Continuous Integration (CI) FAQs
Build infrastructure
What is build infrastructure and why do I need it for Harness CI?
A build stage's infrastructure definition, the build infrastructure, defines "where" your stage runs. It can be a Kubernetes cluster, a VM, or even your own local machine. While individual steps can run in their own containers, your stage itself requires a build infrastructure to define a common workspace for the entire stage. For more information about build infrastructure and CI pipeline components go to:
What kind of build infrastructure can I use? Which operating systems are supported?
For support operating systems, architectures, and cloud providers, go to Which build infrastructure is right for me.
Can I use multiple build infrastructures in one pipeline?
Yes, each stage can have a different build infrastructure. Additionally, depending on your stage's build infrastructure, you can also run individual steps on containers rather than the host. This flexibility allows you to choose the most suitable infrastructure for each part of your CI pipeline.
I have a MacOS build, do I have to use homebrew as the installer?
No. Your build infrastructure can be configured to use whichever tools you like. For example, Harness Cloud build infrastructure includes pre-installed versions of xcode and other tools, and you can install other tools or versions of tools that you prefer to use. For more information, go to the CI macOS and iOS development guide.
What's the difference between CI_MOUNT_VOLUMES, ADDITIONAL_CERTS_PATH, and DESTINATION_CA_PATH?
CI_MOUNT_VOLUMES - An environment variable used for CI Build Stages. This variable should be set to a comma-separated list of source:destination mappings for certificates where source is the certificate path on the delegate, and destination is the path where you want to expose the certificates on the build containers. For example,
- name: CI_MOUNT_VOLUMES
value: "/tmp/ca.bundle:/etc/ssl/certs/ca-bundle.crt,/tmp/ca.bundle:/kaniko/ssl/certs/additional-ca-cert-bundle.crt"
ADDITIONAL_CERTS_PATH - An environment variable used for CI Build Stages. This variable should be set to the path where the certificates exist in the delegate. For example,
- name: ADDITIONAL_CERTS_PATH
value: "/tmp/ca.bundle"
DESTINATION_CA_PATH - An environment variable used for CI Build Stages. This variable should be set to a comma-separated list of files where the certificate should be mounted. For example,
- name: DESTINATION_CA_PATH
value: "/etc/ssl/certs/ca-bundle.crt,/kaniko/ssl/certs/additional-ca-cert-bundle.crt"
ADDTIONAL_CERTS_PATH and CI_MOUNT_VOLUMES work in tandem to ensure certificates are mounted on the Kubernetes Build Infrastructure, whereas DESTINATION_CA_PATH does not require other environment variables to mount certificates. Instead, DESTINATION_CA_PATH relies on the certificate being mounted at /opt/harness-delegate/ca-bundle in order to copy the certificate to the provided comma-separated list of file paths.
DESTINATION_CA_PATH and ADDTIONAL_CERTS_PATH/CI_MOUNT_VOLUMES both perform the same operation of mounting certificates to Kubernetes Build Infrastructure. Harness recommends DESTINATION_CA_PATH over ADDTIONAL_CERTS_PATH/CI_MOUNT_VOLUMES however, if both are defined, DESTINATION_CA_PATH will be consumed over ADDTIONAL_CERTS_PATH/CI_MOUNT_VOLUMES.
For more information and instructions on how to mount certificates, please visit the Configure a Kubernetes build farm to use self-signed certificates documentation.
Local runner build infrastructure
Can I run builds locally? Can I run builds directly on my computer?
Yes. For instructions, go to Set up a local runner build infrastructure.
How do I check the runner status for a local runner build infrastructure?
To confirm that the runner is running, send a cURL request like curl http://localhost:3000/healthz.
If the running is running, you should get a valid response, such as:
{
"version": "0.1.2",
"docker_installed": true,
"git_installed": true,
"lite_engine_log": "no log file",
"ok": true
}
How do I check the delegate status for a local runner build infrastructure?
The delegate should connect to your instance after you finish the installation workflow above. If the delegate does not connect after a few minutes, run the following commands to check the status:
docker ps
docker logs --follow <docker-delegate-container-id>
The container ID should be the container with image name harness/delegate:latest.
Successful setup is indicated by a message such as Finished downloading delegate jar version 1.0.77221-000 in 168 seconds.
Runner can't find an available, non-overlapping IPv4 address pool.
The following runner error can occur during stage setup (the Initialize step in build logs):
Could not find an available, non-overlapping IPv4 address pool among the defaults to assign to the network.
This error means the number of Docker networks has exceeded the limit. To resolve this, you need to clean up unused Docker networks. To get a list of existing networks, run docker network ls, and then remove unused networks with docker network rm or docker network prune.
Docker daemon fails with invalid working directory path on Windows local runner build infrastructure
The following error can occur in Windows local runner build infrastructures:
Error response from daemon: the working directory 'C:\harness-DIRECTORY_ID' is invalid, it needs to be an absolute path
This error indicates there may be a problem with the Docker installation on the host machine.
-
Run the following command (or a similar command) to check if the same error occurs:
docker run -w C:\blah -it -d mcr.microsoft.com/windows/servercore:ltsc2022 -
If you get the
working directory is invaliderror again, uninstall Docker and follow the instructions in the Windows documentation to Prepare Windows OS containers for Windows Server. -
Restart the host machine.
How do I check if the Docker daemon is running in a local runner build infrastructure?
To check if the Docker daemon is running, use the docker info command. An error response indicates the daemon is not running. For more information, go to the Docker documentation on Troubleshooting the Docker daemon
Runner process quits after terminating SSH connection for local runner build infrastructure
If you launch the Harness Docker Runner binary within an SSH session, the runner process can quit when you terminate the SSH session.
To avoid this with macOS runners, use this command when you start the runner binary:
./harness-docker-runner-darwin-amd64 server >log.txt 2>&1 &
disown
For Linux runners, you can use a tool such as nohup when you start the runner, for example:
nohup ./harness-docker-runner-darwin-amd64 server >log.txt 2>&1 &
Where does the harness-docker-runner create the hostpath volume directories on macOS?
The harness-docker-runner creates the host volumes under /tmp/harness-* on macOS platforms.
Why do I get a "failed to create directory" error when trying to run a build on local build infra?
failed to create directory for host volume path: /addon: mkdir /addon: read-only file system
This error could occur when there's a mismatch between the OS type of the local build infrastructure and the OS type selected in the pipeline's infrastructure settings. For example, if your local runner is on a macOS platform, but the pipeline's infrastructure is set to Linux, this error can occur.
Is there an auto-upgrade feature for the Harness Docker runner?
No. You must upgrade the Harness Docker runner manually.
Self-managed VM build infrastructure
Can I use the same build VM for multiple CI stages?
No. The build VM terminates at the end of the stage and a new VM is used for the next stage.
Why are build VMs running when there are no active builds?
With self-managed VM build infrastructure, the pool value in your pool.yml specifies the number of "warm" VMs. These VMs are kept in a ready state so they can pick up build requests immediately.
If there are no warm VMs available, the runner can launch additional VMs up to the limit in your pool.yml.
If you don't want any VMs to sit in a ready state, set your pool to 0. Note that having no ready VMs can increase build time.
For AWS VMs, you can set hibernate in your pool.yml to hibernate warm VMs when there are no active builds. For more information, go to Configure the Drone pool on the AWS VM.
Do I need to install Docker on the VM that runs the Harness Delegate and Runner?
Yes. Docker is required for self-managed VM build infrastructure.
AWS build VM creation fails with no default VPC
When you run the pipeline, if VM creation in the runner fails with the error no default VPC, then you need to set subnet_id in pool.yml.
AWS VM builds stuck at the initialize step on health check
If your CI build gets stuck at the initialize step on the health check for connectivity with lite engine, either lite engine is not running on your build VMs or there is a connectivity issue between the runner and lite engine.
- Verify that lite-engine is running on your build VMs.
- SSH/RDP into a VM from your VM pool that is in a running state.
- Check whether the lite-engine process is running on the VM.
- Check the cloud init output logs to debug issues related to startup of the lite engine process. The lite engine process starts at VM startup through a cloud init script.
- If lite-engine is running, verify that the runner can communicate with lite-engine from the delegate VM.
- Run
nc -vz <build-vm-ip> 9079from the runner. - If the status is not successful, make sure the security group settings in
runner/pool.ymlare correct, and make sure your security group setup in AWS allows the runner to communicate with the build VMs. - Make sure there are no firewall or anti-malware restrictions on your AMI that are interfering with the cloud init script's ability to download necessary dependencies. For details about these dependencies, go to Set up an AWS VM Build Infrastructure - Start the runner.
- Run
AWS VM delegate connected but builds fail
If the delegate is connected but your AWS VM builds are failing, check the following:
- Make sure your the AMIs, specified in
pool.yml, are still available.- Amazon reprovisions their AMIs every two months.
- For a Windows pool, search for an AMI called
Microsoft Windows Server 2022 Base with Containersand updateamiinpool.yml.
- Confirm your security group setup and security group settings in
runner/pool.yml.
Use internal or custom AMIs with self-managed AWS VM build infrastructure
If you are using an internal or custom AMI, make sure it has Docker installed.
Additionally, make sure there are no firewall or anti-malware restrictions interfering with initialization, as described in CI builds stuck at the initialize step on health check.
Where can I find logs for self-managed AWS VM lite engine and cloud init output?
- Linux
- Lite engine logs:
/var/log/lite-engine.log - Cloud init output logs:
/var/log/cloud-init-output.log
- Lite engine logs:
- Windows
- Lite engine logs:
C:\Program Files\lite-engine\log.out - Cloud init output logs:
C:\ProgramData\Amazon\EC2-Windows\Launch\Log\UserdataExecution.log
- Lite engine logs:
What does it mean if delegate.task throws a "ConnectException failed to connect" error?
Before submitting a task to a delegate, Harness runs a capability check to confirm that the delegate is connected to the runner. If the delegate can't connect, then the capability check fails and that delegate is ignored for the task. This can cause failed to connect errors on delegate task assignment, such as:
INFO io.harness.delegate.task.citasks.vm.helper.HttpHelper - [Retrying failed to check pool owner; attempt: 18 [taskId=1234-DEL] \
java.net.ConnectException: Failed to connect to /127.0.0.1:3000\
To debug this issue, investigate delegate connectivity in your VM build infrastructure configuration:
- Verify connectivity for AWS VM build infra
- Verify connectivity for Microsoft Azure VM build infra
- Verify connectivity for GCP VM build infra
- Verify connectivity for Anka macOS VM build infra
How to establish a VPN connection within a CI pipeline?
One way to establish a secure connection between our platform’s servers and a customer’s on-premises infrastructure is through a Virtual Private Network (VPN).
- The user must publish a public IP address (or have a domain).
- The VPN connection must be established before any step that relies on VPN traffic for functionality.
Here is an example of using an OpenVPN server, but you can apply the same approach to Strongswan, Cisco, or any other VPN server.
Steps to configure OpenVPN
- Download an OpenVPN file, "config.ovpn".
- Encode the file to Base64 and save it.
- Add the file as a secret.
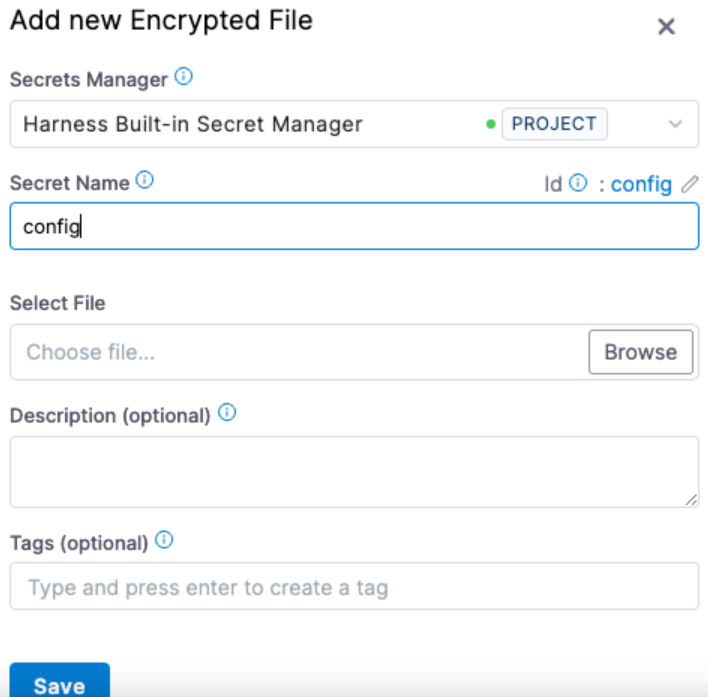
-
Decode the file, save it as a config file, and install OpenVPN.

-
Run OpenVPN with the new file as a Background Step.

-
Continue with the rest of the pipeline steps.
Harness Cloud
What is Harness Cloud?
Harness Cloud lets you run builds on Harness-managed runners that are preconfigured with tools, packages, and settings commonly used in CI pipelines. It is one of several build infrastructure options offered by Harness. For more information, go to Which build infrastructure is right for me.
How do I use Harness Cloud build infrastructure?
Configuring your pipeline to use Harness Cloud takes just a few minutes. Make sure you meet the requirements for connectors and secrets, then follow the quick steps to use Harness Cloud.
Account verification error with Harness Cloud on Free plan
Recently Harness has been the victim of several Crypto attacks that use our Harness-managed build infrastructure (Harness Cloud) to mine cryptocurrencies. Harness Cloud is available to accounts on the Free tier of Harness CI. Unfortunately, to protect our infrastructure, Harness now limits the use of the Harness Cloud build infrastructure to business domains and block general-use domains, like Gmail, Hotmail, Yahoo, and other unverified domains.
To address these issues, you can do one of the following:
- Use the local runner build infrastructure option, or upgrade to a paid plan to use the self-managed VM or Kubernetes cluster build infrastructure options. There are no limitations on builds using your own infrastructure.
- Create a Harness account with your work email and not a generic email address, like a Gmail address.
What is the Harness Cloud build credit limit for the Free plan?
The Free plan allows 2,000 build credits per month. For more information, go to Harness Cloud billing and build credits.
Can I use xcode for a MacOS build with Harness Cloud?
Yes. Harness Cloud macOS runners include several versions of xcode as well as homebrew. For details, go to Harness Cloud image specifications. You can also install additional tools at runtime.
What Linux distribution does Harness Cloud use?
For Harness CI Cloud machine specs, go to Harness Cloud image specifications.
Can I use my own secrets manager with Harness Cloud build infrastructure?
Yes, Harness supports secret managers from various cloud providers, including HashiCorp Vault.
Connector errors with Harness Cloud build infrastructure
To use Harness Cloud build infrastructure, all connectors used in the stage must connect through the Harness Platform. This means that:
- GCP connectors can't inherit credentials from the delegate. They must be configured to connect through the Harness Platform.
- Azure connectors can't inherit credentials from the delegate. They must be configured to connect through the Harness Platform.
- AWS connectors can't use IRSA, AssumeRole, or delegate connectivity mode. They must connect through the Harness Platform with access key authentication.
For more information, go to Use Harness Cloud build infrastructure - Requirements for connectors and secrets.
To change the connector's connectivity mode:
- Go to the Connectors page at the account, organization, or project scope. For example, to edit account-level connectors, go to Account Settings, select Account Resources, and then select Connectors.
- Select the connector that you want to edit.
- Select Edit Details.
- Select Continue until you reach Select Connectivity Mode.
- Select Change and select Connect through Harness Platform.
- Select Save and Continue and select Finish.
Built-in Harness Docker Connector doesn't work with Harness Cloud build infrastructure
Depending on when your account was created, the built-in Harness Docker Connector (account.harnessImage) might be configured to connect through a Harness Delegate instead of the Harness Platform. In this case, attempting to use this connector with Harness Cloud build infrastructure generates the following error:
While using hosted infrastructure, all connectors should be configured to go via the Harness platform instead of via the delegate. \
Please update the connectors: [harnessImage] to connect via the Harness platform instead. \
This can be done by editing the connector and updating the connectivity to go via the Harness platform.
To resolve this error, you can either modify the Harness Docker Connector or use another Docker connector that you have already configured to connect through the Harness Platform.
To change the connector's connectivity settings:
- Go to Account Settings and select Account Resources.
- Select Connectors and select the Harness Docker Connector (ID:
harnessImage). - Select Edit Details.
- Select Continue until you reach Select Connectivity Mode.
- Select Change and select Connect through Harness Platform.
- Select Save and Continue and select Finish.
Can I change the CPU/memory allocation for steps running on Harness cloud?
Unlike with other build infrastructures, you can't change the CPU/memory allocation for steps running on Harness Cloud. Step containers running on Harness Cloud build VMs automatically use as much as CPU/memory as required up to the available resource limit in the build VM.
Does gsutil work with Harness Cloud?
No, gsutil is deprecated. You should use gcloud-equivalent commands instead, such as gcloud storage cp instead of gsutil cp.
However, neither gsutil nor gcloud are recommended with Harness Cloud build infrastructure. Harness Cloud sources build VMs from a variety of cloud providers, and it is impossible to predict which specific cloud provider hosts the Harness Cloud VM that your build uses for any single execution. Therefore, avoid using tools (such as gsutil or gcloud) that require a specific cloud provider's environment.
Can't use STO steps with Harness Cloud macOS runners
Currently, STO scan steps aren't compatible with Harness Cloud macOS runners, because Apple's M1 CPU doesn't support nested virtualization. You can use STO scan steps with Harness Cloud Linux and Windows runners.
How do I configure OIDC with GCP WIF for Harness Cloud builds?
Go to Configure OIDC with GCP WIF for Harness Cloud builds.
