Diagnostics
Diagnostics helps you validate data accuracy, monitor data ingestion, and troubleshoot integration related issues in the application. It provides visibility into data ingestion status, progress, and alerts to ensure the SEI system is healthy and has the latest data updated.
Primary scenarios
Use SEI Diagnostics if you need to:
- Compare data between Jira or supported SCM tools and SEI and verify the accuracy and completeness of ingested data
- Track real-time status of all integrations and view the summary of data ingested from each source.
- Identify and resolve integration misconfigurations
- Investigate missing tickets, commits, or pull request data in SEI reports
- Monitor status and progress of data ingestion jobs
- Receive alerts for anomalies or issues in the ingestion process
- Issue Management: Jira by Atlassian
- Source Control Management (SCM): All SCM integrations supported by SEI
System status
The System Status overview provides a centralized view of your SEI system's health, specifically focusing on the ingestion jobs and satellite connectivity. Here's a breakdown of what each section covers:
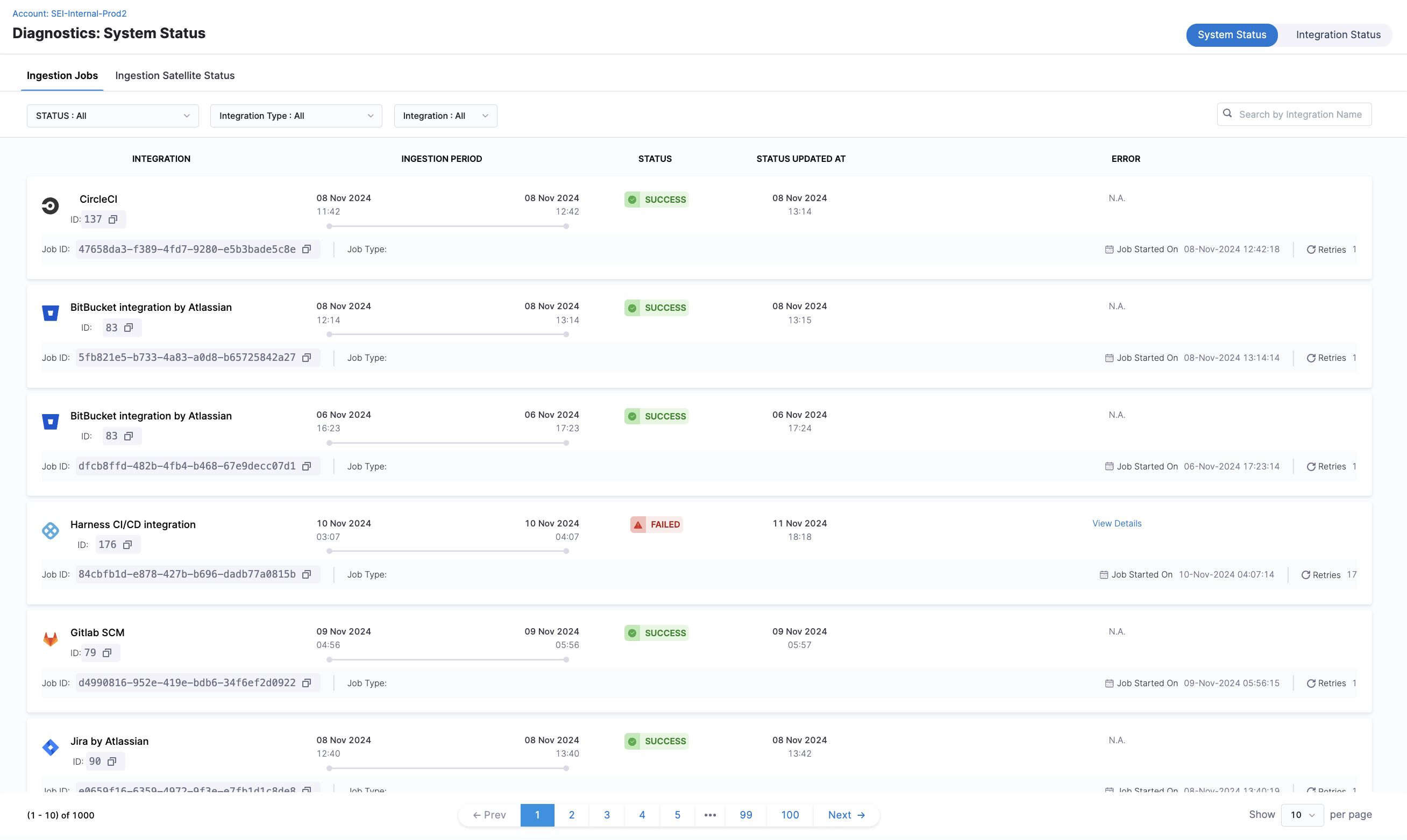
Injestion Jobs
Ingestion jobs retrieve data from integrated platforms. For each job, the following details are available:
- Integration ID: Identify the specific integration source, helpful for multi-platform environments.
- Ingestion Period: Tracks the duration of each job to assess efficiency and detect any unusually long processes.
- Status: Shows if the job was successful or failed, with a timestamp for the last update.
- Error Logs: In case of a failure, the logs provide insights into the cause and any associated errors for troubleshooting.
