusters.
Here is an example of AWS access information being fed to the experiment pods through a Kubernetes secret.
Blast radius control using permissions
You can fine-tune permissions to suit specific infrastructures and experiments if you want to reduce the blast radius and impact from a security perspective. This applies to both Kubernetes-based and non-Kubernetes chaos.
In the case of the Kubernetes chaos, a lower blast radius is achieved through service accounts mapped to custom roles instead of the default service accounts mentioned in the Kubernetes roles for chaos infrastructure. For non-Kubernetes chaos, a lower blast radius is achieved through cloud-specific role definitions (for example, IAM) mapped to the user account.
Every fault in the Enterprise chaos hub publishes the permissions that you need to execute the fault. You can tune your roles. Common permission templates that work as subsets or supersets for a specific category of experiments are also available. For example, AWS resource faults.