GCP OIDC Connector keeps saying "OIDC Configuration Error: Error encountered while obtaining OIDC Access Token from STS" configuration is correct
Harness obsfucates various information from GCP OIDC connections due to security and information concerns. In order to keep customers safe even in the case of connection error, Harness obasfucates information that may help troubleshoot this kind of issue.
To start, please ensure that your Harness Environment and Google Cloud Environment are configured according to our documentation about Configure OIDC with GCP WIF for Harness Cloud builds
Next, please ensure that you have an API key for an Harness account with at least CREATE_OIDC_ID_TOKEN_PERMISSION permissions in your Harness Environment.
Attain Your Harness JSON Web Token (JWT)
In order to perform some of the tasks, you will need to attain your JSON Web Token (JWT), you will need to cURL against the Harness API endpoint with the following command:
curl --location 'https://app.harness.io/ng/api/oidc/id-token/gcp' \
--header 'accept: application/json' \
--header 'Content-Type: application/json' \
--header 'x-api-key: YOUR_API_KEY' \
--data-raw '{
"accountId": "YOUR_HARNESS_ACCOUNT_ID",
"workloadPoolId": "YOUR_CONNECTOR_WORKLOAD_POOL_ID",
"providerId": "YOUR_CONNECTOR_PROVIDER_ID",
"gcpProjectId": "YOUR_CONNECTOR_PROJECT#_ID",
"serviceAccountEmail": "YOUR_CONNECTOR_SVC_ACCOUNT_EMAIL_ID"
}'
You'll need to replace the values in capital letters with your information from the OIDC Connector/WIF Account and your Harness Environment.
Once you run the command, Harness will return a successful JWT
{
"status": "SUCCESS",
"data": "aaa9aAAaAaAAAV9AaAAAhAaAaAaAAAAaA9AaAaAaAaAaAAaA9AaAAAAAAa9AAAaAaAaAaAaAAbAaAbAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAa999AaAaAaAaAaAa-aAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaA.aAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaAaA",
"metaData": null,
"correlationId": "00a000aa-a0000-0a00-000a-0a00a0a0a000"
}
The data portion is the JWT
Compare the issuer in the JSON Web Token with what is being supplied by Harness
You can now decode your JWT token and ensure its values are correct. You can decode the JWT using a tool of your choice (such as with Python) or visit a site like https://jwt.io/, and decode the values for the payload (please note that Harness does not endorse https://jwt.io). The values should look somewhat like the following:
{
"sub": "YOUR_HARNESS_ACCOUNT_ID",
"iss": "https://app.harness.io/ng/api/oidc/account/<YOUR_HARNESS_ACCOUNT_ID>",
"aud": "https://iam.googleapis.com/projects/<YOUR_CONNECTOR_PROJECT#_ID>/locations/global/workloadIdentityPools/<YOUR_CONNECTOR_WORKLOAD_POOL_ID>/providers/<YOUR_CONNECTOR_PROVIDER_ID>",
"exp": 1750713017,
"iat": 1750711017,
"account_id": "YOUR_HARNESS_ACCOUNT_ID"
}
Now perform a cURL from a local system to Harness, using the appropriate Hostname for your Harness Cluster. Note that the source IP must be part of the allow-listed for the account.
| Cluster | HostName |
|---|---|
| Prod1/Prod2 | app.harness.io |
| Prod3 | app3.harness.io |
| Prod0/Prod4 | accounts.harness.io |
| EU clusters | accounts.eu.harness.io |
curl https://<HOSTNAME>/ng/api/oidc/account/<YOUR_HARNESS_ACCOUNT_ID>/.well-known/openid-configuration
Compare the value for iss with the issuer value from the curl command. They should match.
Test your JSON Web Token for issues using GCP's STS Method: Token test
GCP has a method to test a token's external identity within a pool.
Customers will need to visit the GCP site, and prepare a payload for testing.
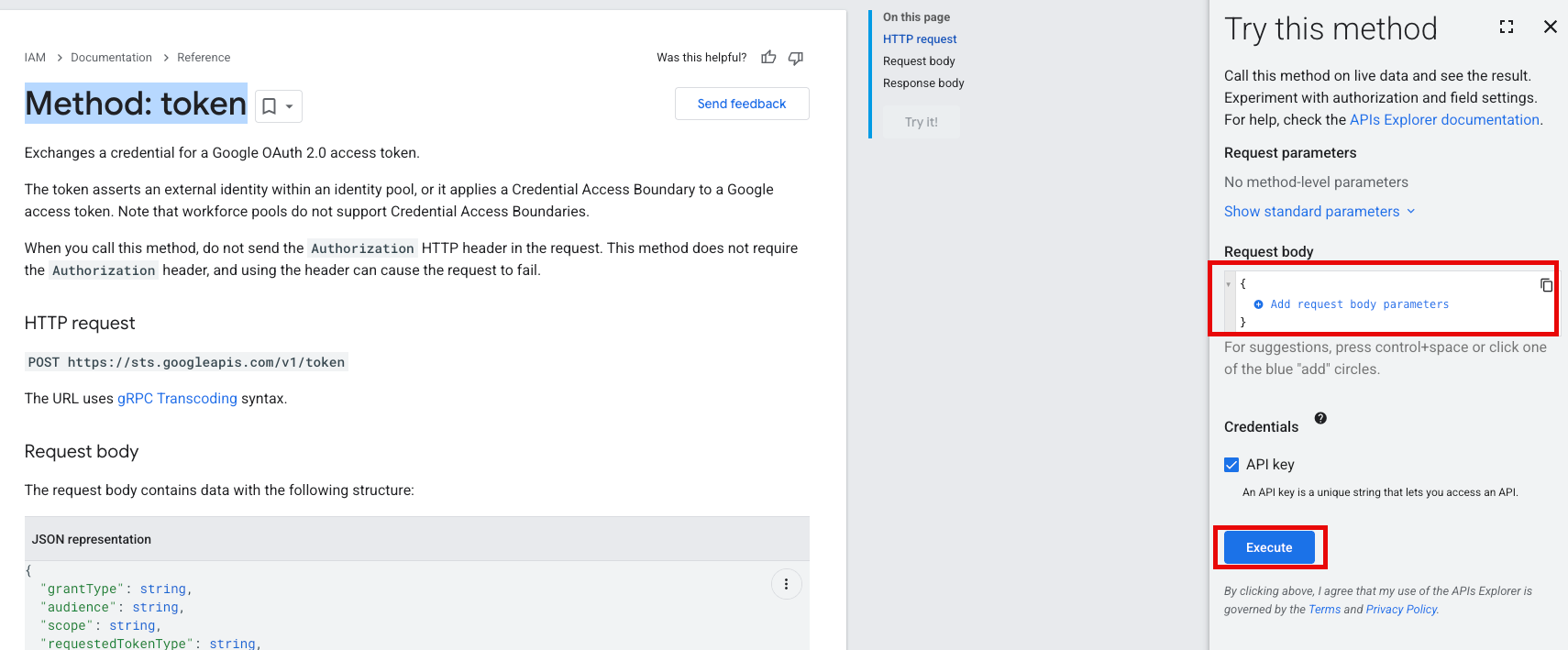
Using the Try this Method section, add the following request body, that follows the example outlined in the GCP documentation. Take special note that the audience value for the test does not have the https: portion of the url. Including it will result in an error.
{
"grantType": "urn:ietf:params:oauth:grant-type:token-exchange",
"audience": "//iam.googleapis.com/projects/<YOUR_CONNECTOR_PROJECT#_ID>/locations/global/workloadIdentityPools/<YOUR_CONNECTOR_WORKLOAD_POOL_ID>/providers/<YOUR_CONNECTOR_PROVIDER_ID>",
"scope": "https://www.googleapis.com/auth/cloud-platform",
"requestedTokenType": "urn:ietf:params:oauth:token-type:access_token",
"subjectToken": "<YOUR_JWT_FROM_ABOVE_STEPS>",
"subjectTokenType": "urn:ietf:params:oauth:token-type:id_token"
}
Click on the Execute button. If you receive a 200 response, then your token should be set up correctly, and there should not be any issues. If there is another response, this means there is an issue with how the GCP WIF was set up, and we recommend reviewing the information in the error to help troubleshoot the issue.
When I run a build on Harness cloud, which delegate is used? Do I need to install a delegate to use Harness Cloud?
Harness Cloud builds use a delegate hosted in the Harness Cloud runner. You don't need to install a delegate in your local infrastructure to use Harness Cloud.
Can I use Harness Cloud run CD steps/stages?
No. Currently, you can't use Harness Cloud build infrastructure to run CD steps or stages. Currently, Harness Cloud is specific to Harness CI.
Can I connect to services running in a private corporate network when using Harness Cloud?
Yes. You can use Secure Connect for Harness Cloud.
With Harness Cloud build infrastructure, do I need to run DinD in a Background step to run Docker builds in a Run step?
No. Harness CI Cloud uses Harness-managed VM images that already have Docker installed. You can access these binaries by directly running Docker commands in your Run steps.
With Harness Cloud, can I cache images pulled from my internal container registry?
Currently, caching build images with Harness CI Cloud isn't supported.
When running a build in Harness cloud, does a built-in step run within a container or does it run as a VM process?
By default, a built-in step runs inside a container within the build VM.
How to fix the docker rate limiting errors while pulling the Harness internal images when the build is running on Harness cloud?
You could update the deafult docker connector harnessImage and point it to the Harness internal GAR/ECR as mentioned in the doc
Kubernetes clusters
What is the difference between a Kubernetes cluster build infrastructure and other build infrastructures?
For a comparison of build infrastructures go to Which build infrastructure is right for me.
For requirements, recommendations, and settings for using a Kubernetes cluster build infrastructure, go to:
- Set up a Kubernetes cluster build infrastructure
- Build and push artifacts and images - Kubernetes cluster build infrastructures require root access
- CI Build stage settings - Infrastructure - Kubernetes tab
Can I run Docker commands on a Kubernetes cluster build infrastructure?
If you want to run Docker commands when using a Kubernetes cluster build infrastructure, Docker-in-Docker (DinD) with privileged mode is required. For instructions, go to Run DinD in a Build stage.
If your cluster doesn't support privileged mode, you must use a different build infrastructure option, such as Harness Cloud, where you can run Docker commands directly on the host without the need for Privileged mode. For more information, go to Set up a Kubernetes cluster build infrastructure - Privileged mode is required for Docker-in-Docker.
Can I use Istio MTLS STRICT mode with Harness CI?
Yes, but you must create a headless service for Istio MTLS STRICT mode.
How can you execute Docker commands in a CI pipeline that runs on a Kubernetes cluster that lacks a Docker runtime?
You can run Docker-in-Docker (DinD) as a service with the sharedPaths set to /var/run. Following that, the steps can be executed as Docker commands. This works regardless of the Kubernetes container runtime.
The DinD service does not connect to the Kubernetes node daemon. It launches a new Docker daemon on the pod, and then other containers use that Docker daemon to run their commands.
For details, go to Run Docker-in-Docker in a Build stage.
Resource allocation for Kubernetes cluster build infrastructure
You can adjust CPU and memory allocation for individual steps running on a Kubernetes cluster build infrastructure or container. For information about how resource allocation is calculated, go to Resource allocation.
What is the default CPU and memory limit for a step container?
For default resource request and limit values, go to Build pod resource allocation.
Why do steps request less memory and CPU than the maximum limit? Why do step containers request fewer resources than the limit I set in the step settings?
By default, resource requests are always set to the minimum, and additional resources (up to the specified maximum limit) are requested only as needed during build execution. For more information, go to Build pod resource allocation.
How do I configure the build pod to communicate with the Kubernetes API server?
By default, the namespace's default service account is auto-mounted on the build pod, through which it can communicate with API server. To use a non-default service account, specify the Service Account Name in the Kubernetes cluster build infrastructure settings.
Do I have to mount a service account on the build pod?
No. Mounting a service account isn't required if the pod doesn't need to communicate with the Kubernetes API server during pipeline execution. To disable service account mounting, deselect Automount Service Account Token in the Kubernetes cluster build infrastructure settings.
What types of volumes can be mounted on a CI build pod?
You can mount many types of volumes, such as empty directories, host paths, and persistent volumes, onto the build pod. Use the Volumes in the Kubernetes cluster build infrastructure settings to do this.
How can I run the build pod on a specific node?
Use the Node Selector setting to do this.
It is possible to make a toleration configuration at the project, org, or account level?
Tolerations in a Kubernetes cluster build infrastructure can only be set at the stage level.
I want to use an EKS build infrastructure with an AWS connector that uses IRSA
You need to set the Service Account Name in the Kubernetes cluster build infrastructure settings.
If you get error checking push permissions or similar, go to the Build and Push to ECR error article.
Why are build pods being evicted?
Harness CI pods shouldn't be evicted due to autoscaling of Kubernetes nodes because Kubernetes doesn't evict pods that aren't backed by a controller object. However, build pods can be evicted due to CPU or memory issues in the pod or using spot instances as worker nodes.
If you notice either sporadic pod evictions or failures in the Initialize step in your Build logs, add the following Annotation to your Kubernetes cluster build infrastructure settings:
"cluster-autoscaler.kubernetes.io/safe-to-evict": "false"
I can't use Kubernetes autoscaling to distribute the pipeline workload.
In a Build stage, Harness creates a pod and launches each step in a container within the pod.
Harness reserves node resources based on the pipeline configuration.
Even if you enable autoscaling on your cluster, the pipeline uses resources from one node only.
AKS builds timeout
Azure Kubernetes Service (AKS) security group restrictions can cause builds running on an AKS build infrastructure to timeout.
If you have a custom network security group, it must allow inbound traffic on port 8080, which the delegate service uses.
For more information, refer to the following Microsoft Azure troubleshooting documentation: A custom network security group blocks traffic.
How do I set the priority class level? Can I prioritize my build pod if there are resource shortages on the host node?
Use the Priority Class setting to ensure that the build pod is prioritized in cases of resource shortages on the host node.
What's the default priority class level?
If you leave the Priority Class field blank, the PriorityClass is set to the globalDefault, if your infrastructure has one defined, or 0, which is the lowest priority.
Can I transfer files into my build pod?
To do this, use a script in a Run step.
Can I mount an existing Kubernetes secret into the build pod?
Currently, Harness doesn't offer built-in support for mounting existing Kubernetes secrets into the build pod.
How are step containers named within the build pod?
Step containers are named sequentially starting with step-1.
When I run a build, Harness creates a new pod and doesn't run the build on the delegate
This is the expected behavior. When you run a Build (CI) stage, each step runs on a new build farm pod that isn't connected to the delegate.
What permissions are required to run CI builds in an OpenShift cluster?
For information about building on OpenShift clusters, go to Permissions Required and OpenShift Support in the Kubernetes Cluster Connector Settings Reference.
What are the minimum permissions required for the service account role for a Kubernetes Cluster connector?
For information about permissions required to build on Kubernetes clusters, go to Permissions Required in the Kubernetes Cluster Connector Settings Reference.
How does the build pod communicate with the delegate? What port does the lite-engine listen on?
The delegate communicates to the temp pod created by the container step through the build pod IP. Build pods have a lite engine running on port 20001.
Experiencing OOM on java heap for the delegate
Check CPU utilization and try increasing the CPU request and limit amounts.
Your Java options must use UseContainerSupport instead of UseCGroupMemoryLimitForHeap, which was removed in JDK 11.
I have multiple delegates in multiple instances. How can I ensure the same instance is used for each step?
Use single replica delegates for tasks that require the same instance, and use a delegate selector by delegate name. The tradeoff is that you might have to compromise on your delegates' high availability.
Delegate is unable to connect to the created build farm
If you get this error when using a Kubernetes cluster build infrastructure, and you have confirmed that the delegate is installed in the same cluster where the build is running, you may need to allow port 20001 in your network policy to allow pod-to-pod communication.
If the delegate is unable to connect to the created build farm with Istio MTLS STRICT mode, and you are seeing that the pod is removed after a few seconds, you might need to add Istio ProxyConfig with "holdApplicationUntilProxyStarts": true. This setting delays application start until the pod is ready to accept traffic so that the delegate doesn't attempt to connect before the pod is ready.
For more delegate and Kubernetes troubleshooting guidance, go to Troubleshooting Harness.
Why aren't Harness CI Steps like Git clone inheriting my proxy settings from the Delegate, and how can I configure a proxy for these steps?
CI steps such as Git Clone don't automatically inherit the proxy settings configured on the Harness Delegate. This is because these steps run inside separate build pods, and proxy-related environment variables need to be explicitly passed down to those pods.
To ensure your CI steps work with your proxy setup, you must configure the following environment variables on the Delegate:
PROXY_HOST
PROXY_PORT
PROXY_SCHEME
These variables allow Harness to propagate the proxy configuration to build pods so that operations like cloning a Git repository can route through the correct proxy.
For a complete list of variables and instructions on setting up proxy configurations for your Delegate, refer to the Configure delegate proxy settings documentation
If my pipeline consists of multiple CI stages, are all the steps across different stages executed within the same build pod?
No. Each CI stage execution triggers the creation of a new build pod. The steps within a stage are then carried out within the stage's dedicated pod. If your pipeline has multiple CI stages, distinct build pods are generated for each individual stage.
When does the cleanup of build pods occur? Does it happen after the entire pipeline execution is finished?
Build pod cleanup takes place immediately after the completion of a stage's execution. This is true even if there are multiple CI stages in the same pipeline; as each build stage ends, the pod for that stage is cleaned up.
Is the build pod cleaned up in the event of a failed stage execution?
Yes, the build pod is cleaned up after stage execution, regardless of whether the stage succeeds or fails.
How do I know if the pod cleanup task fails?
To help identify pods that aren't cleaned up after a build, pod deletion logs include details such as the cluster endpoint targeted for deletion. If a pod can't be located for cleanup, then the logs include the pod identifier, namespace, and API endpoint response from the pod deletion API. You can find logs in the Build details.