Common error logs
Below are examples of errors you might find in the error logs, along with causes and potential fixes:
401/403 Unauthorized Access
- Cause: The token provided was invalid, resulting in failure to access project data or certain API endpoints.
- Solution: Confirm the token validity and if the token has expired, update the integration configuration by reauthenticating with the third-party platform. Ensure the integration is configured with correct credentials.
- If the error persists, reach out to support with these details for further investigation.
Note that if you're using the Azure DevOps integration, 203 also reflects issue with the access token being expired.
Stream Exception
This error happens when data fetching from paginated endpoints fails midstream. It can result from:
- Authorization issues (e.g., expired or invalid tokens).
- Misconfigurations in settings (e.g., exceeding data limits).
Solution
- Verify API Token: Go to your SEI integration settings and confirm that the API token is valid and hasn’t expired. Generate a new token if needed and reauthenticate, especially if the integration has been recently reconfigured.
- Check Permissions: Ensure the user or service account associated with the integration has the necessary permissions to access the data.
- Review integration settings: If you’re pulling large volumes of data from GitHub / Jira, try reconfiguring the integration using multiple access tokens in the integration’s configuration (e.g., 4-5 PATs for a data size of 20k+ repositories in GitHub) to manage data limits better.
- If the error persists, reach out to support with the details for further investigation.
IOException
An IOException occurs when network connectivity issues prevent data retrieval, even after multiple retries. This can be due to:
- Network outages or intermittent connectivity.
- Endpoint downtime
Solution
- Test Connectivity: Check if you can access the API endpoints directly from your network (e.g., using a curl command). This will help determine if the endpoint is down or if there are network issues preventing access.
