HCE constituents
This topic describes the Harness Chaos Engineering (HCE) constituents.
Below is a diagram that shows the component relationships in HCE.
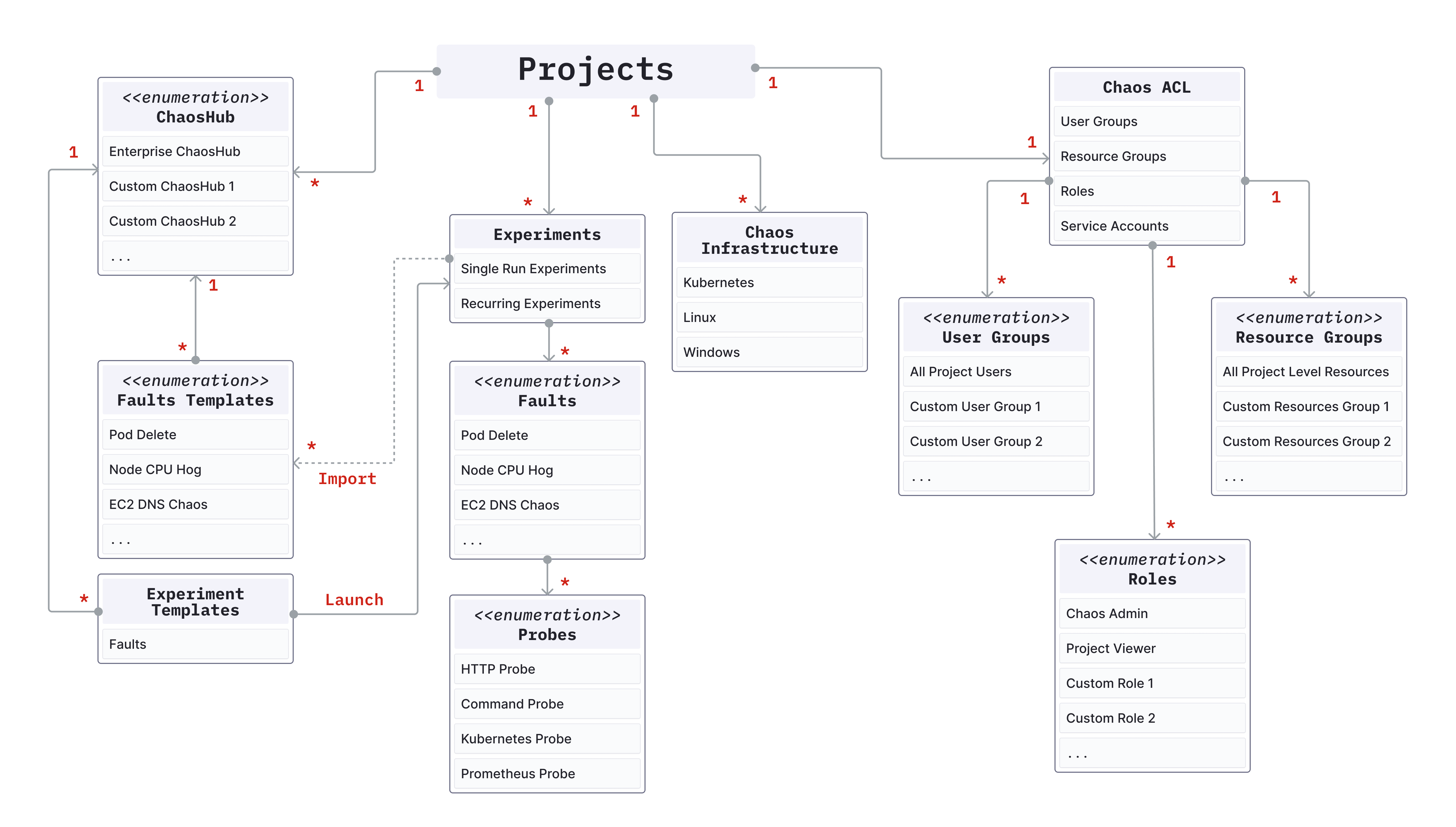
Constituent definition
1. Chaos experiment
A chaos experiment (or an experiment) injects one or more chaos faults into a specified chaos infrastructure and summarizes the result of the chaos execution. You can define the experiment using the Chaos Studio through the guided UI or by uploading the workflow CR (custom resource) manifest.