Can I clean up container images already present on the nodes where build pods are scheduled?
To clean up cached images, you can execute commands like docker image prune or docker system prune -a, depending on the container runtime used on the Kubernetes nodes.
Perform this cleanup task outside of Harness, following the usual processes for clearing cached or unused container images from worker nodes.
Can I use an ECS cluster for my Kubernetes cluster build infrastructure?
Currently, Harness CI doesn't support running CI builds on ECS clusters.
Can I use a Docker delegate with a Kubernetes cluster build infrastructure?
Yes, if the Kubernetes connector is configured correctly. For more information, go to Use delegate selectors with Kubernetes cluster build infrastructure.
How can I configure the kaniko flag --skip-unused-stages in the built-in Build and Push step?
You can set the kaniko flags as an environment variable in the build and push step. For more information, go to Environment Variables (plugin runtime flags)
Does the built in Build and Push step now support all the kainko flags?
Yes, all the kaniko flags are supported and they can be added as the environment variables to the build and push step
Can I add additional docker options with the container being started via background step in k8s build, such as the option to mount a volume or attach the container to a specific docker network?
Adding additional Docker options when starting the container via a background step is not supported
Why Harness internal container lite-engine is requesting a huge cpu/memory within the build pod?
Lite-engine consumes very minimal compute resource however it reserves the resource for the other step containers. More details about how the resources are allocated within the build pod can be reffered in the doc
Why the build pod status is showing "not ready" in k8s cluster while the build is running?
Each step container will be terminated as soon the step execution has been completed. Since there could be containers in terminated state while the build is running, k8s would show the pod state as "not ready" which can be ignored.
We have a run step configured with an image that has few scripts in the container filesystem. Why don’t we see these files when Harness is starting this container during the execution?
This could happen if you are configuring the shared path in the CI stage with the same path or mount any other type of volumes in the build pod at the same path.
Can we add barriers in CI stage?
No, barrier is not currently supported in CI stage
How to set the kaniko flag "--reproducible" in the build and push step?
Kaniko flags can be configured as environment variables in build and push step. More details about the same can be referred in the doc
How can we configure the build and push to ECR step to pull the base image configured in dockerfile from a private container registry?
You can configure the base connector in the build and push step and Harness will use the creds configured in this connector to pull the private image during runtime
Does the output variable configured in the run step get exported even if the step execution fails?
No, the output variable configured in the run step does not get exported if the step execution fails
Why is the Exporting of output variable from a run step is failing with the error "* stat /tmp/engine/xxxxxxx-output.env: no such file or directory" even after the step executed successfully ?
When an output variable is configured in a run step, Harness adds a command at the end of the script to write the variable's value to a temp file, from which the output variable is processed. The error occurs if you manually exit the script with 'exit 0' before all commands are executed. Avoid calling 'exit 0' in the script if you are exporting an output variable.
Can we use docker compose to start multiple containers when we run the build in k8s cluster?
You can use docker compose while running the build in k8s cluster however you need to run the dind as a background step as detailed in the doc
When we start a container by running docker run command from a run step, does the new container get the environment variables configured in the run step?
No, ENV variables configured in the run step will not be available within the new container, you need to manually pass the required ENV variable while starting the container
How can we trigger a CI pipeline from a specific commit?
We can not execute the CI pipeline from a specific commit however you could create a branch or tag based on the required commit and then run the pipeline from the new branch or tag
How can we use the jfrog docker registry in the build and push step to docker step?
You can configure the docker connector using the jfrog docker registry URL and then use this connector in the build and push to docker step.
Why is the Build and Push to Docker step configured with the JFrog Docker connector not using the JFrog endpoint while pushing the image, instead defaulting to the Docker endpoint?
This could happen when the docker repository in the build and push step is not configured with the FQN. The repository should be configured with the FQN including the jfrog endpoint.
Why the execution is getting aborted without any reason and the "applied by" field is showing trigger?
This could happen when the PR/push trigger is configured with the 'Auto-abort Previous Execution' option, which will automatically cancel active builds started by the same trigger when a branch or PR is updated
Can we add the config "topologySpreadConstraints" in the build pod which will help CI pod to spread across different AZs?
Harness CI now includes a new property, podSpecOverlay, in the Kubernetes infrastructure properties of the CI stage. This allows users to apply additional settings to the build pod. Currently, we support specifying topologySpreadConstraint in this field. Please see doc
Why the docker commands in the run step is failing with the error "Cannot connect to the Docker daemon at unix:///var/run/docker.sock?" even after the dind background step logs shows that the docker daemon has been initialized?
This could happen if the folders /var/lib/docker and /var/run are not added under the shared path in the CI stage. More details about the dind config can be referred in the doc
Why the build using dind is failing with out of memory error even after enough memory is configured in the run step where the docker commands are running?
When dind is used, the build will run on the dind container instead of the step container where Docker commands are executed. Therefore, if an out-of-memory error occurs during the build on dind, the resources on the dind container need to be updated
Why the docker commands are failing on the run step with the error "command not found: docker" even if we have the dind running as background step?
This happens when the step container configured in the run step doesnt have docker cli installed
How can we use buildx while running the build in k8s build infra?
The built-in build and push step use kaniko to perform the build in k8s build infra. We can configure dind build to use buildx while running the build in k8s infra More details about the dind config can be referred in the doc
Do we need to have both ARM and AMD build infrastructure to build multiarch images using built-in build and push step in k8s infra?
Yes, we need to have one stage running on ARM and another stage running on AMD to build both ARM and AMD images using the built-in build and push step in k8s infra. More details including a sample pipeline can be referred in the doc
Does Harness CI support AKS 1.28.3 version?
Yes
Self-signed certificates
Can I mount internal CA certs on the CI build pod?
Yes. To do this with a Kubernetes cluster build infrastructure, go to Configure a Kubernetes build farm to use self-signed certificates.
Can I use self-signed certs with local runner build infrastructure?
With a local runner build infrastructure, you can use CI_MOUNT_VOLUMES to use self-signed certificates. For more information, go to Set up a local runner build infrastructure.
How do I make internal CA certs available to the delegate pod?
There are multiple ways you can do this:
- Build the delegate image with the certs baked into it, if you are custom building the delegate image.
- Create a secret/configmap with the certs data, and then mount it on the delegate pod.
- Run commands in the
INIT_SCRIPTto download the certs while the delegate launches and make them available to the delegate pod file system.
Where should I mount internal CA certs on the build pod?
The usage of the mounted CA certificates depends on the specific container image used for the step. The default certificate location depends on the base image you use. The location where the certs need to be mounted depends on the container image being used for the steps that you intend to run on the build pod.
Git connector SCM connection errors when using self-signed certificates
If you have configured your build infrastructure to use self-signed certificates, your builds may fail when the code repo connector attempts to connect to the SCM service. Build logs may contain the following error messages:
Connectivity Error while communicating with the scm service
Unable to connect to Git Provider, error while connecting to scm service
To resolve this issue, add SCM_SKIP_SSL=true to the environment section of the delegate YAML. For example, here is the environment section of a docker-compose.yml file with the SCM_SKIP_SSL variable:
environment:
- ACCOUNT_ID=XXXX
- DELEGATE_TOKEN=XXXX
- MANAGER_HOST_AND_PORT=https://app.harness.io
- DELEGATE_NAME=test
- NEXT_GEN=true
- DELEGATE_TYPE=DOCKER
- SCM_SKIP_SSL=true
For more information about self-signed certificates, delegates, and delegate environment variables, go to:
- Delegate environment variables
- Docker delegate environment variables
- Install delegates
- Set up a local runner build infrastructure
- Configure a Kubernetes build farm to use self-signed certificates
Certificate volumes aren't mounted to the build pod
If the volumes are not getting mounted to the build containers, or you see other certificate errors in your pipeline, try the following:
-
Add a Run step that prints the contents of the destination path. For example, you can include a command such as:
cat /kaniko/ssl/certs/additional-ca-cert-bundle.crt -
Double-check that the base image used in the step reads certificates from the same path given in the destination path on the Delegate.
pnpm enters infinite loop without logs
If your pipeline runs pnpm or npm commands that cause it to enter an infinite loop or wait indefinitely without producing logs, try adding the following command to your script to see if this allows the build to proceed:
npm config set strict-ssl false
If your pnpm commands are waiting for user input. Try using the append-only flag.
How do I use a self-signed certificate for a private Docker registry in the Build and Push to Docker Registry step?
To use a self-signed certificate for a private Docker registry in the Build and Push to Docker Registry step, you need to ensure that the runner (or build infrastructure) trusts the certificate. Since the Build and Push to Docker Registry step does not provide a direct way to configure self-signed certificates, you can use a Run step before it to manually add the certificate.
Example: Using a Run step to configure the self-signed certificate
Before running the Build and Push to Docker Registry step, add a Run step in your pipeline and use the following example to set up the self-signed certificate:
- step:
type: Run
name: Run_1
identifier: Run_1
spec:
shell: Sh
command: |-
# Write the certificate content to a file
echo '<+secrets.getValue("crt")>' > ca.crt
# Create the Docker certificates directory for the private registry
mkdir -p /etc/docker/certs.d/PRIVATE_DOCKER_REGISTRY_SERVER:PRIVATE_DOCKER_REGISTRY_PORT
# Copy the certificate to the Docker certificates directory
cp ca.crt /etc/docker/certs.d/PRIVATE_DOCKER_REGISTRY_SERVER:PRIVATE_DOCKER_REGISTRY_PORT
# Update the system's trusted certificate store (for Ubuntu/Debian)
update-ca-certificates
# Update the system's trusted certificate store (for CentOS/RHEL/Fedora)
update-ca-trust
Use another Run step to test the connection:
- step:
type: Run
name: Run_2
identifier: Run_2
spec:
shell: Sh
command: |-
docker login PRIVATE_DOCKER_REGISTRY_SERVER:PRIVATE_DOCKER_REGISTRY_PORT --username SOMEUSERNAME --password SOMEPASSWORD
Windows builds
Error when running Docker commands on Windows build servers
Make sure that the build server has the Windows Subsystem for Linux installed. This error can occur if the container can't start on the build system.
Docker commands aren't supported for Windows builds on Kubernetes cluster build infrastructures.
Is rootless configuration supported for builds on Windows-based build infrastructures?
No, currently this is not supported for Windows builds.
What is the default user set on the Windows Lite-Engine and Addon image? Can I change it?
The default user for these images is ContainerAdministrator. For more information, go to Run Windows builds in a Kubernetes build infrastructure - Default user for Windows builds.
Can I use custom cache paths on a Windows platform with Cache Intelligence?
Yes, you can use custom cache paths with Cache Intelligence on Windows platforms.
How do I specify the disk size for a Windows instance in pool.yml?
With self-managed VM build infrastructure, the disk configuration in your pool.yml specifies the disk size (in GB) and type.
For example, here is a Windows pool configuration for an AWS VM build infrastructure:
version: "1"
instances:
- name: windows-ci-pool
default: true
type: amazon
pool: 1
limit: 4
platform:
os: windows
spec:
account:
region: us-east-2
availability_zone: us-east-2c
access_key_id:
access_key_secret:
key_pair_name: XXXXX
ami: ami-088d5094c0da312c0
size: t3.large ## VM machine size.
hibernate: true
network:
security_groups:
- sg-XXXXXXXXXXXXXX
disk:
size: 100 ## Disk size in GB.
type: "pd-balanced"
Step continues running for a long time after the command is complete
In Windows builds, if the primary command in a Powershell script starts a long-running subprocess, the step continues to run as long as the subprocess exits (or until it reaches the step timeout limit). To resolve this:
- Check if your command launches a subprocess.
- If it does, check whether the process is exiting, and how long it runs before exiting.
- If the run time is unacceptable, you might need to add commands to sleep or force exit the subprocess.
Example: Subprocess with two-minute life
Here's a sample pipeline that includes a Powershell script that starts a subprocess. The subprocess runs for no more than two minutes.
pipeline:
identifier: subprocess_demo
name: subprocess_demo
projectIdentifier: default
orgIdentifier: default
tags: {}
stages:
- stage:
identifier: BUild
type: CI
name: Build
spec:
cloneCodebase: true
execution:
steps:
- step:
identifier: Run_1
type: Run
name: Run_1
spec:
connectorRef: YOUR_DOCKER_CONNECTOR_ID
image: jtapsgroup/javafx-njs:latest
shell: Powershell
command: |-
cd folder
gradle --version
Start-Process -NoNewWindow -FilePath "powershell" -ArgumentList "Start-Sleep -Seconds 120"
Write-Host "Done!"
resources:
limits:
memory: 3Gi
cpu: "1"
infrastructure:
type: KubernetesDirect
spec:
connectorRef: YOUR_KUBERNETES_CLUSTER_CONNECTOR_ID
namespace: YOUR_KUBERNETES_NAMESPACE
initTimeout: 900s
automountServiceAccountToken: true
nodeSelector:
kubernetes.io/os: windows
os: Windows
caching:
enabled: false
paths: []
properties:
ci:
codebase:
connectorRef: YOUR_CODEBASE_CONNECTOR_ID
build:
type: branch
spec:
branch: main
Concatenated variable values in PowerShell scripts print to multiple lines
If your PowerShell script (in a Run step) echoes a stage variable that has a concatenated value that includes a ToString representation of a PowerShell object (such as the result of Get-Date), this output might unexpectedly print to multiple lines in the build logs.
To resolve this, exclude the ToString portion from the stage variable's concatenated value, and then, in your PowerShell script, call ToString separately and "manually concatenate" the values. Expand the sections below to learn more about the cause and solution for this issue.
What causes unexpected multiline output from PowerShell scripts?
For example, the following two stage variables include one variable that has a ToString value and another variable that concatenates three expressions into a single expression, including the ToString value.
variables:
- name: DATE_FORMATTED ## This variable's value is 'ToString' output.
type: String
description: ""
required: false
value: (Get-Date).ToString("yyyy.MMdd")
- name: BUILD_VAR ## This variable's value concatenates the execution ID, the sequence ID, and the value of DATE_FORMATTED.
type: String
description: ""
required: false
value: <+<+pipeline.executionId>+"-"+<+pipeline.sequenceId>+"-"+<+stage.variables.DATE_FORMATTED>>
When a PowerShell script calls the concatenated variable, such as echo <+pipeline.stages.test.variables.BUILD_VAR>, the ToString portion of the output prints on a separate line from the rest of the value, despite being part of one concatenated expression.
How do I fix unexpected multiline output from PowerShell scripts?
To resolve this, exclude the ToString portion from the stage variable's concatenated value, and then, in your PowerShell script, call ToString separately and "manually concatenate" the values.
For example, here are the two stage variables from the previous example without the ToString value in the concatenated expression.
variables:
- name: DATE_FORMATTED ## This variable is unchanged.
type: String
description: ""
required: false
value: (Get-Date).ToString("yyyy.MMdd")
- name: BUILD_VAR ## This variable's value concatenates only the execution ID and sequence ID. It no longer includes DATE_FORMATTED.
type: String
description: ""
required: false
value: <+<+pipeline.executionId>+"-"+<+pipeline.sequenceId>>
In the Run step's PowerShell script, call the ToString value separately and then "manually concatenate" it onto the concatenated expression. For example:
- step:
identifier: echo
type: Run
name: echo
spec:
shell: Powershell
command:
|- ## DATE_FORMATTED is resolved separately and then appended to BUILD_VAR.
$val = <+stage.variables.DATE_FORMATTED>
echo <+pipeline.stages.test.variables.BUILD_VAR>-$val
User data isn't running on AWS Windows Server 2022 VM Pool
Windows only runs User Data during initialization. To fix this, go to C:\ProgramData\Amazon\EC2Launch\state and delete the .run-once file. This file is generated after the Windows VM initializes. On startup Windows will check for this file and decide whether or not to run the User Data script. If this file is not present, Windows will run the User Data script.
How do I install Docker on Windows?
To install Docker on Windows, run:
Invoke-WebRequest -UseBasicParsing "https://raw.githubusercontent.com/microsoft/Windows-Containers/Main/helpful_tools/Install-DockerCE/install-docker-ce.ps1" -o install-docker-ce.ps1
.\install-docker-ce.ps1
More information on this can be found in the Microsoft Documentation.
Do I need to enable Hyper V for AWS Windows VM Pool?
Hyper V is not required to run Harness Builds in a Windows VM Pool. Hyper V is a requirement for Docker Desktop and Docker Desktop is not required for self-managed Windows VM build infrastructure.
Do I need to install WSL for AWS Windows VM Pool?
WSL is not required to run Harness Builds in a Windows VM Pool. WSL is a requirement for Docker Desktop and Docker Desktop is not required for Windows Self-Managed Build Infrastructure.
How do I check the logs for Windows Server 2022 when using EC2Launchv2
Logs are generated in the C:\ProgramData\Amazon\EC2Launch\log directory for EC2Launchv2. To view startup logs, check the C:\ProgramData\Amazon\EC2Launch\log\agent file. For any errors check the C:\ProgramData\Amazon\EC2Launch\log\err file.
Default user, root access, and run as non-root
Which user does Harness use to run steps like Git Clone, Run, and so on? What is the default user ID for step containers?
Harness uses user 1000 by default. You can use a step's Run as User setting to use a different user for a specific step.
Can I enable root access for a single step?
If your build runs as non-root (meaning you have set runAsNonRoot: true in your build infrastructure settings), you can run a specific step as root by setting Run as User to 0 in the step's settings. This setting uses the root user for this specific step while preserving the non-root user configuration for the rest of the build. This setting is not available for all build infrastructures, as it is not applicable to all build infrastructures.
When I try to run as non-root, the build fails with "container has runAsNonRoot and image has non-numeric user (harness), cannot verify user is non-root"
This error occurs if you enable Run as Non-Root without configuring the default user ID in Run as User. For more information, go to CI Build stage settings - Run as non-root or a specific user.