- Verify Network Settings: Confirm that any firewall or proxy settings are allowing traffic to the endpoint. If you're using a cloud-based integration with allowlist settings in the third-party account or if you're utilizing an ingestion satellite, confirm that Harness IP addresses are allowlisted to avoid access restrictions.
- If the error persists, reach out to support with the details for further investigation.
429 Rate Limiting
This error occurs when the integration is sending too many requests to the API within a given time frame. This is typically caused by a large set of data being ingested using one integration exceeding the API rate limit.
Solution
If you're using a PAT (Personal Access Token) or API Key for authentication, try reauthenticating the integration with multiple access tokens for different service accounts. This can help distribute the request load and reduce the likelihood of hitting rate limits. If the error persists, reach out to support with the details for further investigation.
Ingestion satellite status
Monitor the health of ingestion satellites for on-prem integration setups.

The following details are displayed:
- Satellite ID: Unique identifier for the ingestion satellite.
- Status: Current health status (e.g., Healthy).
- Status Updated At: The most recent timestamp of when the status was last updated.
- Memory (MB): Current memory usage versus allocated memory.
- CPU (Cores): The number of CPU cores currently in use by the satellite.
- Version: Installed satellite software version.
- Integrations: The integration IDs where the satellite is actively used
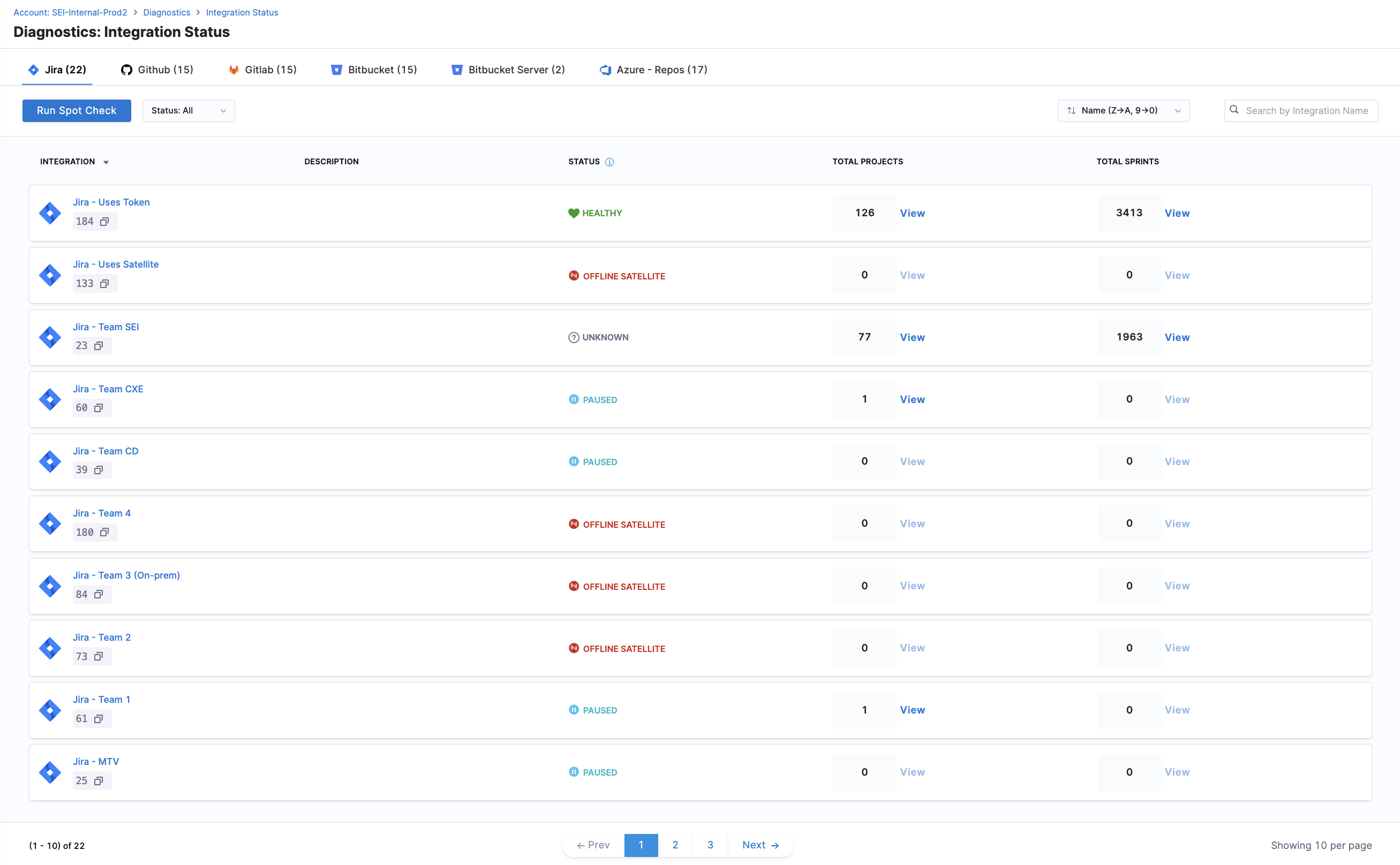
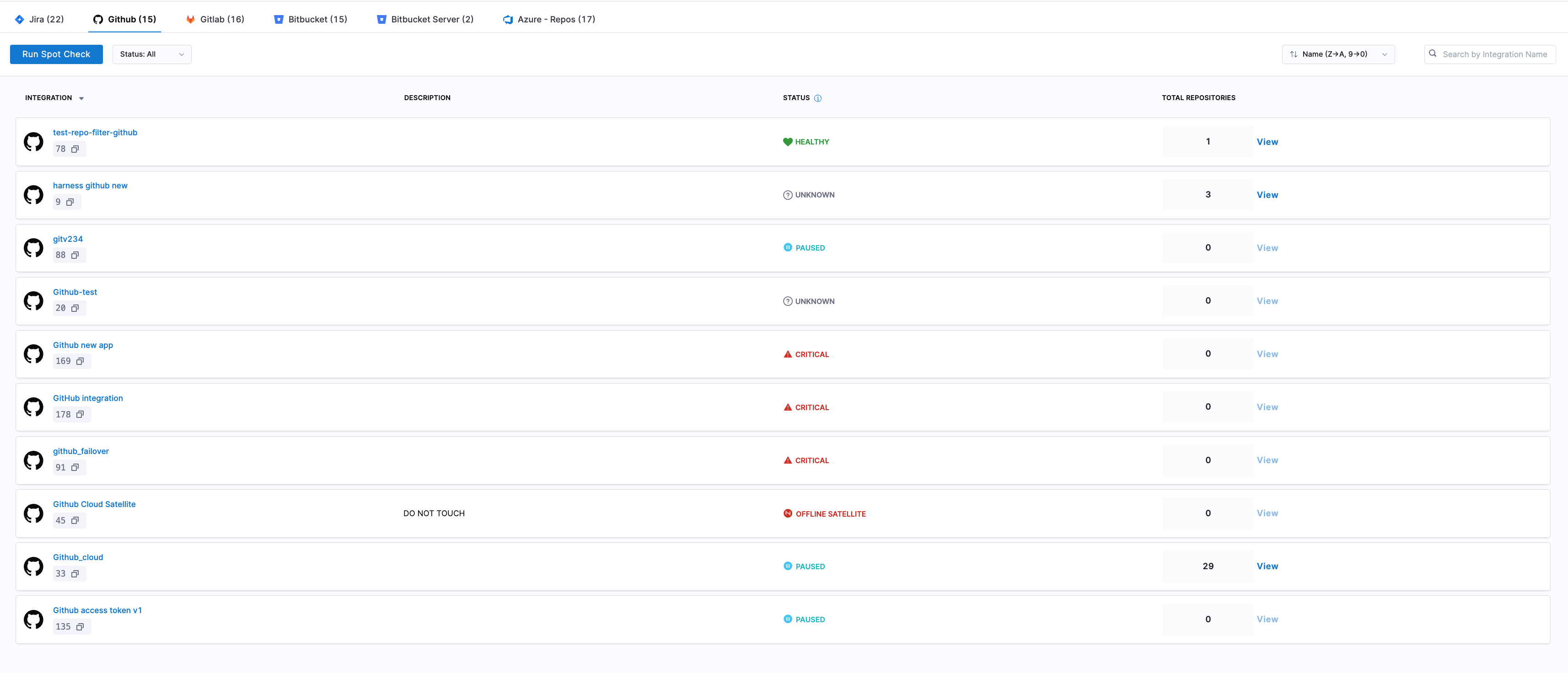
Integration status
The Integration Status page is a central dashboard designed to help you monitor, manage, and troubleshoot all your integrations effectively. This page provides a real-time health check on data ingestion status, allowing you to identify potential data discrepancies across different integrations quickly.
Overview
Each integration displays essential information:
- Integration Name, ID, and Description: Unique identifiers for easy identification across multiple integration instances.
- Current Status: Real-time health indicator, showing the latest ingestion state.