2. Chaos fault
A chaos fault (or a fault) refers to the failures injected into the chaos infrastructure as part of a chaos experiment. Every fault is scoped to a particular target resource, and you can customize the fault using the fault tunables, which you can define as part of the Chaos Experiment CR and Chaos Engine CR. Optionally, you can define one or more probes as part of a chaos fault.
3. ChaosHub
ChaosHub is a collection of experiment templates (defined as workflow CRs) and faults (defined as ChaosExperiment CR and ChaosEngine CR) that help create and execute new chaos experiments against your target resources. Apart from the Enterprise ChaosHub, which is present by default, you can add custom ChaosHub to manage and distribute custom experiment templates and faults.
-
Enterprise ChaosHub
Also known as Enterprise hub, it comes out-of-the-box with HCE and consists of pre-built manifests (YAML files) and chaos experiment templates. It is a prebuilt ChaosHub that represents the existing experiments and chaos faults. You can use faults from multiple categories to create chaos experiments in the Enterprise ChaosHub.
4. Chaos infrastructure
Chaos infrastructure represents the individual components of a deployment environment. It is a service that runs within your target environment to help HCE access the target resources and inject chaos at a cloud-native scale.
5. Environment
A Harness environment represents your deployment environment such as Dev, QA, Staging, Production, etc. Each environment may contain multiple chaos infrastructures. It helps isolate the various environments that the engineering, product owners, QA, and automation teams use under a single Harness project. This allows for better segregation of mission-critical infrastructures with several attached dependencies from dev and staging infrastructures for their safety.
6. Chaos Studio
Chaos Studio is used to create new chaos experiments using various chaos faults and templates from ChaosHub, probes, and custom action steps. You can create new experiments using the guided UI or by using the experiment manifest represented by the workflow CR.
7. Resilience score
The resilience score is a quantitative measure of how resilient the target application is to a chaos experiment. You can calculate this value based on the priority set for every fault in the experiment and the probe success percentage of the faults (if the probes are defined).
8. Probe
Probes (or resilience probes) automate the chaos hypothesis validation performed during a fault execution. They are declarative checks that determine the outcome of a fault. Probes are scoped to the faults, and you can define as many probes as required as part of each fault.
9. Tunables
You can customize a fault execution by changing the tunables (or parameters) it accepts. While some of the tunables are common across all the faults (for example, chaos duration), every fault has its own set of tunables: default and mandatory ones. You can update the default tunables when required and always provide values for mandatory tunables (as the name suggests).
10. Chaos interval
Chaos interval is a tunable that specifies the duration between successive iterations of chaos whereas the elapsed experiment time is less than the chaos duration.
11. Sequence
Sequence defines how you inject chaos into the target instances of a fault. You can configure it in serial mode (to inject chaos in one target in a single chaos iteration) or in parallel mode (to inject chaos in all targets in a single chaos iteration).
12. Chaos duration
Chaos duration is the total duration through which chaos execution takes place. This excludes the duration of pre-chaos injection and post-chaos injection execution time.
13. Probe success percentage
Probe success percentage is the percentage of probes that have been successfully evaluated out of the total number of probes.
14. Experiment templates
Experiment templates are stored as part of the ChaosHub, which you can use to create new chaos experiments. You can edit the templates by making changes to the existing fault configuration or by adding new faults. You can store new experiments in ChaosHub as templates.
15. Result fail step
When an experiment fails, the failed step specifies the exact cause of failure for the experiment run. It contains an error code for the classification of the error, a phase to specify the execution phase during which the error occurred, and finally, the reason which is a user-friendly description of the error.
16. Result phase
Phase determines the status of the overall experiment execution. It may be Awaited, Running, Completed, or Aborted, depending on the experiment outcome.
17. Chaos engine Custom Resource (CR)
The Chaos Engine CR is the user-facing chaos Kubernetes CR which connects a target resource instance with a chaos fault to orchestrate the steps of chaos execution. You can specify run-level details such as overriding fault defaults, providing new environment variables and volumes, deleting or retaining experiment pods, defining probes, and updating the status of the fault execution.