Codebases
What is a codebase in a Harness pipeline?
The codebase is the Git repository where your code is stored. Pipelines usually have one primary or default codebase. If you need files from multiple repos, you can clone additional repos.
How do I connect my code repo to my Harness pipeline?
For instructions on configuring your pipeline's codebase, go to Configure codebase.
What permissions are required for GitHub Personal Access Tokens in Harness GitHub connectors?
For information about configuring GitHub connectors, including required permissions for personal access tokens, go to the GitHub connector settings reference.
Can I skip the built-in clone codebase step in my CI pipeline?
Yes, you can disable the built-in clone codebase step for any Build stage. For instructions, go to Disable Clone Codebase for specific stages.
Can I configure a failure strategy for a built-in clone codebase step?
No, you can't configure a failure strategy for the built-in clone codebase step. If you have concerns about clone failures, you can disable Clone Codebase, and then add a Git Clone step with a step failure strategy at the beginning of each stage where you need to clone your codebase.
Can I recursively clone a repo?
Yes. You can use Include Submodules option under Configure Codebase or Git Clone step to clone submodules recursively.
Can I clone a specific subdirectory rather than an entire repo?
Yes. For instructions, go to Clone a subdirectory.
Does the built-in clone codebase step fetch all branches? How can I fetch all branches?
You can use Fetch Tags option under Configure Codebase or Git Clone step to fetch all the new commits, branches, and tags from the remote repository. Setting this to true by checking the box is equivalent to adding the --tags flag.
Can I clone a different branch in different Build stages throughout the pipeline?
Yes. Refer to the Build Type, Branch Name, and Tag Name configuration options for the Git Clone step to specify a Branch Name or Tag Name in the stage's settings.
Can I clone the default codebase to a different folder than the root?
Yes. Refer to the Clone Directory options under the Configure Codebase or Git Clone step documentation to enter an optional target path in the stage workspace where you want to clone the repo.
What is the default clone depth setting for CI builds?
For information about the default clone depth setting, go to Configure codebase - Depth.
Can I change the depth of the built-in clone codebase step?
Yes. Use the Depth setting to do this.
How can I reduce clone codebase time?
There are several strategies you can use to improve codebase clone time:
- Depending on your build infrastructure, you can set Limit Memory to
1Giin your codebase configuration. - For builds triggered by PRs, set the Pull Request Clone Strategy to Source Branch and set Depth to
1. - If you don't need the entire repo contents for your build, you can disable the built-in clone codebase step and use a Run step to execute specific
git clonearguments, such as to clone a subdirectory.
What codebase environment or payload variables/expressions are available to use in triggers, commands, output variables, or otherwise?
For a list of <+codebase.*> and similar expressions you can use in your build triggers and otherwise, go to the CI codebase variables reference.
What expression can I use to get the repository name and the project/organization name for a trigger?
You can use the expressions <+eventPayload.repository.name> or <+trigger.payload.repository.name> to reference the repository name from the incoming trigger payload.
If you want both the repo and project name, and your Git provider's webhook payload doesn't include a single payload value with both names, you can concatenate two expressions together, such as <+trigger.payload.repository.project.key>/<+trigger.payload.repository.name>.
For more information about available codebase expressions, go to the CI codebase variables reference.
The expression eventPayload.repository.name causes the clone step to fail when used with a Bitbucket account connector.
Try using the expression <+trigger.payload.repository.name> instead.
Codebase expressions aren't resolved or resolve to null.
Empty or null values primarily occur due to the build type (tag, branch, or PR) and start conditions (manual or automated trigger). For example, <+codebase.branch> is always null for tag builds, and <+trigger.*> expressions are always null for manual builds.
Other possible causes for null values are that the connector doesn't have API access enabled in the connector's settings or that your pipeline doesn't use the built-in clone codebase step.
For more information about when codebase expressions are resolved, go to CI codebase variables reference.
How can I share the codebase configuration between stages in a CI pipeline?
The pipeline's default codebase is automatically available to each subsequent Build stage in the pipeline. When you add additional Build stages to a pipeline, Clone Codebase is enabled by default, which means the stage clones the default codebase declared in the first Build stage.
If you don't want a stage to clone the default codebase, you can disable Clone Codebase for specific stages.
The same Git commit is not used in all stages
If your pipeline has multiple stages, each stage that has Clone Codebase enabled clones the codebase during stage initialization. If your pipeline uses the generic Git connector and a commit is made to the codebase after a pipeline run has started, it is possible for later stages to clone the newer commit, rather than the same commit that the pipeline started with.
If you want to force all stages to use the same commit ID, even if there are changes in the repository while the pipeline is running, you must use a code repo connector for a specific SCM provider, rather than the generic Git connector.
Git fetch fails with invalid index-pack output when cloning large repos
- Error: During the Initialize step, when cloning the default codebase,
git fetchthrowsfetch-pack: invalid index-pack output. - Cause: This can occur with large code repos and indicates that the build machine might have insufficient resources to clone the repo.
- Solution: To resolve this, edit the pipeline's YAML and allocate
memoryandcpuresources in thecodebaseconfiguration. For example:
properties:
ci:
codebase:
connectorRef: YOUR_CODEBASE_CONNECTOR_ID
repoName: YOUR_CODE_REPO_NAME
build:
type: branch
spec:
branch: <+input>
sslVerify: false
resources:
limits:
memory: 4G ## Set the maximum memory to use. You can express memory as a plain integer or as a fixed-point number using the suffixes `G` or `M`. You can also use the power-of-two equivalents `Gi` and `Mi`. The default is `500Mi`.
cpu: "2" ## Set the maximum number of cores to use. CPU limits are measured in CPU units. Fractional requests are allowed; for example, you can specify one hundred millicpu as `0.1` or `100m`.
Clone codebase fails due to missing plugin
- Error: Git clone fails during stage initialization, and the runner's logs contain
Error response from daemon: plugin \"<plugin>\" not found - Platform: This error can occur in build infrastructures that use a Harness Docker Runner, such as the local runner build infrastructure or the VM build infrastructures.
- Cause: A required plugin is missing from your build infrastructure container's Docker installation. The plugin is required to configure Docker networks.
- Solution:
- On the machine where the runner is running, stop the runner.
- Set the
NETWORK_DRIVERenvironment variable to your preferred network driver plugin (such asexport NETWORK_DRIVER="nat"orexport NETWORK_DRIVER="bridge"). For Windows, use PowerShell variable syntax, such as$Env:NETWORK_DRIVER="nat"or$Env:NETWORK_DRIVER="bridge". - Restart the runner.
How do I configure the Git Clone step? What is the Clone Directory setting?
For details about Git Clone step settings, go to:
Does Harness CI support Git Large File Storage (git-lfs)?
Yes. Under Configure Codebase or Git Clone step, Set Download LFS Files to true to download Git-LFS files.
Can I run git commands in a CI Run step?
Yes. You can run any commands in a Run step. With respect to Git, for example, you can use a Run step to clone multiple code repos in one pipeline, or clone a subdirectory.
How do I handle authentication for git commands in a Run step?
You can store authentication credentials as secrets and use expressions, such as <+secrets.getValue("YOUR_TOKEN_SECRET")>, to call them in your git commands.
You could also pull credentials from a git connector used elsewhere in the pipeline.
Can I use codebase variables when cloning a codebase in a Run step?
No. Codebase variables are resolved only for the built-in Clone Codebase functionality. These variables are not resolved for git commands in Run steps or Git Clone steps.
Git connector fails to connect to the SCM service. SCM request fails with UNKNOWN
This error may occur if your code repo connector uses SSH authentication. To resolve this error, make sure HTTPS is enabled on port 443. This is the protocol and port used by the Harness connection test for Git connectors.
Also, SCM service connection failures can occur when using self-signed certificates.
How can I see which files I have cloned in the codebase?
You can add a Run step to the beginning of your Build stage that runs ls -ltr. This returns all content cloned by the Clone Codebase step.
Why is the codebase connector config not saved?
Changes to a pipeline's codebase configuration won't save if all CI stages in the pipeline have Clone Codebase disabled in the Build stage's settings.
Can I get a list of all branches available for a manual branch build?
This is not available in Harness.
Can I configure a trigger or manual tag build that pulls the second-to-last Git tag?
There is no built-in functionality for this.
Depending on your tag naming convention, if it is possible to write a regex that could resolve correctly for your repo, then you could configure a trigger to do this.
For manual tag builds, you need to enter the tag manually at runtime.
How can we set ENV variable for the git clone step as there is no option available in the UI to set the ENV variable for this step?
Yes. Refer to the Pre Fetch Command under the Configure Codebase or Git Clone step documentation to specify any additional Git commands to run before fetching the code.
SCM status updates and PR checks
Does Harness supports Pull Request status updates?
Yes. Your PRs can use the build status as a PR status check. For more information, go to SCM status checks.
How do I configure my pipelines to send PR build validations?
For instructions, go to SCM status checks - Pipeline links in PRs.
What connector does Harness uses to send build status updates to PRs?
Harness uses the pipeline's codebase connector, specified in the pipeline's default codebase configuration to send status updates to PRs in your Git provider.
Can I use the Git Clone step, instead of the built-in clone codebase step, to get build statues on my PRs?
No. You must use the built-in clone codebase step (meaning, you must configure a default codebase) to get pipeline links in PRs.
Pipeline status updates aren't sent to PRs
Harness uses the pipeline's codebase connector to send status updates to PRs in your Git provider. If status updates aren't being sent, make sure that you have configured a default codebase and that it is using the correct code repo connector. Also make sure the build that ran was a PR build and not a branch or tag build.
Build statuses don't show on my PRs, even though the code base connector's token has all repo permissions.
If the user account used to generate the token doesn't have repository write permissions, the resulting token won't have sufficient permissions to post the build status update to the PR. Specific permissions vary by connector. For example, GitHub connector credentials require that personal access tokens have all repo, user, and admin:repo_hook scopes, and the user account used to generate the token must have admin permissions on the repo.
For repos under organizations or projects, check the role/permissions assigned to the user in the target repository. For example, a user in a GitHub organization can have some permissions at the organization level, but they might not have those permissions at the individual repository level.
Why does the status check for my PR redirect to a different PR's build Harness?
This issue occurs when two PRs are created for the same commit ID. Harness CI associates builds with commits rather than specific PRs. If multiple PRs share the same commit, the latest build will replace the previous one, causing the build check on the earlier PR to redirect to the newer PR’s build. To resolve this, push a new commit to the affected PR and rebuild it. This creates a unique commit, ensuring the build check redirects to the correct PR.
Can I export a failed step's output to a pull request comment?
To do this, you could:
- Modify the failed step's command to save output to a file, such as
your_command 2>&1 | tee output_file.log. - After the failed step, add a Run step that reads the file's content and uses your Git provider's API to export the file's contents to a pull request comment.
- Configure the subsequent step's conditional execution settings to Always execute this step.
Does my pipeline have to have a Build stage to get the build status on the PR?
Yes, the build status is updated on a PR only if a Build (CI) stage runs.
My pipeline has multiple Build stages. Is the build status updated for each stage or for the entire pipeline?
The build status on the PR is updated for each individual Build stage.
How is the build status updated for parallel chained pipelines?
For chained pipelines, if you use a looping strategy to execute the same chained pipeline in parallel, the build status is overwritten due to the parallel chained pipelines having identical pipeline and stage IDs.
To prevent parallel chained pipelines from overwriting one another, you can try these strategies:
- Create a pipeline template for your chained pipeline, create multiple pipelines from this template that have unique pipeline identifiers, and then add those separate pipelines in parallel within the parent pipeline.
- Add a custom SCM status check at the end of the chained pipeline's Build stage that manually updates the PR with the build status. Make sure this step alway runs, regardless of the outcome of previous steps or stages.
My pipeline has multiple Build stages, and I disabled Clone Codebase for some of them. Why is the PR status being updated for the stages that don't clone my codebase?
Currently, Harness CI updates the build status on a PR even if you disabled Clone Codebase for some build stages. We are investigating enhancements that could change this behavior.
Is there any character limit for the PR build status message?
Yes. For GitHub, the limit is 140 characters. If the message is too long, the request fails with description is too long (maximum is 140 characters).
What identifiers are included in the PR build status message?
The pipeline identifier and stage identifier are included in the build status message.
What is the format and content of the PR build status message?
The PR build status message format is PIPELINE_ID-STAGE_ID — Execution status of Pipeline - PIPELINE_ID (EXECUTION_ID) Stage - STAGE_ID was STATUS
I don't want to send build statuses to my PRs. I want to disable PR status updates.
Because the build status updates operate through the default codebase connector, the easiest way to prevent sending PR status updates would be to disable Clone Codebase for all Build stages in your pipeline, and then use a Git Clone or Run step to clone your codebase.
You could try modifying the permissions of the code repo connector's token so that it can't write to the repo, but this could interfere with other connector functionality.
Removing API access from the connector is not recommended because API access is required for other connector functions, such as cloning codebases from PRs, auto-populating branch names when you manually run builds, and so on.
Why wasn't PR build status updated for an Approval stage? Can I mark the build failed if any non-Build stage fails?
Build status updates occur for Build stages only.
Failed pipelines don't block PR merges
Harness only sends pipeline statuses to your PRs. You must configure branch protection rules (such as status check requirements) and other checks in your SCM provider's configuration.
Troubleshoot Git event (webhook) triggers
For troubleshooting information for Git event (webhook) triggers, go to Troubleshoot Git event triggers.
Can we configure the CI pipeline to send the status check for the entire pipeline instead of sending it for individual stage?
Currently, the status check is sent for each CI stage execution and it can not be configured to send one status check for the entire pipeline when you have multiple CI stages within the pipeline.
How to create a pull request in github using a CI pipeline?
There isn't a built-in step available to create a PR in Git Hub from a Harness pipeline. We could run a custom script in a shell script step to invoke the GitHub API to create PR. A sample command is given below
curl -X POST -H "Authorization: token YOUR_ACCESS_TOKEN" \
-H "Accept: application/vnd.github.v3+json" \
-d '{
"title": "Pull Request Title",
"head": "branch-to-merge-from",
"base": "branch-to-merge-into",
"body": "Description of the pull request"
}' https://api.github.com/repos/OWNER/REPOSITORY/pulls
Pipeline initialization and Harness CI images
Initialize step fails with a "Null value" error or timeout
This can occur if an expression or variable is called before it's value is resolved, if a variable/expression references a secret that doesn't exist, or if an expression incorrectly references a secret (such as the incorrect scope path or secret ID).
In Build (CI) stages, steps run in separate containers/build pods, and the pipeline can only successfully resolve expressions if the target value is available.
For example, assume you have a step (named, for example, my-cool-step) that uses an expression to reference the output variable of a step in a repeat looping strategy. If my-cool-step runs before the repeat loop completes, then the expression's value isn't resolved and therefore it isn't available when my-cool-step calls that value.
Depending on how your expression/variable's value is generated, you need to either rearrange the flow of steps in your stage/pipeline or determine how you can provide the value earlier (such as by declaring it in a pipeline variable or stage variable).
With a Kubernetes cluster build infrastructure, all step-level variables must be resolved upfront during pod creation. Therefore, steps referencing output variable from prior steps in the same stage resolve as null, regardless of how the steps are arranged in your stage. To avoid this, generate the output variables in a prior stage and then use an expression referencing the value from the prior stage, for example:
<+pipeline.stages.PRIOR_STAGE.spec.execution.steps.PRIOR_STAGE_STEP.output.outputVariables.SOME_VAR>
Similarly, when using step groups or step group templates with a Kubernetes cluster build infrastructure, Harness can resolve only stage variables and pipeline variables during initialization. Step/group variables resolve as null. This is because stage and pipeline variables are available to be resolved when creating the Kubernetes pod, and step/step group variables are not. In this case, if you encounter the null value error and you are using step-level variables, try configuring these as stage or pipeline variables instead.
Make sure to update the expressions referencing the variables if you change them from step variables to stage/pipeline variables.
Initialize step occasionally times out at 8 minutes
Eight minutes is the default time out limit for the Initialize step. If your build is hitting the timeout limit due to resource constraints, such as pulling large images, you can increase the Init Timeout in the stage Infrastructure settings.
Can we run multiple steps in a single container in containerised step group?
No, You can't run all the steps in a single container, but you can run it in a single pod and share the data using shared-path config in the step group.
Problems cloning code repo during initialization.
For codebase issues, go to Codebases.
When a pipeline pulls artifacts or images, are they stored on the delegate?
Artifacts and images are pulled into the stage workspace, which is a temporary volume that exists during stage execution. Images are not stored on the delegate during pipeline execution. In a Kubernetes cluster build infrastructure, build stages run on build pods that are cleaned automatically after the execution.
Can I get a list of internal Harness-specific images that CI uses?
For information about the backend/Harness-specific images that Harness CI uses to execute builds, including how to get a list of images and tags that your builds use, go to Harness CI images.
How often are Harness CI images updated?
Harness publishes updates for all CI images on the second and fourth Monday of each month. For more information, go to Harness CI images - Harness CI image updates.
How do I get a list of tags available for an image in the Harness image registry?
To list all available tags for an image in app.harness.io/regstry, call the following endpoint and replace IMAGE_NAME with the name of the image you want to query.
https://app.harness.io/registry/harness/IMAGE_NAME/tags/list
What access does Harness use to pull the Harness internal images from the public image repo?
By default, Harness uses anonymous access to to pull Harness images.
If you have security concerns about using anonymous access or pulling Harness-specific images from a public repo, you can change how your builds connect to the Harness container image registry.
Can I use my own private registry to store Harness CI images?
Yes, you can pull Harness CI images from a private registry.