Status labels and recommended actions
Each integration is labeled with a specific status based on recent ingestion activity. Below are the statuses, their meanings, and recommended actions:
| Status | Description | What It Means For You | Recommended Action |
|---|---|---|---|
| HEALTHY | All ingestion jobs successful in the past week | Your integration is working optimally | Continue regular monitoring |
| CRITICAL | No successful ingestion jobs in the past week | Data is not being updated, immediate attention required | Check credentials and connectivity |
| NEEDS ATTENTION | Some failed ingestion jobs in the past week | Partial data loss may be occurring | Review error logs and recent changes |
| OFFLINE SATELLITE | No recent ingestion jobs and no active satellite | Integration agent is not communicating | Verify satellite configuration and network status |
| PAUSED | Integration ingestion manually paused | No new data is being collected (intentional) | Contact Harness Support to resume when ready to continue data ingestion |
| UNKNOWN | No recent ingestion jobs or unspecified issues | System cannot determine integration health | Check integration requirements and configuration |
View details
Each integration provides unique data points based on its setup and usage. For example, the Jira Integration section includes details on the Projects and Sprints ingested into the system, while Source Code Management (SCM) integrations provide a summary of repository ingestion across all integrations.
- View Jira Data
- View Other Source Code Managers Data
The integration status page for Jira displays the total count of Projects and Sprints ingested as part of the Jira integrations.
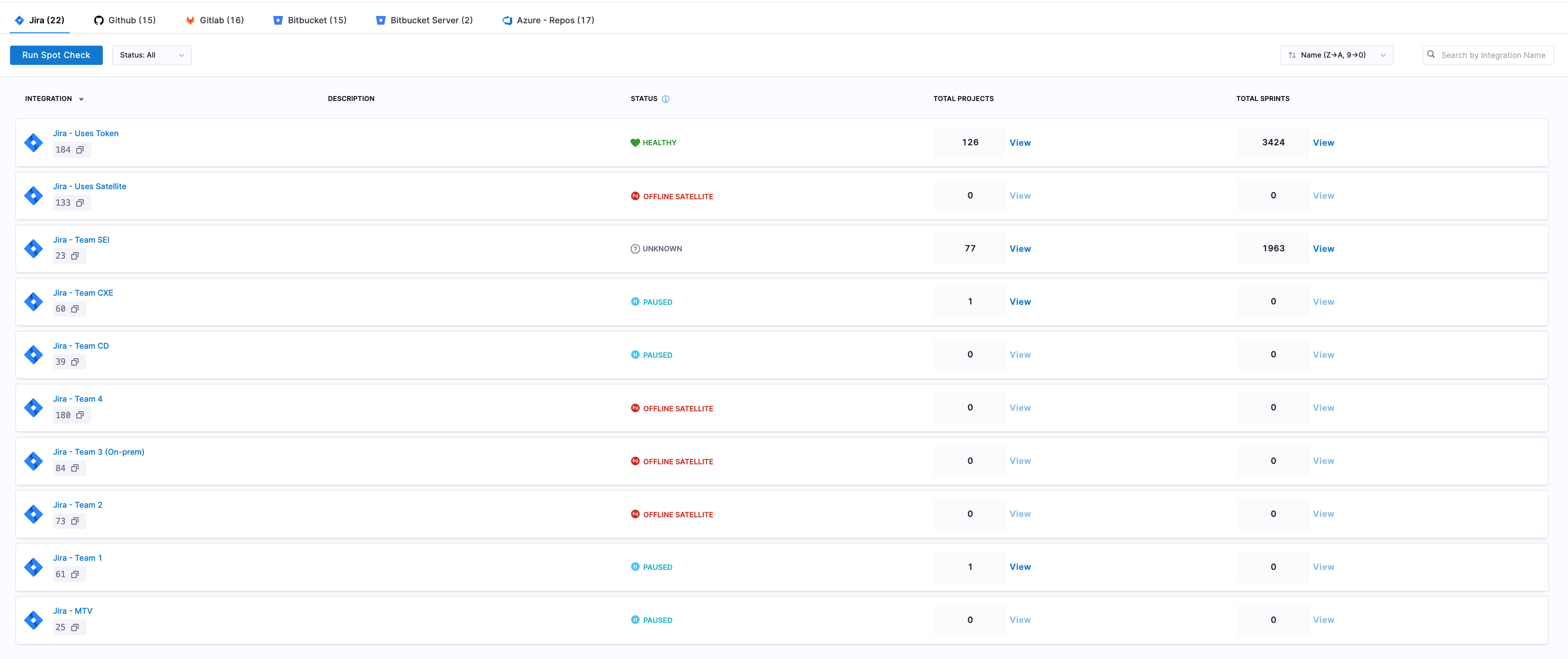
For each ingested project, the following information is provided:
- Total Issues Count: The number of issues ingested for the project.
- Newest Issue Creation Date and Time: The timestamp of the most recently created issue.
- All Issues View: Displays all ingested issues for easy verification of data accuracy.