18. Chaos experiment Custom Resource (CR)
Chaos Experiment CR contains the low-level execution information for the execution of a chaos fault. The CR holds granular details of a fault such as the container image, library, necessary permissions, and chaos parameters. Most of the chaos experiment CR parameters are tunables that you can override from the chaos engine CR.
19. Workflow Custom Resource (CR)
A workflow CR is used to define the number of operations that are coupled together in a specific sequence to achieve a desired chaos impact. These operations are chaos faults or any custom action associated with the experiment, such as load generation.
20. Chaos manager
Chaos manager is a GraphQL-based Golang microservice that serves the requests received from the chaos infrastructure either by querying MongoDB for relevant information.
A NoSQL MongoDB database microservice accountable for storing users' information, past chaos experiments, saved chaos experiment templates, user projects, ChaosHubs, and GitOps details, among other information.
21. Chaos exporter
Chaos Exporter is an optional constituent that exposes monitoring metrics such as QPS and others present on the cluster to the frontend. It facilitates external observability in HCE. You can achieve this by exporting the chaos metrics generated (during the chaos injection as time-series data) to the Prometheus database for processing and analysis.
22. Chaos rollback
Chaos rollback causes all the target resources in an experiment to re-attain their steady state after the execution of the experiment, which ensures the safety of all the applications deployed on your Linux machine.
- Chaos rollback is performed at the end of each experiment execution. On-the-fly experiments can be safely aborted and the chaos is reverted.
- In case of a network disruption between the control plane and execution plane during the execution of an experiment, it is gracefully aborted and the chaos is reverted.
- In case of an abrupt exit of the chaos infrastructure process during the execution of an experiment, the daemon service reverts the chaos before restarting the process.
- In case of an abrupt reboot of the machine, after the reboot, the daemon service checks and reverts any remnant inconsistency due to the prior execution of chaos, before starting the chaos infrastructure process.
- In the rare scenario where the revert of chaos itself also leads to an error, an appropriate error message is logged in the experiment log for the manual intervention of the user.
Components common to all chaos infrastructure
Some of the components common to all chaos infrastructures include:
-
Workflow controller: Helps execute chaos experiments by:
- Searching for the experiment on the cluster.
- Identifying the experiment.
- Triggering the experiment.
-
Subscriber: Serves as a bridge between the execution plane and control plane. It also performs other tasks required to orchestrate the chaos experiment executions, such as:
- Installing a new chaos experiment on the cluster.
- Sending the experiment metadata (after completing the execution) to the control plane.
- Performing health checks on all the components in the chaos execution plane.
- Creating a chaos experiment CR from a chaos experiment template.
- Monitoring the events associated with the chaos experiment during its execution.
Kubernetes execution plane
The Kubernetes execution plane consists of chaos infrastructure components like workflow controllers, and subscribers that are described earlier, and backend execution infrastructure components like ChaosExperiment CR, ChaosEngine CR, etc.
Chaos operator
Leverages the Kubernetes operator pattern to interpret the fault configuration, execute the individual faults in an experiment, execute the fault and its probes (if they have been defined), and populate the result after the execution.
Chaos exporter
Optional component that facilitates external observability in HCE. This is achieved by exporting the chaos metrics generated during the chaos injection as time-series data to the Prometheus database for processing and analysis.
Linux execution plane
The Linux execution plane consists of only the Linux chaos infrastructure daemon service.
Linux chaos infrastructure daemon service is a Systemd service responsible for injecting faults into a Linux machine as a part of a chaos experiment.
- The infrastructure relies on a polling model to fetch and execute the experiments or tasks from the control plane.
- It uses a rotating access token based authorization along with TLS encryption to ensure secure communication with the control plane.
- Multiple faults in an experiment can execute serially or in parallel to each other, depending on how the faults have been defined.
- Every machine has a one-to-one mapping with the infrastructure daemon service, and all of these infrastructure(s) communicate with the control plane to:
- Fetch experiments for execution
- Update experiment execution status
- Stream experiment logs
- Send experiment execution result
Compatibility with Linux distribution
The chaos infrastructure has been tested for compatibility in the following Linux OS distributions:
- Ubuntu 16+
- Debian 10+
- CentOS 7+
- RHEL 7+
- Fedora 30+
- openSUSE LEAP 15.4+ / SUSE Linux Enterprise 15+