If you take this approach, you might not need all the Harness images. For example, you only need the SSCA images if you use the SSCA module.
Build failed with "failed to pull image" or "ErrImagePull"
- Error messages:
ErrImagePullor some variation of the following, which may have a different image name, tag, or registry:Failed to pull image "artifactory.domain.com/harness/ci-addon:1.16.22": rpc error: code = Unknown desc = Error response from daemon: unknown: Not Found. - Causes:
- Harness couldn't pull an image that is needed to run the pipeline.
ErrImagePullcan be caused by networking issues or if the specified image doesn't exist in the specified repository.Failed to pull image - Not Foundmeans that a Harness-specific image or tag, in this caseci-addon:1.16.22, isn't present in the specified artifact repository, and you are using theaccount.harnessImageconnector to pull Harness images. You can use this connector to pull from your own registry or to pull images from any Docker registry, but it is also used to pull Harness-required CI images. Modifying this connector can cause it to fail to pull the necessary Harness CI images.
- Solutions:
- If you modified the built-in Harness Docker connector, check the connector's configuration to make sure it uses one of the compatible methods for pull Harness-required images, as described in Connect to the Harness container image registry.
- If you are trying to pull images from your own registry, check your configuration for pulling Harness images from a private registry. You might need to use a different connecter than the built-in Harness Docker connector.
- If you modified tags for some images, check that your configuration uses valid tags that are present in the repository from which Harness is attempting to pull the tags.
- If you believe the issue is due to networking issues, try again later if you think the issue is transient, or check your connector or network configuration to make sure Harness is able to connect to the given registry.
What pipeline environment variables are there for CI pipelines?
Go to the CI environment variables reference.
Docker Hub rate limiting
By default, Harness uses anonymous Docker access to pull Harness-required images. If you experience rate limiting issues when pulling images, try the solutions described in Harness CI images - Docker Hub rate limiting.
Does the Initialize step count towards Harness Cloud build credit usage?
No. Pipeline initialization isn't included in your build minutes.
How can I fix the issue where the Git clone is being treated as a submodule?
You can resolve this by setting the Submodules Strategy to False. This will prevent the repository from being initialized as a submodule.
You can either:
- Through the UI: Go to the GitClone step in the Harness UI and set Submodules Strategy to False.
- Through the YAML: Update the pipeline YAML file by setting submoduleStrategy: "false" in the GitClone step configuration.
Build and push images
Where does a pipeline get code for a build?
The codebase declared in the first stage of a pipeline becomes the pipeline's default codebase. If your build requires files from multiple repos, you can clone additional repos.
How do I use a Harness CI pipeline to build and push artifacts and images?
You can use Build and Push steps or Run steps. For information about this go to Build and push artifacts and images.
I need to get the Maven project version from pom.xml and pass it as a Docker build argument
To do this, you can:
-
Use a Run step to get the version and assign it to a variable. For example, you could use a command like:
version=$(cat pom.xml | grep -oP '(?<=<version>)[^<]+') -
Specify this variable as an output variable from the Run step.
-
Use an expression to reference the output variable in your build arguments, such as in the Build and Push to Docker step's Build Arguments or
docker buildcommands executed in a Run step.
Where do I store Maven project settings.xml in Harness CI?
For information about this, go to Maven settings.xml.
How do I publish maven artifacts to AWS CodeArtifact?
Typically, this is configured within your Maven settings.xml file to publish artifacts upon build, as explained in the AWS documentation on Use CodeArtifact with mvn.
However, if you're not publishing directly via Maven, you can push directly using the AWS CLI or cURL, as explained in the AWS documentation on Publishing with curl.
Gradle build, daemon, OOM, and other Gradle issues
For Gradle build or daemon issues, go to the Knowledge Base article on Gradle build and daemon issues.
Can I push without building?
Harness CI provides several options to upload artifacts. The Upload Artifact steps don't include a "build" component.
Can I build without pushing?
You can build without pushing.
What drives the Build and Push steps? What is kaniko?
With Kubernetes cluster build infrastructures, Build and Push steps use kaniko. Other build infrastructures use drone-docker. kaniko requires root access to build the Docker image.
For more information, go to:
- Build and push artifacts and images - Kubernetes clusters require root access
- Harness CI images - Images list
Can I set kaniko and drone-docker runtime flags, such as skip-tls-verify or custom-dns?
Yes, you can set plugin runtime flags on any Build and Push step.
Can I run Build and Push steps as non-root? Does kaniko support non-root users?
With a Kubernetes cluster build infrastructure, Build and Push steps use the kaniko plugin. kaniko requires root access to build Docker images, and it does not support non-root users. However, you can use the buildah plugin to build and push with non-root users.
Can I run Build and Push steps as root if my build infrastructure runs as non-root?
If your build infrastructure is configured to run as a non-root user (meaning you have set runAsNonRoot: true), you can run a specific step as root by setting Run as User to 0 in the step's settings. This setting uses the root user for this specific step while preserving the non-root user configuration for the rest of the build. This setting is not available for all build infrastructures, as it is not applicable to all build infrastructures.
What if my security policy doesn't allow running as root?
If your security policy strictly forbids running any step as root, you can use the buildah plugin to build and push with non-root users.
The buildah plugin requires that you use a Kubernetes cluster build infrastructure that is configured to run as non-root with anyuid SCC (Security Context Constraints) enabled. For information about the buildah plugin, go to Build and push with non-root users.
Can I enable BuildKit support with Build and Push steps? How do I run Docker build commands with buildkit enabled?
The Build and Push steps use kaniko or drone-docker to build images. If you need to use BuildKit, you can't use the built-in Build and Push steps.
Instead, you need to:
-
Run
docker buildanddocker pushcommands in a Run step. To rundocker buildwith builtkit enabled, use something like:DOCKER_BUILDKIT=1 docker build -t IMAGE_NAME:TAG .
Is there a way to use a newer or older version of kaniko?
Yes, you can update the tag for the kaniko image that Harness uses, as explained in Harness CI images - Specify the Harness CI images used in your pipelines.
Does a kaniko build use images cached locally on the node? Can I enable caching for kaniko?
By default, kaniko does not use the node cache. It performs a full container image build from scratch, so it always pulls the base image. If you want kaniko to cache images and use previously-built layers that haven't changed, specify the Remote Cache Repository setting in the Build and Push step. If not specified, caching isn't used. Layer caching can significantly speed up the image building process.
How can I improve build time when a Build and Push step isn't able to apply remote caching or doesn't cache effectively?
Make sure your Docker file is configured in least- to most-often changed. Make sure it installs dependencies before moving other files. Docker Layer Caching depends on the order that layers are loaded in your Dockerfile. As soon as it detects a changed layer, it reloads all subsequent layers. Therefore, may sure your Dockerfile is structured for optimum caching efficiency.
Where does the Build and Push to ECR step pull the base images specified in the Dockerfile?
By default, the Build and Push to ECR step downloads base images from the public container registry. You can use the Base Image Connector setting to specify an authenticated connector to use. This can prevent rate limiting issues.
How can I configure the Build and Push to ECR step to pull base images from a different container registry or my internal container registry?
Create a Docker connector for your desired container registry and use it in the Base Image Connector setting.
Build and Push to ECR step fails with error building image, failed to execute command, exec format error
- Error:
Error building image: error building stage: failed to execute command: starting command: ...: exec format error - Cause: This error can occur if you're running an ARM node pool instead of AMD.
- Solution: Change your node pool to AMD and retry the build.
Build and Push to ECR step fails with error checking push permissions
Go to the Build and Push to ECR error article.
Where does the Build and Push step expect the Dockerfile to be?
The Dockerfile is assumed to be in the root folder of the codebase. You can use the Dockerfile setting in a Build and Push step to specify a different path to your Dockerfile.
Can I use Harness expressions in my Dockerfile?
No. Harness expressions aren't supported in Dockerfiles.
Why isn't the Build and Push step parsing the syntax in my Dockerfile?
In a Kubernetes cluster build infrastructure, Build and Push steps use kaniko, which doesn't support # syntax in the Dockerfile.
If you need to parse syntax in your builds, you can't use the Build and Push steps. Instead, you can use the buildah plugin or run Docker-in-Docker in a Background step with buildkit enabled.
Why doesn't the Build and Push step include the content of VOLUMES from my Dockerfile in the final image?
In a Kubernetes cluster build infrastructure, the Build and Push steps use kaniko. Kaniko optimizes the build process by creating directories for volumes, but it skips copying the contents into image layers. This behavior is expected and enhances the efficiency of the build.
If you want to include the volume content in the image layers, consider using COPY instructions in your Dockerfile to directly copy the data into the image during the build.
Can I use images from multiple Azure Container Registries (ACRs)?
Yes. Go to Use images from multiple ACRs.
Is remote caching supported in Build and Push steps?
Harness supports multiple Docker layer caching methods depending on what infrastructure is used. Go to Docker layer caching to learn more.
Build and Push to Docker fails with kaniko container runtime error
Go to the Kaniko container runtime error article.
When using 'Build ans Push' steps with Base Image connector, can I pull and push from two different docker registries that have same prefix for registry URL ?
No, when using base image connector, ensure the prefix of the url use for pulling is different than the prefix of the url in the connector used for pushing.
Docker uses a configuration file to store authentication details. If two registry URLs share the same prefix, Docker will only create a single authentication entry for that prefix, which will cause a conflict when accessing the second registry.
As an example, both https://index.docker.io/v1/abc/test1 and https://index.docker.io/v1/xyz/test2 have the same prefix https://index.docker.io/v1/, so Docker cannot differentiate between them for authentication, causing the second set of credentials to overwrite the first.
What is the default build context when using Build and Push steps?
The default build context is the stage workspace directory, which is /harness.
Why is the Build and Push step trying to push to a public Docker Hub repository even though the connector used in the step points to an internal container registry?
This can occur if the Build and Push step doesn't have the repo's Fully Qualified Name (FQN), even if your Docker connector points to an internal private container registry.
Make sure to use the FQN for the repo when pushing to an internal private container registry.
Why do I get an out of memory error when pushing images to Docker Hub?
The Build and Push to Docker step can return out of memory errors, such as:
exit status 255 Found possible error on line 70. Log: signal: killed . Possible error: Out of memory. Possible resolution: Increase memory resources for the step
To address this error, enable the Optimize setting in the Build and Push step.
You can also try adjusting container resources, if these settings are applicable to your build infrastructure.
Can I configure build secrets on Build and Push steps?
No. Currently, Build and Push steps don't support build secrets.
Which step can I use to build and push to a JFrog Docker registry?
You can use the Build and Push to Docker step to build and push to JFrog Docker registries.
Why build and push to ECR step is failing with the error failed to create docker config: Username must be specified for registry?
This could happen when you have the build and push to ECR step with a base connecter which is configured with anonymous auth type. Base connector configured in the build and push to ECR step should be an authenticated connector
Why is the kaniko flags with the built-in in build and push step is not working when we run the build on Harness cloud?
The build and push step doesn’t use kaniko while running the build on Harness cloud instead it uses drone-docker plugin hence the kaniko flags wont work
Does Harness have an artifact repository where the artifacts generated in the CI stage can be pushed and then use them in the subsequent CD stages?
Harness currently doesn't provide a hosted artifact repository however you can push the artifact to the other popular artifact repos. More details about the same can be referred in the doc
Why Build and Push Steps Don't Support V2 API URLs?
If you encounter authentication errors when using https://registry.hub.docker.com/v2/ or https://index.docker.io/v2/ during build and push steps, consider either using V1 API URLs or authenticating with a Personal Access Token (PAT) for V2 API URLs.
When using the V2 Docker registry API, authentication issues can arise due to how authorization tokens are generated. Specifically, the JWT (JSON Web Token) used for authentication in the V2 API may lack the proper scope required for push/pull actions.
Here’s the key difference:
-
Username/Password Authentication: When using a username and password, the generated token often lacks the necessary scope details (e.g., actions like
pushandpull). This can cause issues when trying to authenticate with the registry during build and push steps. -
Personal Access Token (PAT) Authentication: A PAT provides more detailed scope information in the authentication headers, ensuring the correct access levels for pushing and pulling images. With a PAT, the JWT scope is properly set, allowing seamless authentication for build and push operations.
Here’s an example of a properly scoped token when using a PAT:
{
"access": [
{
"actions": [
"pull",
"push"
],
"name": "your-username/test-private-repo",
"parameters": {
"pull_limit": "200",
"pull_limit_interval": "21600"
},
"type": "repository"
}
],
"aud": "registry.docker.io",
"exp": 1724982164,
"https://auth.docker.io": {
"at_id": "02874e98-c6ce-46ed-934b-57d184441c38",
"pat_id": "02874e98-c6ce-46ed-934b-57d184441c38",
"plan_name": "free",
"username": "your-username"
}
}
In this example, the actions (pull, push) and the repository name are correctly defined, ensuring the token provides the appropriate access permissions.
To avoid authentication issues, it's recommended to either use a PAT when configuring build and push steps for Docker registries with the V2 API or, if using a username and password, switch to the V1 API.
Authentication issues (toomanyrequests: You have reached your unauthenticated pull rate limit.)
Harness Cloud Setup with Build and Push Steps
If you are using Harness Cloud, please note that anonymous pulls will be tied to the IP pool assigned to the region for all Harness customers. This means that all Harness customers would utilize the same pool of "rate limit" as defined by Docker.
In order to resolve these issues, customers should look to enable CI_ENABLE_BASE_IMAGE_DOCKER_CONNECTOR feature with our support team to allow teams to select the Base Image connector that would be utilized to pull the image. Please keep in mind the rules regarding Docker API versions for the Docker Registry URL (Please see the above information that goes into detail about how and why this occurs and what to do)
In most cases customer should set up a Docker Connector utilizing the https://index.docker.io/v1 registry URL for Harness Cloud builds.
Please also note that if you receive a "You have reached your unauthenticated pull rate limit." message even after setting up a Base Image Connector, this indicates a failure in resolving the JWT token, which causes the pull to default back to attempting an unauthenticated request.
Docker Connector with Valid Credentials but using a Private Registry/Improper configuration
Customers may encounter the toomanyrequests: You have reached your unauthenticated pull rate limit. error for their Build and Push steps (ECR, Docker, etc) despite having a valid Docker Connector set and credentials.
This is due to utilizing the v2 registry API for a private repository pull. The fallback will be that Docker will attempt an unauthorized request, which results in the above response. Please see the above information that goes into detail about how and why this
occurs and what to do.
Please note that the key is located in the unauthenticated part of the message. If you are hitting a rate limit with your credentials, the message will not include a reference to an unauthenticated pull request.
How can user access the secrets as files in a Docker build without writing them to layers?
The build and push steps used to build Docker images have a context field. Users can use the context field in the build and push steps to mount the current directory at /harness. By copying your files to a specific directory and then mounting them, you can avoid writing secrets into the Docker image layers.
Why do Build and Push steps fail with "Error while loading buildkit image: exit status 1" when /var/lib/docker is included in shared paths during DIND execution?
Build and Push steps fail with the error "Error while loading buildkit image: exit status 1" when /var/lib/docker is included in the shared paths during Docker-in-Docker (DIND) execution because DIND creates a Docker daemon using this path, and sharing it across steps causes conflicts when multiple build steps try to create and access their own Docker daemons. To resolve this, remove /var/lib/docker from the shared paths configuration, which prevents conflicts and allows Build and Push steps to execute successfully.
How can I block or restrict image pulls in my Harness CI pipelines?
To enforce stricter network control or restrict use of external registries during CI builds, here are two common approaches:
Option 1: Use a Run Step to Dynamically Block a Website (e.g., a registry)
You can block network access to specific domains like example.com by using a Run step in your pipeline that applies iptables rules before any potentially unsafe step runs.
Here’s a sample Harness CI pipeline that blocks access to example.com:
pipeline:
name: blockwebsiteexample
identifier: blockwebsiteexample
projectIdentifier: PROJECT_NAME
orgIdentifier: default
stages:
- stage:
name: test
identifier: test
type: CI
spec:
cloneCodebase: false
caching:
enabled: true
buildIntelligence:
enabled: true
platform:
os: Linux
arch: Amd64
runtime:
type: Cloud
spec: {}
execution:
steps:
- step:
type: Run
name: Run_1
identifier: Run_1
spec:
shell: Bash
command: |-
DOMAIN="example.com"
IPS=$(dig +short $DOMAIN | grep -Eo '([0-9]{1,3}\.){3}[0-9]{1,3}')
for IP in $IPS; do
sudo iptables -A OUTPUT -d "$IP" -j REJECT
done
- step:
type: Run
name: Run_2
identifier: Run_2
spec:
shell: Sh
command: curl -I https://example.com
- step:
type: Run
name: Run_3
identifier: Run_3
spec:
shell: Bash
command: |-
DOMAIN="example.com"
IPS=$(dig +short $DOMAIN | grep -Eo '([0-9]{1,3}\.){3}[0-9]{1,3}')
for IP in $IPS; do
sudo iptables -D OUTPUT -d "$IP" -j REJECT
done
when:
stageStatus: All
- step:
type: Run
name: Run_4
identifier: Run_4
spec:
shell: Sh
command: curl -I https://example.com
when:
stageStatus: All
Use this when:
-
You want to restrict access to specific URLs during pipeline execution.
-
You need fine-grained, dynamic blocking based on domains or IPs.
-
You're running builds in Harness Cloud with Linux runners.
Option 2: Use OPA Policy to Deny docker pull Commands
For governance at scale, you can apply OPA policies to deny pipelines that contain docker pull or other blacklisted commands.