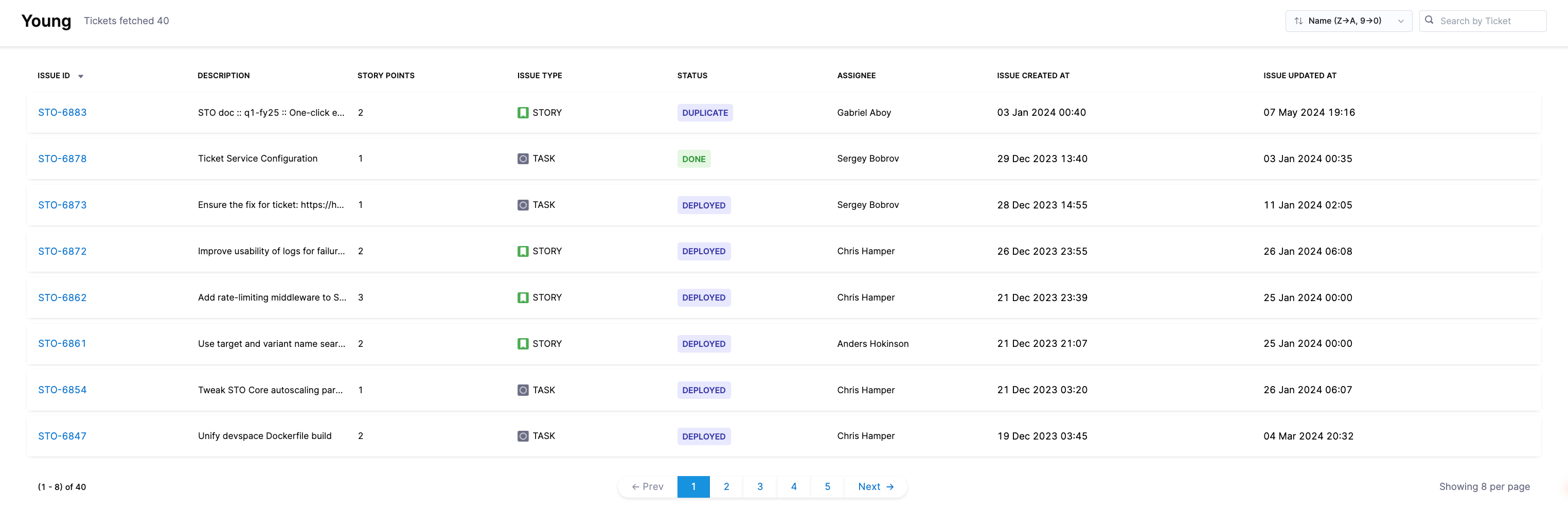
For each ingested issue, the following details are shown:
- Story Points Allocated: Total story points assigned to the issue.
- Issue Type: Categorization of the issue (e.g., Bug, Task, Story).
- Assignee: Person responsible for the issue.
- Issue Created At: Date and time the issue was created.
- Last Issue Update: Timestamp of the last update to the issue.
You can use the Filter and Search by Ticket ID feature to locate specific issues. To identify projects with missing data, enable Show Only Projects with 0 Issues to display projects with no ingested issues.

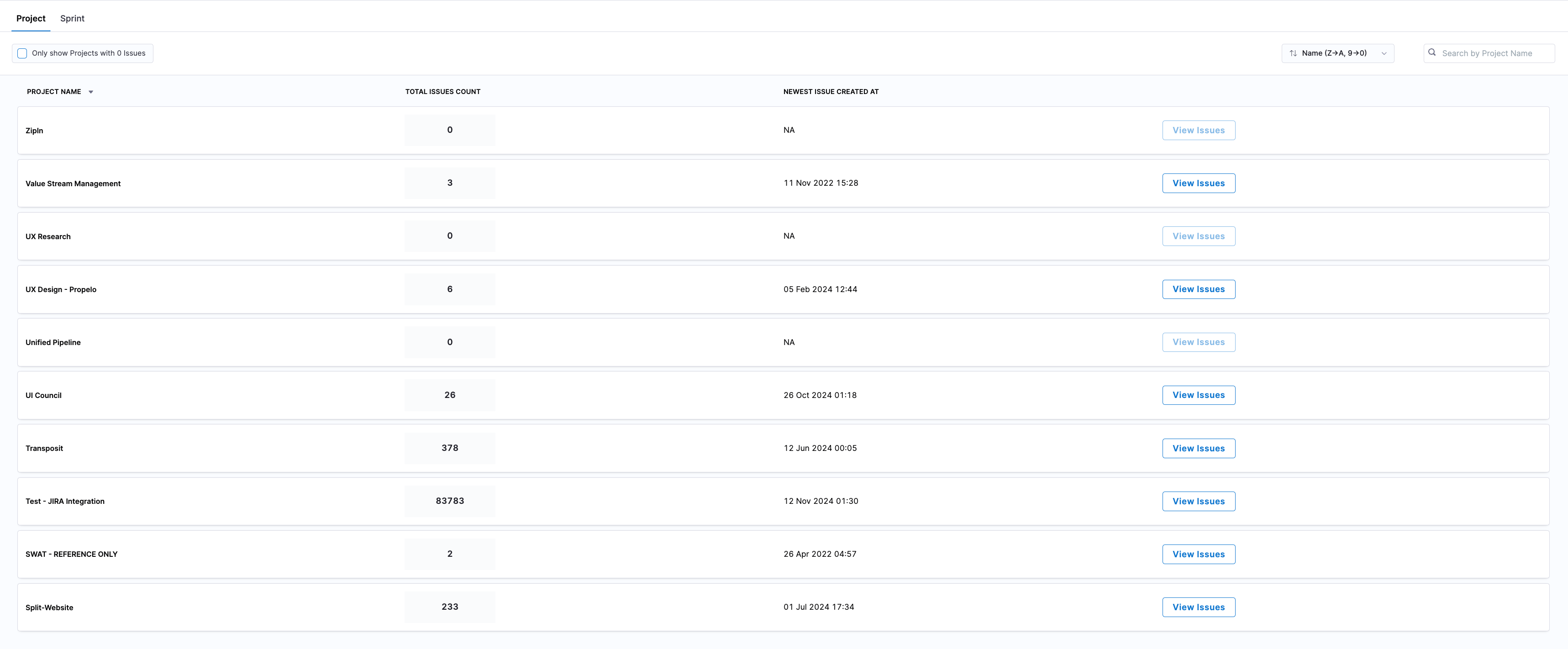
For each ingested sprint, the following metrics are displayed:
- Sprint Name
- Start Date and End Date: The timeline for the sprint.
