Nexus IQ scanner reference for STO
You can scan your code repositories and ingest results from Nexus IQ.
For more information
The following topics contain useful information for setting up scanner integrations in STO:
Security step settings for Nexus scans in STO
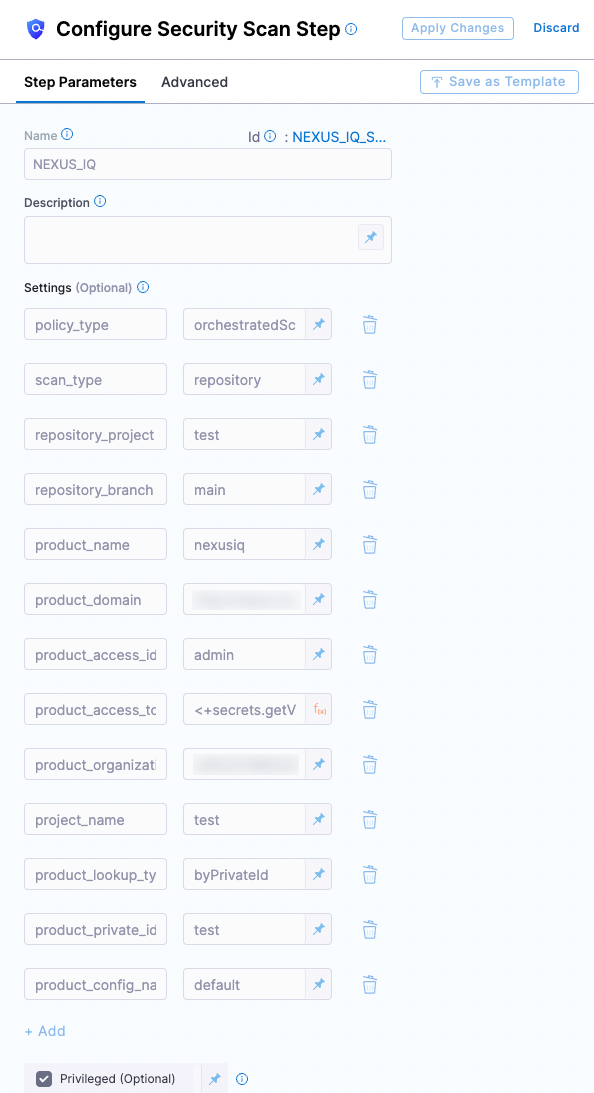
Nexus configuration in a Security step
Target and variant
The following settings are required for every Security step:
target_nameA user-defined label for the code repository, container, application, or configuration to scan.variantA user-defined label for the branch, tag, or other target variant to scan.
Make sure that you give unique, descriptive names for the target and variant. This makes navigating your scan results in the STO UI much easier.
You can see the target name, type, and variant in the Test Targets UI:
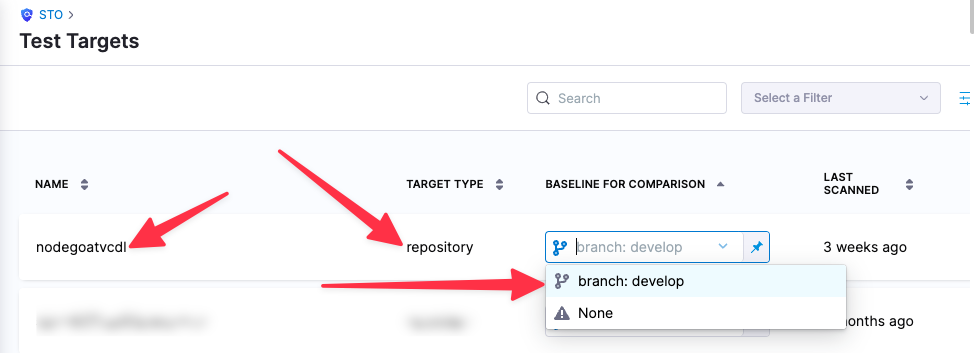
For more information, go to Targets, baselines, and variants in STO.
Nexus scan settings
product_name=nexusiqscan_type=repositorypolicy_type=orchestratedScanordataLoad- When
policy_typeis set toorchestratedScan:product_domain— The URL of your NexusIQ instance.product_access_id— The password used to log in to the NexusIQ UI.product_access_token— The password used to log in to the NexusIQ UI. (This is not an API access token.)product_organization_id— The organization defined in Nexus. You can use the Organzations API to get a list of all your organizations.product_project_name— The application ID of the Nexus application. This also corresponds toapplication-idused in the NexusIQ CLI.product_lookup_type- accepted value(s):
byPrivateId,byPublicId
- accepted value(s):
- When
product_lookup_typeis set tobyPublicId:- product_public_id
- When
product_lookup_typeis set tobyPrivateId:- product_private_id
product_config_name- Accepted values(s):
default
- Accepted values(s):
fail_on_severity- See Fail on Severity.
Ingestion file
If the policy_type is ingestionOnly:
ingestion_file= The path to your scan results when running an Ingestion scan, for example/shared/scan_results/myscan.latest.sarif.
-
The data file must be in a supported format for the scanner.
-
The data file must be accessible to the scan step. It's good practice to save your results files to a shared path in your stage. In the visual editor, go to the stage where you're running the scan. Then go to Overview > Shared Paths. You can also add the path to the YAML stage definition like this:
- stage:
spec:
sharedPaths:
- /shared/scan_results
Fail on Severity
Every Security step has a Fail on Severity setting. If the scan finds any vulnerability with the specified severity level or higher, the pipeline fails automatically. You can specify one of the following:
CRITICALHIGHMEDIUMLOWINFONONE— Do not fail on severity
The YAML definition looks like this: fail_on_severity : critical # | high | medium | low | info | none