Here’s a sample OPA policy:
package pipeline
# Deny build pipelines that don't push to "us.gcr.io"
# NOTE: Try changing the expected host to see the policy fail
deny[msg] {
# Find all stages ...
stage = input.pipeline.stages[_].stage
# ... that are used for CI
stage.type == "CI"
# ... that have steps
step = stage.spec.execution.steps[_].step
# ... that build and push to GCR steps
step.type == "Run"
contains_keyword := regex.match("\\bdocker pull\\b", step.spec.command)
contains_keyword
# Generate a message indicating the forbidden keyword usage
msg := sprintf("Step '%s' in stage '%s' contains a docker pull command.", [step.name, stage.name])
}
Use this when:
-
You want to enforce compliance across many teams or orgs
-
You don’t want to manually edit pipelines
-
You prefer policy-as-code to manage CI guardrails
Upload artifacts
Can I send emails from CI pipelines?
You can use the Drone Email plugin to send emails and attachments from CI pipelines.
How do I show content on the Artifacts tab?
You can use the Artifact Metadata Publisher plugin to store artifact URLs and display them on the Artifacts tab.
Is it possible to publish custom data, such as outputs from variables or custom messages, to the Artifacts tab?
Currently, the Artifacts tab contains only links. Therefore, any content you want to make available on the Artifacts tab must be uploaded to cloud storage and then queried. You can use the Artifacts Metadata Publisher plugin for this.
You can provide one or more URLs to artifacts. For example, to reference artifacts stored in S3 buckets, you can provide the URL to the target artifact, such as https://BUCKET.s3.REGION.amazonaws.com/TARGET/ARTIFACT_NAME_WITH_EXTENSION. If you uploaded multiple artifacts, you can provide a list of URLs. If your S3 bucket is private, use the console view URL, such as https://s3.console.aws.amazon.com/s3/object/BUCKET?region=REGION&prefix=TARGET/ARTIFACT_NAME_WITH_EXTENSION.
In addition to the console view URL, you can reference privately-stored artifact by generating pre-signed URLs or temporary URLs, such as Google Cloud Storage signed URLs or AWS S3 pre-signed URLs.
Does the Upload Artifacts to S3 step compress files before uploading them?
No. If you want to upload a compressed file, you must use a Run step to compress the artifact before uploading it.
Can I trim the parent folder name before uploading to S3?
Yes. Go to Trim parent folder name when uploading to S3.
Connector errors with Upload Artifacts to S3 step.
There are a variety of potential causes for AWS connector errors due to specific requirements for the AWS connector in the Upload Artifacts to S3 step.
Can I use non-default ACLs, IAM roles, or ARNs with the Upload Artifacts to S3 step?
Yes, but there are specific requirements for the AWS connector in the Upload Artifacts to S3 step.
Does the Upload Artifacts to GCS step support GCP connectors that inherit delegate credentials?
No. Currently, the Upload Artifacts to GCS step doesn't support GCP connectors that inherit delegate credentials.
Upload Artifacts to JFrog step throws certificate signed by unknown authority
If you get a certificate signed by unknown authority error with the Upload Artifacts to JFrog step, make sure the correct server certificates are uploaded to the correct container path. For example, the container path for Windows is C:/Users/ContainerAdministrator/.jfrog/security/certs.
Can I run the Upload Artifacts to JFrog Artifactory step with a non-root user?
Yes. By default, the jfrog commands in the Upload Artifacts to JFrog Artifactory step create a .jfrog folder at the root level of the stage workspace, which fails if you use a non-root user.
Set JFROG_CLI_HOME_DIR as Stage variable to change the folder in which .jfrog will be created, to a path you have write access.
mkdir permission denied when running Upload Artifacts to JFrog as non-root
With a Kubernetes cluster build infrastructure, the Upload Artifacts to JFrog step must run as root. If you set Run as User to anything other than 0, the step fails with mkdir /.jfrog: permission denied.
What is PLUGIN_USERNAME and PLUGIN_PASSWORD used in the Upload Artifacts to JFrog Artifactory step?
These are derived from your Artifactory connector.
Can I upload files at the root of an S3 bucket?
Currently, you can't upload files to the root of an S3 bucket due to the glob pattern that Harness uses.
If there are too many nested directories in your uploaded files, you can use a Run step to flatten nested directories to cache before running the Save Cache or Upload Artifact step. users can have a run step to flatten the directory before uploading.
How can user resolve S3 bucket permission issue in save cache in S3 step?
If the AWS connector is configured with the cross-account role ARN, the user needs to configure the PLUGIN_USER_ROLE_ARN stage variable as suggested in this doc
Test reports
Test reports missing or test suites incorrectly parsed
The parsed test report in the Tests tab comes strictly from the provided test reports (declared in the step's Report Paths). Test reports must be in JUnit XML format to appear on the Tests tab, because Harness parses test reports that are in JUnit XML format only. It is important to adhere to the standard JUnit format to improve test suite parsing. For more information, go to Format test reports.
What if my test tool's default report format isn't JUnit?
There are converters available for many test tools that don't produce results in JUnit format by default.
For example, the default report format for Jest is JSON, and you can use the Jest JUnit Reporter to convert the JSON results to JUnit XML format.
For more information, go to Format test reports.
Can I specify multiple paths for test reports in a Run step?
Yes, you can specify multiple paths for test reports. Ensure that the reports do not contain duplicate tests when specifying multiple paths.
Why is the test report truncated in Tests tab?
The Tests tab truncates content if a field in your test report XML file surpasses 8,000 characters.
Run step in a containerized step group can't publish test reports, and it throws "Unable to collect test reports" though the report path is correctly
Currently, publishing test reports from a Run step in a CD containerized step group is not supported. Try running your tests in a Build (CI) stage.
Is the Tests tab only for Test Intelligence?
No. Test reports from tests run in Run steps also appear there if they are correctly formatted.
Test splitting
Does Harness support test splitting (parallelism)?
Yes, you can split tests in Harness CI.
Does Test Intelligence split tests? Why would I use test splitting with Test Intelligence?
Test Intelligence doesn't split tests. Instead, Test Intelligence selects specific tests to run based on the changes made to your code. It can reduce the overall number of tests that run each time you make changes to your code.
For additional time savings, you can apply test splitting in addition to Test Intelligence. This can further reduce your test time by splitting the selected tests into parallel workloads.
How can I receive an execution report via email for our Test suite in Harness?
In Harness, you can use the Email plugin in your CI pipeline to export reports and other artifacts via email. This allows you to send the execution report directly to your desired recipients without needing to push it to a Git repository.
For more details on how to set up the email notifications, you can refer to these documents: Using the Email Plugin in CI Exploring CI Plugins in Harness
Build Intelligence
What affects hash key calculation in Build Intelligence?
Build Intelligence uses a hash key to manage cache artifacts. This hash is derived from a combination of:
-
Source code contents
-
Build tool arguments
-
Build dependencies
-
Build configuration files (e.g., pom.xml)
-
The build environment
Any change in these elements — even small ones — will result in a new hash key, and therefore a different cache entry.
This behavior is driven by the build tool itself, not Harness. For more details, refer to the official Apache Maven Build Cache Extension documentation.
Test Intelligence
How do I use Test Intelligence?
For instructions, go to Test Intelligence overview.
Can Test Intelligence speed up my build times? What are the benefits of Test Intelligence?
Test Intelligence improves test time by running only the unit tests required to confirm the quality of the code changes that triggered a build. It can identify negative trends and help you gain insight into unit test quality. For more information, go to Test Intelligence overview.
What criteria does Test Intelligence use to select tests?
For information about how Test Selection selects tests, go to Test Intelligence overview.
If the Run Tests step fails, does the Post-Command script run?
No. The Post-Command script runs only if the Run Tests step succeeds.
Can I limit memory and CPU for Run Tests steps running on Harness Cloud?
No. Resource limits are not customizable when using Harness Cloud or self-managed VM build infrastructures. In these cases, the step can consume the entire memory allocation of the VM.
Does TI work if I disable Clone Codebase?
Test Intelligence requires that you use enable the built-in Clone Codebase functionality.
Test Intelligence won't work if you clone your repo only through a Git Clone step or a Run step.
How can I understand the relationship between code changes and the selected tests?
On the Tests tab, the visualization call graph provides insights into why each test was selected. It visually represents the relationship between the selected tests and the specific code changes in the PR. For more information, go to View tests - Results from Test steps with Test Intelligence.
On the Tests tab, the Test Intelligence call graph is empty and says "No call graph is created when all tests are run"
No call graph is generated if Test Intelligence selects to run all tests because the call graph would be huge and not useful (no test selection logic to demonstrate).
Additionally, the first run with TI doesn't include test selection, because Harness must establish a baseline for comparison in future runs. On subsequent runs, Harness can use the baseline to select relevant tests based on the content of the code changes.
For information about how and when TI selects tests, go to How does Test Intelligence work?
Ruby Test Intelligence can't find rspec helper file
The following log line indicates that Test Intelligence can't locate an rspec helper file in your code repo:
Unable to write rspec helper file automatically cannot find rspec helper file. Please make change manually to enable TI.
This usually occurs if the helper file has a name other than spec_helper.rb.
To resolve this, add the following line to your rspec helper file:
set -e; echo "require_relative '/tmp/engine/ruby/harness/ruby-agent/test_intelligence.rb'" >> lib/vagrant/shared_helpers.rb
Can I use Test Intelligence for Ruby on Rails?
You can. However, Harness doesn't recommend using Test Intelligence with Rails apps using Spring.
Test Intelligence fails with error 'Unable to get changed files list'
This error means that Test Intelligence was not able to retrieve the list of changed files because the depth of the clone is too low and the history of the reference commit is not found. To fix this please increase the depth in the clone codebase section to a higher number and try again.
Test Intelligence fails due to Bazel not installed, but the container image has Bazel
If your build tool is Bazel, and you use a container image to provide the Bazel binary to the Run Tests step, your build will fail if Bazel isn't already installed in your build infrastructure. This is because the Run Tests step calls bazel query before pulling the container image.
Bazel is already installed on Harness Cloud runners. For other build infrastructures, you must manually confirm that Bazel is already installed. If Bazel isn't already installed on your build infrastructure, you need to install Bazel in a Run step prior to the Run Tests step.
Python Test Intelligence errors
If you encounter errors with Python TI, make sure that:
- Your project is written in Python 3, and your repo is a pure Python 3 repo.
- You don't use resource file relationships. TI for Python doesn't support resource file relationships.
- You don't use dynamic loading and metaclasses. TI for Python might miss tests or changes in repos that use dynamic loading or metaclasses.
- Your build tool is pytest or unittest.
- The Python 3 binary is present. This means it is preinstalled on the build machine or available in the step's Container Registry and Image.
- If you use another command to invoke Python 3, such as
python, you have added an alias, such aspython3 = "python". - If you get code coverage errors, your Command doesn't need coverage flags (
--covorcoverage).
Why some of my C# classes are not being discovered by Test Intelligence?
Currently, the C# support still has some limitations where classes that reside in a file that doesn't match their name are not being discovered by the agent. For now, we recommend that all the classes that are part of the application would reside in a file of their own name. This limitation is tracked and expected to be lifted in the future.
Does Test Intelligence support dynamic code?
Harness doesn't recommend using TI with Ruby projects that use dynamically generated code or Python projects that use dynamic loading or metaclasses.
Why did Test Intelligence Skip Analysis
Sometimes, teams may see that tests appear to have been a part of an execution and build, but for some reason, the selected tests are 0, and there is no data on the test having been completed
 In the logs, customers may notice a blank array of tests selected by Test Intelligence
In the logs, customers may notice a blank array of tests selected by Test Intelligence level=info msg="Running tests selected by Test Intelligence: []" to be run. There are several reasons why this may happen, and they are often related to how Test Intelligence behaves, as outlined in our TI Overview.
Tests were skipped because Code Changes and Test have no overlap
Test Intelligence may choose to ignore or pass on tests if the code changes that were executed, are irrelevant to the tests. This is because it is choosing to skip tests to save time. For example, changes to a readme file would not invoke Java tests outlined and defined. Likewise, changes to files within the ignore tests/files definitions will also cause Test Intelligence to Skip the tests.
Git Branch execution builds
Customers choosing to define a build type for the CI Codebase as a Git Branch may also find odd behavior on re-runs on the same branch
This is because the tests associated with the branch are tied to a specific Commit ID. If the Commit ID does not change in subsequent steps or executions, Test Intelligence will see that a test result is already associated. This causes Test Intelligence to consider the testing complete, and on subsequent executions, it does not see a need to rerun a completed test. This would be expected behavior for Test Intelligence, as TI would consider a re-run unnecessary if nothing has changed.
Customers are recommended to either change their Build Type to a Git Pull Request to ensure the test is run on each PR (and new Commit ID), or they can clone the Git Branch to cause a re-execution on the test.
Why is the cache intelligence is not saving the cache from the default yarn location?
This could happen if you have a custom path added in the cache intelligence config. If you want the YARN cache to be picked from the default location, make sure you don’t configure cache intelligence with a custom path
Can user import test results from a generic 'mvn clean deploy' Run step into the test Dashboard? Or must use the Unit Test step to display them on that tab?
Yes, you can use the Run step to run your maven command and upload the test results. There is a field for this in the run step (like in the run tests step). Please check the documentation for more information.
The RunTests allow you to not only run your tests, but also to use Test Intelligence to run only unit tests that are relevant to the code changes made, thus cutting down the test cycle time.
how can user add the exclusion for jacoco code coverage report?
pom.xml allows using environment variable references with syntax like below:
${env.VARIABLE_NAME}
You can not directly use harness expression in pom.xml but you can use harness expression to pass the values to environment variables which then in turn can be used in pom.xml.
Tests with Test Intelligence enabled are not showing any data results, despite having worked previously
When Test Intelligence is first run, a call graph is generated based on the published branch and commit ID. This is associated specifically with the branch and commit ID, even across pipelines, to allow Test Intelligence to be as efficient as possible.
If the same code is used in multiple pipelines, it would leverage the existing callgraph, if one already exists, allowing TI to help developers reduce the number of necessary tests they have to go through.
With this in mind, unless there are changes to the relevant code or test, Test Intelligence will end up skipping the tests
This can be observed with the following log

Script execution
Does Harness CI support script execution?
Yes. Go to Run scripts.
Running a Python shell in a Run step, the expression <+codebase.gitUser> resolves to "None"
This means the codebase variable wasn't resolved or resolved to None. Codebase expression values depend on the build trigger type, among other factors.
Can I use an image that doesn't have a shell in a Run step?
The Run step requires the Command and Shell fields. Some shell must be available on the specified image to be able to run commands.
Is a Docker image required to use the Run step on local runner build infrastructure?
Yes. Container Registry and Image are always required for Run steps on a local runner build infrastructure. For more information about when Container Registry and Image are required, go to Use Run steps - Container Registry and Image.
Is it required for a Run step's image to have Docker and Docker CLI installed?
If your step needs to execute Docker commands, then the image needs to have Docker and the Docker CLI.
When attempting to export an output variable from a Run step using a Python shell, the step fails with "no such file or directory"
This can happen if you manually exit the Python script by calling exit(0). When you declare an output variable in a Run step, Harness runs some additional code at the end of your script to export the variable. If you exit the script manually in your Run step's command, then Harness can't run those additional lines of code.
Secrets with line breaks and shell-interpreted special characters
For information about handling secrets with new line characters or other shell-interpreted special characters, go to Add and reference text secrets - Line breaks and shell-interpreted characters and Use GCP secrets in scripts.
When does Harness decrypt secrets referenced in Run steps?
Harness decrypts all secrets referenced in a Build stage during the Initialize step that automatically runs at the beginning of any stage.
Output variable length limit
If an output variable's length is greater than 64KB, steps can fail or truncate the output. If you need to export large amounts of data, consider uploading artifacts or exporting artifacts by email.
Multi-line output variables truncated
Output variables don't support multi-line output. Content after the first line is truncated. If you need to export multi-line data, consider uploading artifacts or exporting artifacts by email.
How do I get a file from file store in a Run step?
You can use a file store reference expression to get a file from file store, such as <+fileStore.getAsBase64("someFile")>.
Here's an example in a script:
raw_file=<+fileStore.getAsBase64("someFile")>
config_file="$(echo "$raw_file" | base64 --decode)"
File store expressions don't work for all secrets, and some secrets require additional handling.
For more information, go to:
Can I start containers during pipeline execution? For example, I need to start some containers while executing tests.
You could do this by running DinD in a Background step so that those services are available when you need to reference them during pipeline execution.
Why doesn't Harness use the GCP connector in my Run step to pull the image?
If your GCP connector inherits credentials from the delegate, Harness uses the node pool's authentication configuration while pulling the image. Harness can't extract the secret and mount it under imagePullSecrets in this case.
Can I tag code committed from a Harness pipeline?
When Harness performs an automated commit in your codebase, you can't tag the code. However, if your pipeline includes commits to your codebase, you can include the tag commands in your script.
Entry point
What does the "Failed to get image entrypoint" error indicate in a Kubernetes cluster build?
This error suggests that there is an issue accessing the entrypoint of the Docker image. It can occur in a Kubernetes cluster build infrastructure when running PostgreSQL services in Background steps.
To resolve this error, you might need to mount volumes for the PostgreSQL data in the build infrastructure's Volumes setting, and then reference those volumes in the Background step running your PostgreSQL instance. For instructions, go to Troubleshooting: Failed to get image entry point.
Does the Harness Run step overwrite the base image container entry point?
Yes, this is the expected behavior. The entry point in the base image is overwritten so Harness can run the commands specified in the Run step.
Why is the default entry point not running for the container image used in the Run step?
The default entry point is overwritten by the commands you specified in the Run step's commands.
Since the default entry point isn't executed for the container image used in the Run step, how do I start a service started in a container that would usually be started by the default entry point?
You can run the service in a Background step, which can execute the default entry point.
How do I run the default entry point of the image used in the Run step?
The commands specified in the Run step's commands override the default entry point. If you want to run those commands in the Run step, you need to include them in the Run step's commands.