- Committed Story Points: Total story points planned for completion.
- Delivered Story Points: Actual story points delivered by the sprint’s end.
- Total Issues Count: The number of issues that was part of the sprint.
- Latest Issue Created Date: The most recent creation date among issues in the sprint.
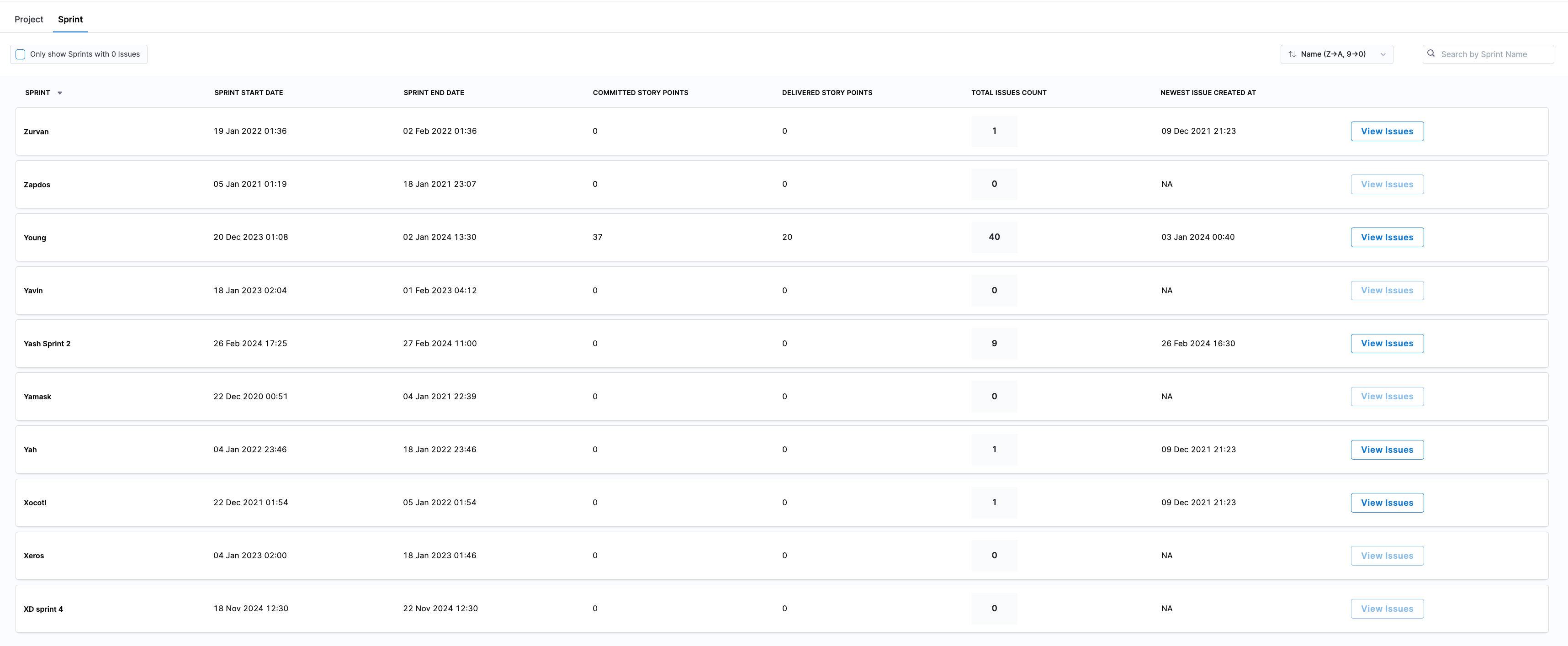
In addition, each sprint shows all associated issues, with the following details for each:
- Story Points Allocated: Story points assigned to each issue.
- Issue Type: Type of issue (e.g., Bug, Task, Story).
- Status: Current status of the issue.
- Assignee: Contributor assigned to the issue.
- Issue Created At: Date the issue was created.
- Last Issue Update: Date of the latest update to the issue.
The integration status page for SCM provides an overview of the ingestion data for repositories. It displays the total count of repositories and allows you to access detailed information to monitor repository activity and troubleshoot data discrepancies.