Docker in Docker
Does CI support running Docker-in-Docker images?
Yes. For details, go to Run Docker-in-Docker in a Build stage.
Can I run docker-compose from Docker-in-Docker in a Background step?
Yes.
Is privileged mode necessary for running DinD in Harness CI?
Yes, Docker-in-Docker (DinD) must run in privileged mode to function correctly.
Generally, you can use DinD on platforms that don't support privileged mode, such as platforms that run containers on Windows or fargate nodes that don't support privileged mode.
Why is my DinD Background step failing with "Pod not supported on Fargate: invalid SecurityContext fields: Privileged"?
This error occurs because AWS Fargate doesn't support the use of privileged containers. Privileged mode is required for DinD.
Can't connect to Docker daemon
Go to GitHub Action step can't connect to Docker daemon.
DinD Background step fails when Docker daemon disconnects or hit quota limit after some time
This typically indicates that the DinD Background step doesn't have sufficient resources. Try modifying the container resources for the Background step.
You can also add a parallel Run step to monitor and help debug the Background step. For example, in this case it would help to use the Run step to monitor resource consumption by the Background step.
My DinD build fails with an Out Of Memory error, but I increased the memory and CPU limit on the Run step that runs my docker build command
If you run Docker-in-Docker in a Background step, and your docker build commands fail due to OOM errors, you need to increase the memory and CPU limit for the Background step. While the docker build command can be in a Run step or a Build and Push step, the build executes on the DinD container, which is the Background step running DinD. Therefore, you need to increase the container resources for the Background step.
My pipeline runs DinD in a Background step, and I need to start another container in a subsequent run step. How can I connect to the application running in the Background step from the Run step?
When you start the container in the Run step, attach the container to host network by passing the flag --net host. Then, you can hit the endpoint localhost:PORT from the run step to connect to the application running inside the container.
For more information go to Background step settings - Name and ID.
Plugins and integrations
Which Drone plugins are supported in Harness CI?
You can build your own plugins or use one of the many preexisting plugins from the Drone Plugins Marketplace. For more information, go to Explore plugins.
How do I convert Drone plugin settings to Harness CI?
For information about using Drone plugins in Harness CI, including converting Drone YAML to Harness YAML, go to Use Drone plugins.
How do I add a custom plugin to my Harness CI pipeline?
For instructions on writing and using custom plugins, go to Write custom plugins.
Can I test my custom plugin before using it in a pipeline?
Yes, you can test plugins locally.
Why is the PATH variable overwritten in parallel GitHub Actions steps?
When steps run in parallel and modify the same variables, the resulting value of that common variable depends on the step that modified it last. This can be different with each build, depending on how fast each parallel step executes. This is true for any parallel steps.
When running multiple instances of the same GitHub Action, you must set XDG_CACHE_HOME, as explained in Duplicate Actions.
If you need a variable's value to remain distinct, either run the steps sequentially (rather than in parallel), or find a way to differentiate the variable that each step is modifying, such as by exporting each value as an output variable where you use looping strategy expressions to assign unique identifiers to each variable name.
GitHub Action step can't connect to Docker daemon
Error messages like cannot connect to the Docker daemon indicate that you might have multiple steps attempting to run Docker at the same time. This can occur when running GitHub Actions in stages that have Docker-in-Docker (DinD) Background steps.
Actions that launch DinD: You can't use GitHub Actions that launch DinD in the same stage where DinD is already running in a Background step. If possible, run the GitHub Action in a separate stage or try to find a GitHub Action that doesn't use DinD.
Actions that launch the Docker daemon: If your Action attempts to launch the Docker daemon, and you have a DinD Background step in the same stage, you must add PLUGIN_DAEMON_OFF: true as a stage variable. For example:
variables:
- name: PLUGIN_DAEMON_OFF
type: String
description: ""
required: false
value: "true"
Harness Cloud: You don't need DinD Background steps with Harness Cloud build infrastructure, and you can run GitHub Actions in Action steps instead of Plugin steps.
GitHub Action step fails with "not a git repository or any of the parent directories"
This error occurs if the GitHub Action you're using requires a codebase to be present, such as the GraphQL Inspector or DevCycle Feature Flag Code Usages Actions. The Action step isn't compatible with such Actions at this time.
If the Action allows you to override the working-directory, such as with the CodeCov Action, you can use this setting to specify the correct working directory. If no such setting is available, then the Action is not compatible with Harness CI at this time.
Can I integrate my CI builds with the Datadog Pipeline Visibility feature?
Harness doesn't have OOTB support for Datadog Pipeline Visibility, but you can use the Datadog Drone plugin in a Plugin step.
How is the Plugin step's entrypoint retrieved during a build?
Harness connects to the container registry endpoint, based on the container registry specified in the step settings, to retrieve the entrypoint.
If you want to avoid this additional call to the container registry, you can configure the entry point directly in the Plugin (if possible, such as with a custom plugin).
Why is the Plugin step trying to fetch the entrypoint from the public Docker Hub endpoint even though the connector used in the step points to an internal container registry?
This can occur if a Plugin step doesn't have the image's Fully Qualified Name (FQN), even if your Docker connector points to an internal private container registry.
Make sure to use the FQN for the image when pulling from an internal private container registry.
What tool does a Harness GitHub Action plugin use in the backgound to run an action?
The Github Action Drone plugin uses nektos/act in the background to run GitHub Actions.
Does the Harness Github Action plugin support exporting output variables?
Currently the Github action plugin doesn’t support exporting the output variable, however the built-in Github Action step that can be added in Harness Cloud build pipeline supports exporting output variables.
Which container image is being by the Harness Github Action plugin to run the github action?
The current version of nektos/act used in the github action plugin uses the image node:12-buster-slim to run the action.
Do we need a Docker-in-Docker (dind) container running in the background step to be able to run Harness GHA plugin?
Docker-in-Docker is not required to be run as a background step because the GHA plugin image is built with the dind base image making it readily available within the GHA plugin.
How do we configure the stage variable PLUGIN_STRIP_PREFIX if we have 2 upload to s3 steps that needs to trim different keywords from the file path?
Since this stage variable accessible to all the steps, currently it is not supported to trim the different keywords from the file path if both the Upload to s3 steps are part of the same CI stage.
How can we upload all the files including the directory when using the upload artifacts to jfrog antifactory step?
You could append the directory name in the target path which should create a folder with the same name in the artifactory and the files will be uploaded inside this directory
Workspaces, shared volumes, and shared paths
What is a workspace in a CI pipeline?
Workspace is a temporary volume that is created when a pipeline runs. It serves as the current working directory for all the steps within a stage. You can use Shared Paths to share additional volumes to the workspace. For more information about the workspace and shared paths go to CI pipeline creation overview - Shared Paths.
Does the workspace persist after a stage ends?
No, the workspace is destroyed when the stage ends. If you need to shared data across stages, use caching.
How do I share data and volumes between steps in a CI stage?
The workspace is the current working directory for all steps in a stage. Any data stored to the workspace is available to other steps in the stage. If you need to share additional volumes, decare them as Shared Paths. For more information, go to CI pipeline creation overview - Shared Paths and Share data across steps and stages.
How do I share files between CD/Custom stages and CI stages?
You can use caching to share data across stages; save the cache at the end of one stage, and restore the cache at the beginning of the next stage. You can also use a Git clone step to clone a repo where you have stored the files you want to share. Git clones steps are available in CI and Custom stages.
What volume is created when I add a shared path?
When you add a shared path, Harness creates an empty directory type volume and mounts it on each step container.
Does a shared path determine where a file is downloaded?
No, declaring a shared path doesn't dictate where a download happens. Your stage must include steps or commands that load files to volumes declared in your shared paths, otherwise the volumes remain empty. For example, depending on your pipeline configuration, cache steps might automatically interact with a shared path volume, or you might have a Git Clone step that clones a repo to a shared path volume.
Why are changes made to a container image filesystem in a CI step is not available in the subsequent step that uses the same container image?
Changes to a container image are isolated to the current step. While a subsequent step might use the same base container image, it is not the literal same container as the previous step. To permanently modify workspace data, you need to interact with the /harness directory (which is the base workspace directory for all steps in the stage), use shared paths, or use caching to share data between steps and stages.
Caching
What does caching do in Harness CI?
Caching improves build times and lets you share data across stages.
What caching options does Harness CI offer?
Harness CI offers a variety of caching options, including S3, GCS, and Harness-managed Cache Intelligence.
How can I download files from an S3 bucket in Harness CI?
There are two options to download files from an S3 bucket in Harness:
- Use the Save and Restore Cache from S3 steps. This step is specifically designed for downloading files from S3 and simplifies the process.
- Use a custom shell script in a Run step.
Can I use GCS for caching with Harness CI?
Yes. Go to Save and Restore Cache from GCS.
Does Harness CI support multilayer caching?
Yes. Go to Multilayer caching.
How can I use an artifact in a different stage from where it was created?
Use caching to share data across stages.
What does the Fail if Key Doesn't Exist setting do?
The Fail if Key Doesn't Exist setting causes the Restore Cache from GCS or Restore Cache from S3 step to fail if the defined cache key isn't found.
Does Harness override the cache when using the Save Cache to S3 step?
By default, the Save Cache to S3 step doesn't override the cache. You can use the Override Cache setting if you want to override the cache if a cache with a matching key already exists.
How can I check if the cache was restored?
You can use conditional executions and failure strategies to check if a cache was downloaded and, if it wasn't, install the dependencies that would be provided by the cache.
How do I handle a corrupted file when using the Restore Cache from S3 step?
If a file becomes corrupted in the bucket during the restoration process, the best practice is to remove the corrupted file from the bucket.
To ensure robustness in your pipeline, consider adding a Failure Strategy to the restore step to mitigate pipeline failures. For example, you can check if a cache was downloaded and, if it wasn't, install the dependencies that would be provided by the cache.
The Restore Cache from S3 step logs reference multiple S3 cache keys from different pipelines and pull a huge amount of cached data. Why is this happening?
This can happen when you create pipelines by cloning existing pipelines. For more information and resolution instructions, go to Caching in cloned pipelines
Can I cache files at the root of an S3 bucket?
Currently, you can't upload files to the root of an S3 bucket due to the glob pattern that Harness uses.
If there are too many nested directories in your cached files, you can use a Run step to flatten nested directories to cache before running the Save Cache or Upload Artifact step. users can have a run step to flatten the directory before uploading.
How can I share cache between different OS types (Linux/macOS)?
Cache sharing between Linux and macOS might not work because the home/workspace directories differ between operating systems. On macOS, /harness is a protected directory, and the workspace is located at /private/tmp/harness.
To ensure compatibility, use a relative path like ./FOLDER instead of an absolute path such as /harness/FOLDER. This resolves the issue and allows cache sharing between Linux and macOS.
Cache Intelligence
How do I enable Cache Intelligence?
Go to Cache Intelligence.
What is the Cache Intelligence cache storage limit?
When using Harness Cloud, cache storage limits apply based on your CI plan. For more details on storage limits, visit the CI subscription page.
What is the cache retention window for Cache Intelligence? Can the cache expire?
Cache storage is retained for 15 days. This limit resets whenever the cache is updated.
Can different pipelines within the same account access and use the same cache storage for Cache Intelligence?
All pipelines in the account use the same cache storage, and each build tool has a unique cache key that is used to restore the appropriate cache data at runtime.
What is the cache storage location for Cache Intelligence?
By default, Cache Intelligence stores data to be cached in the /harness directory. You can specify custom cache paths.
How does Harness generate cache keys for caching build artifacts?
Harness generates a cache key from a hash of the build lock file (such as pom.xml, build.gradle, or package.json) that Harness detects. If Harness detects multiple tools or multiple lock files, Harness combines the hashes to create the cache key. You can also set custom cache keys.
Is there any API available for Cache Intelligence?
Yes. Go to Cache Intelligence API.
Does the execution save the cache in Harness side when the cache intelligence option is configured in the build running in self hosted infra?
No, You need to configure the S3 compatible object store in your infra to be used as the cache storage. More details about the same can be referred in the doc
How can user prevent conflicts with Save Cache steps in parallel stages?
Skip the Save Cache step in all parallel stages except one. Use conditional execution in the Save Cache step to ensure it runs only in one instance of the parallel stages.
What conditional execution user add to the Save Cache step to handle parallel stages?
when:
stageStatus: Success
condition: <+strategy.iteration> == 0
This ensures the Save Cache step runs only if it's the first instance (iteration 0) of the parallel stages and if the current stage execution is successful.
How does caching work when cloning pipelines with Save/Restore Cache steps?
When the user clones a pipeline with caching steps, the cache keys generated by the cloned pipeline use the original pipeline's cache key as a prefix. For instance, if the original cache key is some-cache-key, the cloned pipeline might use some-cache-key2. This prevents accidental interference between cache keys of the original and cloned pipelines.
How can user ensure correct cache handling when cloning pipelines with Save Cache to GCS?
Enable separators (/) for GCS cache keys by setting PLUGIN_ENABLE_SEPARATOR: true in your pipeline's stage variables.
Why didn’t my cache restore in a subsequent pipeline run?
Cache restore depends on a hash key, and a mismatch in the hash key across runs will cause the cache to miss. Here’s what can cause differences in hash key calculation for cache intelligence:
-
Build File Changes: Any modification to files like pom.xml (for Maven) will change the hash.
-
Multiple Matching Files: If multiple pom.xml files are found, the one with the shortest path is selected.
-
File Access Issues: Permissions or file-read errors can disrupt hash calculation.
-
Project Structure Changes: Moving or renaming the build config file, or checking out the repo to a different location, can result in a new hash.
-
Different Commits: Even small code changes across builds can impact the hash key.
As a result, a cache may not be restored if the system determines it is outdated or invalid for the current build context.
Why am I seeing 404 errors for certain cache blobs?
A 404 response for cache blobs usually means the requested blob was not found in the cache store — often because it hasn’t been generated yet.
This does not necessarily indicate a problem with the cache store or your setup.
Background steps and service dependencies
What is the purpose of Background steps in a CI stage?
Background steps are used to manage dependent services that need to run for the entire lifetime of a Build stage.
How do I configure the Background step settings?
For instructions on configuring Background steps, go to Background step settings.
Can Background steps run multiple services simultaneously?
Yes, you can use multiple background steps to run multiple background services, creating a local, multi-service application.
Do Background steps have limitations?
Yes. Background steps have these limitations:
- Background steps don't support failure strategies or output variables.
- Steps running in containers can communicate with Background steps running on Harness Cloud build infrastructure by their Background step ID. For example, if a Background step has ID
myloginservice, later steps running in Docker can communicate with the Background step viamyloginservice:<port_number>. - If your build stage uses Harness Cloud build infrastructure and you are running a Docker image for your Background step, followed by steps that do not use Docker (steps that run directly on the host), you must specify Port Bindings in your Background step. Later steps that run on the host can communicate with the Background step via
localhost:<port_number>.
How can a step call a service started by a Background step?
For information about calling services started by Background steps, go to Name and ID and Port Bindings in Background step settings.
I can't connect to the hostname using the step ID from my Background step, and I get an "Unknown server host" error
Not all build infrastructures use the step ID when referencing services running in Background steps. For more information, go to Background step settings - Name and ID and Background step settings - Port Bindings.
How is the Background step's entrypoint retrieved during a build?
Harness connects to the container registry endpoint, based on the container registry specified in the step settings, to retrieve the entrypoint.
If you want to avoid this additional call to the container registry, you can configure the entry point directly in the Background step.
Why is Background step always marked as successful even if there are failures executing the entry point?
This is the expected behavior. Once a Background step initializes, Harness proceeds to the next step in the stage and marks the Background step successful. If your services in Background steps aren't starting, or your subsequent steps are running too soon, add a Run step after the Background step as a health check.
How can I make sure my background service is healthy before running the rest of my pipeline? How can I test that my background service is running?
Add a Run step after the Background step as a health check.
What are the prerequisites for running Background steps?
The build infrastructure or environment must have the necessary binaries to run your service. Depending on the build infrastructure, Background steps can use existing binaries in the environment (such as those that are preinstalled on Harness Cloud runners) or pull an image, such as a Docker image, containing the required binaries. For more information, go to Background step settings - Container Registry and Image.
Can Background steps use an external image for PostgreSQL services?
Yes. Depending on the build infrastructure, Background steps can either use existing binaries in the build environment or pull an image containing the required PostgreSQL binaries. For more information, go to Background step settings - Container Registry and Image.
How do I add volumes for PostgreSQL data in the build workspace?
With a Kubernetes cluster build infrastructure, use the Volumes setting to add one empty directory volume for each PostgreSQL service you plan to run. For moe information, go to Troubleshooting: Failed to get image entry point.
Can I run a LocalStack service in a Background step?
Yes. Go to Tutorial: Run LocalStack as a Background step.
Can I configure service dependencies in Gradle builds?
Yes. For details, go to the Knowledge Base article on Gradle build and daemon issues.
What happens if I don't provide the Fully Qualified Name (FQN) for an image in a private repo?
FQN is required for images in private repos.
Conditional executions, looping, parallelism, and failure strategies
Run a step only run if a certain file, like a .toml configuration file, changes in my repo
To run a step only when a certain file changes, you can define conditional executions based on a JEXL condition that evaluates to true for the specific file. For example, you might use a payload expression to get details from a Git event payload, such as a PR event that triggers a build.
Alternately, you could isolate the step in a stage by itself, configure a Git webhook trigger with a Changed File trigger condition that listens for changes to the target file, and then configure the trigger to run selective stage execution and run all stages that you want to run when that file changes, including the stage with your isolated step.
Can I use stage variables in my CI stage Parallism Strategy?
When using variables in your Parallelism Strategy, these variables must be resolved before the stage begins execution. Therefore, you can only use pipeline variables or stage variables from previously executed stages.