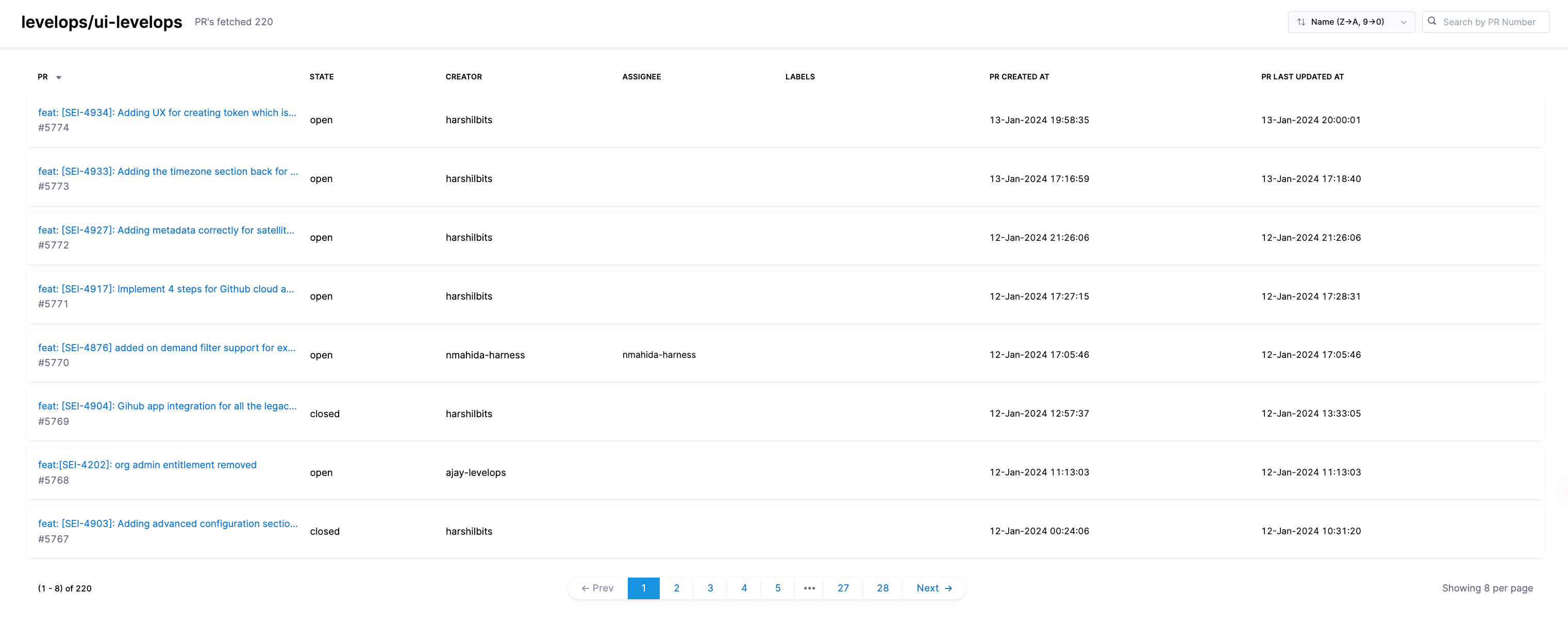
The status page shows the total count of repositories ingested as part of each SCM integration. Click on the View button for detailed information about each repository:
- Repository Name: Name of each repository.
- Total Commits: The total number of commits made in the repository.
- Total Pull Requests (PRs): The total number of PRs submitted.
- Newest PR Created Time (UTC): Date and time of the latest PR creation.

Click View PRs to access details on each pull request:
- All PRs: Lists all pull requests for the repository.
- Current State: The current status of each PR (e.g., Open, Closed, Merged).
- Creator: The user who created the PR.
- Assignee: The Assignee field displays data from GitHub’s assignee field, showing the person or people assigned to contribute on the pull request.
- Labels: Any labels applied to the PR.
- Created At: Date and time the PR was created.
- Last Updated: The most recent date and time the PR was updated.