Can I assert an environment variable within a JEXL conditions?
While we support output variables that can point to an environment variable, we do not support the direct referencing of environment variables in JEXL conditions, even when using the feature flag CI_OUTPUT_VARIABLES_AS_ENV (which automatically makes environment variables available for other steps in the same build stage).
The conditions in JEXL only allow the use of variable expressions that can be resolved before the stage is executed. Since environment variables are resolved during runtime, it is not possible to utilize variable expressions that cannot be resolved until the stage is run.
What does a failure strategy consist of?
Failure strategies include error conditions that trigger the failure and actions to take when the specified failure occurs.
Can I make a step, stage, or pipeline fail based on the percentage of test cases that fail or succeed?
Currently, Harness can't fail a step/stage/pipeline based on a percentage of test results. To achieve this, you would need to manually parse the test results (which are created after the test step execution) and export some variables containing the percentages you want to track. You could then have a step throw an error code based on the variable values to trigger a failure strategy, or you could manually review the outputs and manually mark the stage as failed.
Due to potential subjectivity of test results, it would probably be better to handle this case with an Approval stage or step where the approver reviews the test results.
Can I abort a pipeline if the referenced branch is deleted?
This is not natively supported; however you could create a Git webhook trigger that listens for a specific delete event with auto-abort previous execution. This trigger would only go off on the specified delete event and, therefore, it would only cancel the ongoing executions if the delete event occurred.
Is there a way to abort a running pipeline from a step in that pipeline?
You can use the putHandleInterrupt API to abort a running pipeline from a step in the pipeline.
Can I add notifications, such as failure notifications, to stage templates?
While notifications are a pipeline-level setting that is not explicitly available at the stage level, you can use Plugin steps to add notifications in your stage templates. Configure the Plugin step to use a use a Drone plugin or a custom plugin to send an email notification, Slack notification, or otherwise.
Can I use a GitHub PR label as a condition for a trigger or conditional execution?
Yes. You can use the following expression in a JEXL condition or trigger configuration.
<+eventPayload.pull_request.labels[0].LABEL_KEY>
Replace LABEL_KEY with your label's actual key.
Why does the parallel execution of build and push steps fail when using Buildx on Kubernetes?
When using Buildx on Kubernetes, either enabled by feature flags or in the build and push steps when the Docker Layer Caching option is checked, running multiple build-and-push steps in parallel may result in failures due to race conditions. This issue arises from how Docker-in-Docker works within Kubernetes pods.
The failure occurs when either of the following feature flags are enabled:
CI_USE_BUILDX_ON_K8– Enables the use of Buildx instead of Kaniko for build-and-push steps.CI_ENABLE_DLC_SELF_HOSTED– Enables DLC (Docker Layer Caching), which also forces the use of Buildx instead of Kaniko.
When these flags are active, and parallel build-and-push steps are attempted, they often fail due to Kubernetes’ shared network space. Since all containers in the same Kubernetes pod share the same network, running multiple Docker daemons simultaneously (via Docker-in-Docker) leads to network race conditions, preventing multiple Docker builds from completing in parallel.
Common failure causes:
- Privileged mode settings: Buildx requires privileged access, which is not always enabled in self-hosted infrastructures.
- Race conditions: Multiple Docker daemons may attempt to modify network rules (e.g., iptables) at the same time, causing conflicts.
There is an open issue with Drone regarding parallel builds:
Drone Issue: Docker Parallel Build Failing
To avoid this, run build-and-push steps sequentially in Kubernetes pipelines instead of in parallel. Additionally, there is an open PR to address iptables settings in the Drone Docker plugin, which could help mitigate these issues in the future:
Drone Docker Plugin PR
Logs and execution history
How do I access build logs?
For information about viewing build and build logs, go to:
Does Harness limit log line length?
Yes, there is a single-line limit of 25KB. If an individual line exceeds this limit, it is truncated and ends with (log line truncated). If you need to extract long log lines, you can export full logs.
Truncated execution logs
Each CI step supports a maximum log size of 5MB. Harness truncates logs larger than 5MB. If necessary, you can export full logs.
Furthermore, there is a single-line limit of 25KB. If an individual line exceeds this limit, it is truncated and ends with (log line truncated).
Note that the CI log limit is different from the Harness CD log limit.
Export full logs
If your log files are larger than 5MB, you can export execution logs to an external cache and examine the full logs there.
- Add a step to your pipeline that records each step's complete logs into one or more files.
- If you have a lot of log files or your logs are large, add a step to compress the log files into an archive.
- Use an Upload Artifact step to upload the log files to cloud storage.
- Repeat the above process for each stage in your pipeline for which you want to export the full logs.
- Examine the log files in your cloud storage. If you used the S3 Upload and Publish or Artifact Metadata Publisher plugins, you can find direct links to your uploaded files on the Artifacts tab on the Build detail page.
You can also use a service, such as env0, to forward logs to platforms suited for ingesting large logs.
Step logs disappear
If step logs disappear from pipelines that are using a Kubernetes cluster build infrastructure, you must either allow outbound communication with storage.googleapis.com or contact Harness Support to enable the CI_INDIRECT_LOG_UPLOAD feature flag.
You must restart your delegate after you enable the CI_INDIRECT_LOG_UPLOAD feature flag.
For more information about configuring connectivity, go to:
Step logs don't load in real time
Go to CI step logs don't load in real time.
Step succeeds even when explicitly executing exit 1 in a Bash script that runs in script's background
Harness determines the execution status for a step based on the exit status received from the primary script execution.
When you call a function in the background of a script, it doesn't directly impact the exit status of the main script. Therefore, if you manually call exit 1 within a background function, it won't cause the step to fail if the primary script succeeds.
This behavior is consistent with how scripts operate both inside and outside of Harness.
Build step fails due to ResourceExhausted
Build and Push steps can return a ResourceExhausted error, such as:
exit status 1 rpc error: code = ResourceExhausted desc = grpc: received message larger than max (4950319 vs. 4194304)
This can be related to log streaming during the Build and Push step or a Run step executing a build script. It indicates that the logs are too large for the log streaming service to handle.
If your build uses tee commands to print logs to the console, consider removing these commands or output these logs to a file that you can then upload as an artifact or send by email.
If your builds time out with this error during stage initialization, and you're using a Kubernetes cluster build infrastructure, you can contact Harness Support to enable a beta feature that shortens long environment variables, such as commit messages and PR titles.
Can I get logs for a service running on Harness Cloud when a specific Run step is executing?
Yes. To do this, you can add a step that runs in parallel to the Run step, and have that parallel step get the service's logs while the build runs. For an example, go to Use a parallel step to monitor failures.
How to get the build ID of a pipeline execution?
You can use the expression <+execution.steps.stepId.build.buildNumber> in a Run step to echo the build ID for that execution.
Builds older than 30 days aren't on the Project Overview page.
The default timescale setting for the overview page is 30 days. You can change this setting.
A previous execution is missing from my Builds dashboard.
First, check the timescale setting on the dashboard. The default is 30 days, which hides builds older than 30 days.
Then, make sure you are in the correct project and that you have permission to view that particular pipeline.
Finally, if your build is older than six months, it is outside the data retention window. For more information, go to data retention.
Can I compare pipeline changes between builds?
Yes. Go to view and compare pipeline executions.
How do I create a dashboard to identify builds that end with a timeout in a specific task?
You can create a custom dimension for this, such as:
contains(${pipeline_execution_summary_ci.error_message}, "Timeout")
Debug mode
Why does the debug mode SSH session close after some time?
Sessions automatically terminate after one hour or at the step timeout limit, whichever occurs first.
Why can't I launch a remote debug session? Can I debug a pipeline that doesn't have an obvious failure?
There are several debug mode requirements, namely that the pipeline must have a failed step in order to generate the debug session details. If your build doesn't have any failed steps, you won't be able to access a remote debug session. However, you can force a build to fail if you need to troubleshoot pipelines that appear to build successfully but still need remote troubleshooting. To do this, add a Run step with the command exit 1. This forces the build to fail so you can re-run it in debug mode.
Re-run in debug mode isn't available for a new pipeline
Debug mode is not available for a pipeline's first build. Run the pipeline again and, if it meets the debug mode requirements, you should be able to trigger re-run in debug mode.
AIDA for CI
For information about using AIDA to troubleshoot your Harness CI builds, go to Troubleshoot builds with AIDA.
CI with CD
Why did the CI stage still go through despite setting a freeze window?
Freeze windows only apply to CD stages.
Can I use the expression <+codebase.commitSha> in a CD stage to get the commit ID?
Yes, you can use <+codebase.commitSha> to get the commit ID if the CD stage is after the Build (CI) stage in your pipeline.
This expression doesn't work if there is no CI stage in your pipeline, or if the CD stage runs before the CI stage.
Additionally, including a clone step in your CD stage won't populate the <+codebase.commitSha> expression. This expression is dependent on the CI stage's built-in clone codebase step.
Can I reference a secret type output variable exported from a CD or custom stage in CI stage?
No. Currently CI stages don't support secret type output variables from CD or custom stages.
Can I trigger a Build stage with an artifact trigger?
While it is possible to trigger deployments with artifact triggers, there are currently no CI-specific triggers for artifacts.
Can I use Queue steps in Build stages?
No. Queue steps are only available for Custom stages.
Performance and build time
What are the best practices to improve build time?
There are many optimization strategies for making your pipelines faster and more efficient.
How do I reduce the time spent downloading dependencies for CI builds?
You can create pre-built Docker images that have all required dependencies, and then periodically update these images with the latest dependencies. This approach minimizes dependency download time during the build process by packaging your dependencies into one image. Harness offers pre-build public images that contain common and useful tools for CI pipelines.
What are the benefits of excluding unnecessary files and packages from Docker images?
Excluding unnecessary files and packages reduces build times and creates in smaller, more efficient, and more portable Docker images.
How can Harness input sets help automate a CI pipeline?
Input sets are collections of runtime inputs for a pipeline executions. With input sets, you can use the same pipeline for multiple scenarios. You can define each scenario in an input set or overlay, and then select the appropriate scenario when you execute the pipeline.
Harness Platform rate limits
For stability, Harness applies limits to prevent excessive API usage. Harness reserves the right to change these limits at any time. For more information, go to Platform rate limits.
Running concurrent builds shows "queued license limit reached"
Queued license limit reached means that your account has reached the maximum build concurrency limit. The concurrency limit is the number of builds that can run at the same time. Any builds triggered after hitting the concurrency limit either fail or are queued.
If you frequently run many concurrent builds, consider enabling Queue Intelligence for Harness CI, which queues additional builds rather than failing them.
Can I use Harness Queue Intelligence with Kubernetes cluster build infra?
Queue intelligence is currently supported for Harness Cloud only.
What is the timeout limit for a CI pipeline?
By default, a stage can run for a maximum of 24 hours on a Kubernetes cluster build infrastructure and a maximum of 30 minutes on Harness Cloud build infrastructure.
For pipelines, the default timeout limit is, generally, the product of the stage limit multiplied by the number of stages. For example, a pipeline with three stages that use a Kubernetes cluster build infrastructure could run for a maximum of 72 hours. However, you can also set an overall pipeline timeout limit in each pipeline's Advanced Options.
For steps, you can set a custom timeout limit in each step's Optional Configuration settings. In stages that use a Kubernetes cluster build infrastructure, the default timeout for steps is 10 hours. However, this is constrained by the stage timeout limit of 24 hours. For example, if a stage has three steps, the total run time for the three steps can't exceed 24 hours or the stage fails due to the stage timeout limit.
Can I add an Approval step to a CI stage?
Currently, Approval steps aren't compatible with CI stages.
General issues with connectors, secrets, delegates, and other Platform components
For troubleshooting and FAQs for Platform components that aren't specific to CI, such as RBAC, secrets, secrets managers, connectors, delegates, and otherwise, go to the Harness Platform Knowledge Base or Troubleshooting Harness.
Can I use Harness CI for mobile app development?
Yes. Harness CI offers many options for mobile app development.
Can I use Terraform to create CI pipelines?
Yes, you can use the Harness Terraform provider.
When using the --no-push option in a Harness build step, where is the locally built image stored?
Harness doesn't store the built image directly with --no-push in Kaniko builds; Kaniko stores layers locally (e.g., /kaniko) and requires exporting as an image or tarball for using in subsequent steps. For more information, go to the --tar-pathflag description in the Kaniko readme.
In a CI/CD pipeline using Drone CI and the drone-aws-sam plugin, how can you pass multiple arguments to the AWS SAM build command?
When using the drone-aws-sam plugin in a Drone CI pipeline, you can pass multiple arguments to the AWS SAM build command by specifying them in the build_command_options field of the plugin configuration. The arguments should be separated by spaces and enclosed in double quotes if they contain spaces or special characters. Here's an example:
build_command_options: "--no-cached --debug --parameter-overrides 'ParameterKey=KeyPairName, ParameterValue=MyKey ParameterKey=InstanceType, ParameterValue=t1.micro'
A background service consistently generates logs containing "SIGQUIT: quit PC=0x46d441 m=0 sigcode=0..." messages during a specific stage execution. These messages appear only in logs scraped from the container and streamed to an external monitoring tool, not directly in the CI/CD platform logs. What might be causing this, and how can I troubleshoot it?
Harness runs the service defined in the background step in a separate go-routine, which will be available until the lifetime of the stage. The service gets automatically killed during cleanup after the execution of the stage.
The container logs you're seeing mean that the go-routine has received the termination signal, most likely during pod clean-up. It does look like the logs are quite verbose, which could indicate that debug mode is enabled for this particular step.
Is there a public API in CI to obtain the day-by-day usage breakdown of Mac VMs for the account?
As of now, there is no public API available to retrieve such information.
Is there a known issue or limitation with Kaniko that prevents the chmod command within ADD in a Dockerfile from working properly when building with native build and push steps?
This seems like a known issue with Kaniko. https://github.com/GoogleContainerTools/kaniko/issues/2850
How can I rotate my Drone user token?
To rotate a user token, you can use the following curl command:
curl -X POST -i -H "Authorization: Bearer AUTH_TOKEN" https://<DRONE_SERVER_FQDN>/api/user/token\?rotate\=true
What actions can I take to address the extended runtime of a Docker command, particularly when encountering timeouts during microdnf updates?
The prolonged runtime of Docker commands, often exacerbated by timeouts during microdnf updates, can be primarily attributed to network issues. To address this, you should verify the connectivity of the repomirror being utilized. Additionally, you could examine and potentially adjust the timeouts configured on the repomirror to enhance performance. These steps can help mitigate the impact of network-related delays and improve the efficiency of Docker operations.
What does the error "java. lang.IllegalStateException: Failed to execute ApplicationRunner" mean?
The error java.lang.IllegalStateException: Failed to execute ApplicationRunner indicates that there was an issue while trying to execute an ApplicationRunner in a Java application. This could be due to various reasons such as missing dependencies, incorrect configuration, or runtime issues. Examining the stack trace and reviewing the application code further may be necessary to pinpoint the exact cause of the error.
How can I a run background step in debug mode in Harness?
To enable debug logging, set the environment variable to DEBUG=true. For more configuration information, go to Relay proxy configuration reference.
Kaniko error "error building image: deleting file system after stage 0: unlinkat /opt/nodejs: directory not empty"
The error
Deleting filesystem...
error building image: deleting file system after stage 0: unlinkat /opt/nodejs: directory not empty
is an issue that can occur when building images with Kaniko. This is tied back to a Kaniko issue, https://github.com/GoogleContainerTools/kaniko/issues/2164
Kaniko executes in user space and creates and destroys the file system repeatedly. In this case, if the files in location /opt/nodejs is being used by some other process, it will not be able to delete it.
In those cases, setting ignore-path in Kaniko overrides this behaviour: https://github.com/GoogleContainerTools/kaniko/blob/main/pkg/util/fs_util.go#L233
To do this within Harness, the following will need to be set as a variable so that ignore-path shows up in the Kaniko CLI Arguements. The environment variable will need to be set with PLUGIN_IGNORE_PATH and the path, in this case, /opt/nodejs.
variables:
- name: PLUGIN_IGNORE_PATH
type: String
description: ""
required: false
value: /opt/nodejs
If it is operating as expected, the Kaniko CLI will show the following in the CLI, and will continue to execute the code properly.
/kaniko/executor --dockerfile=Dockerfile --context=dir://. --destination=destination/repo:1.0 --snapshotMode=redo --digest-file=/kaniko/digest-file --ignore-path=/opt/nodejs
Matrix Executions and Strategy FAQs
Why am I seeing the error "should map to single port" when using JSON-based matrix executions?
When using JSON input to define matrix combinations, you may encounter the following error during CI pipeline execution: should map to single port.
This typically occurs when the matrix input is dynamically constructed from a JSON object — and the ordering of keys in the matrix input is not preserved during evaluation. This can lead to internal mismatches between matrix labels and execution steps.
Root Cause
The issue arises from non-deterministic key ordering in matrix inputs derived from JSON strings. Engines like Jackson or the default Java Map do not guarantee key order, which causes:
-
Inconsistent step identifiers between Initialize and Run steps
-
Internal parsing errors
-
Label mismatch during Kubernetes pod creation
Workarounds
Option 1: Disable Matrix Labels By Name
- Go to Pipeline Settings
- Uncheck the “Enable Matrix Labels By Name” option
Disabling this option prevents Harness from generating Kubernetes labels based on matrix key values, avoiding the problem entirely.
Option 2: Explicitly Define nodeName You can override the auto-generated node name by providing a stable, predictable naming pattern in your matrix config:
strategy:
matrix:
service: [svc1, svc2, svc3]
env: [env1, env2]
nodeName: stage_<+matrix.service>_<+matrix.env>
This bypasses the default label generator logic that may be affected by unordered JSON keys.