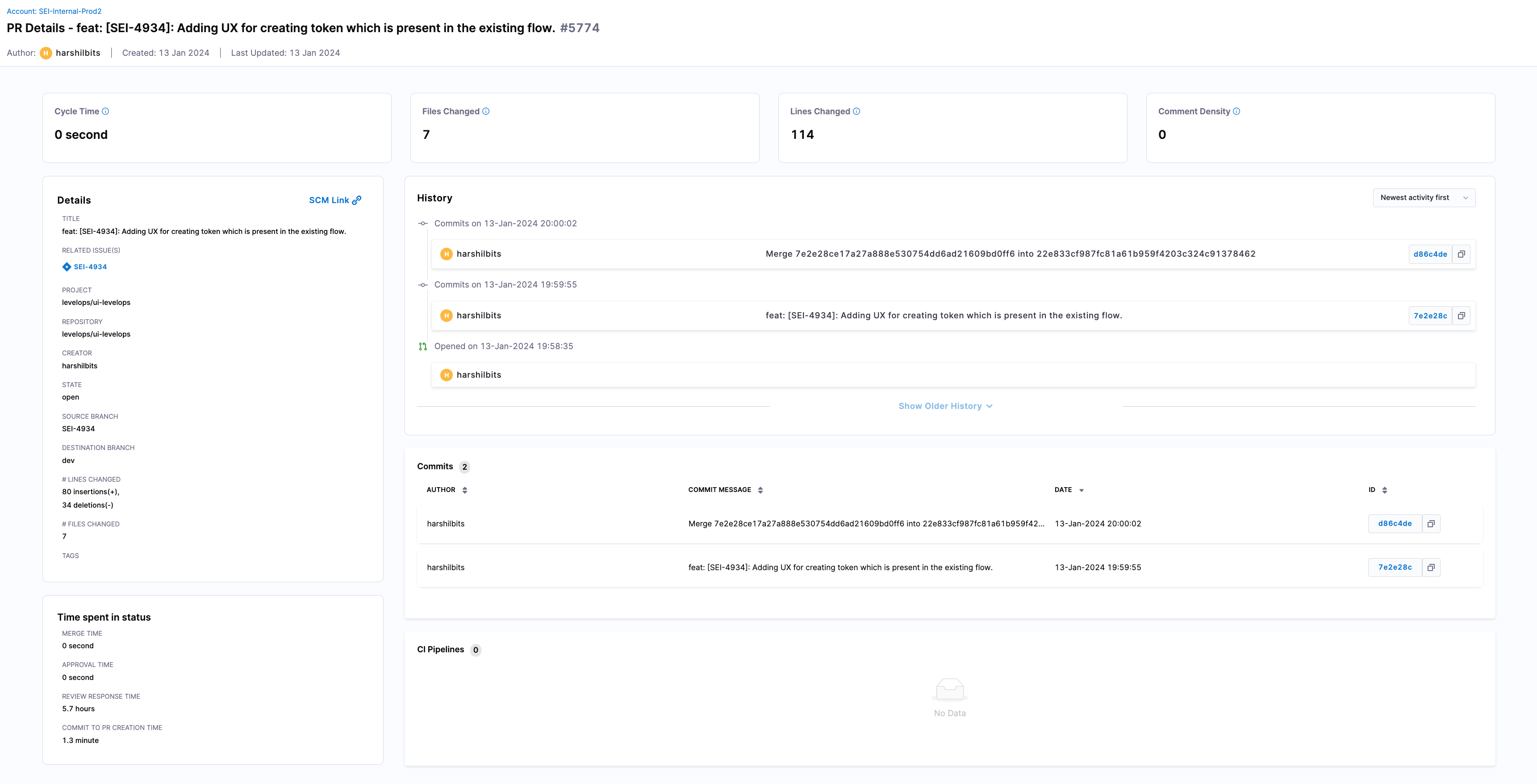
Clicking on a PR title opens a detailed PR Details page, displaying:
- Cycle Time: The total time from PR creation to merge or closure.
- Files Changed: A list of all files modified in the PR.
- Lines Changed: The total lines of code added or removed.
- Comment Density: The frequency of comments within the PR.
- PR History: A timeline of significant PR events (e.g., status changes).
- Associated Commits: All commits linked to the PR.
- CI Pipelines: Any continuous integration pipelines related to the PR.
- Time Spent in Status: A breakdown of time spent in each PR stage, along with other specific PR details.
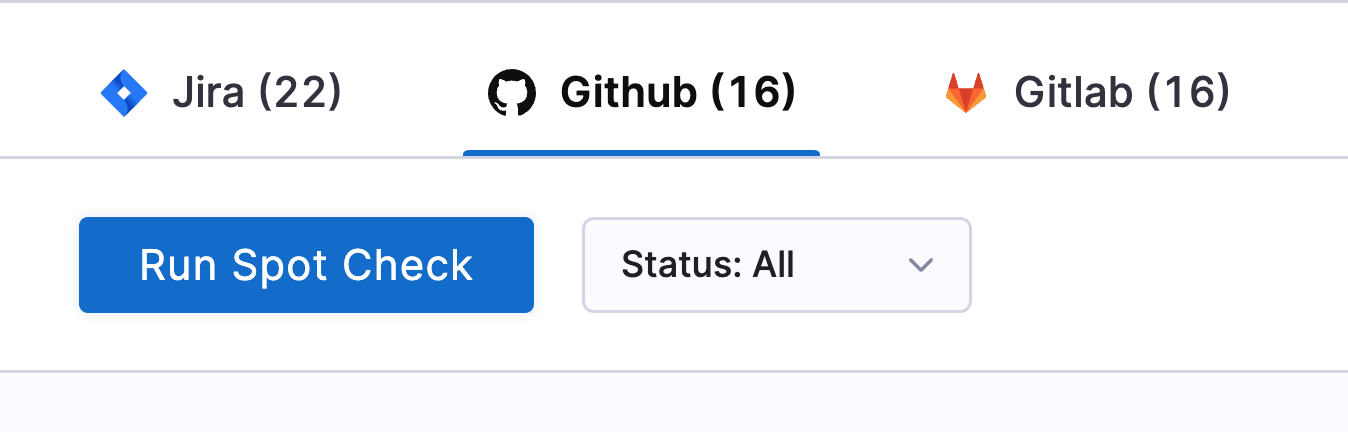
Run spot check
The Run Spot Check feature allows you to quickly verify whether specific data items, such as Jira issues (by ticket key) or pull requests (by PR ID and repository name), have been successfully ingested into the SEI system.
When you run a search, the system scans its internal storage and retrieves the requested item if it exists in SEI. This feature is especially useful for cross-checking data between Harness SEI and other tools, ensuring that all relevant data has been correctly ingested and is available for analysis.