Events summary
The Continuous Error Tracking Events dashboard displays a comprehensive list of all the monitored services and events.
To go to the Events dashboard, in Harness, go to Continuous Error Tracking, and then select Events Summary.
![]()
By default, the dashboard displays the data for the last 24 hours time period. You can customize the dashboard using the following filters:
- Time period: Choose a period for which you want to see the data. The default option is Last 1 hour.
- Services: Choose a service to see its data. You can select multiple services. The default option is All.
- Environment: Choose an environment to see its data. You can select multiple environments. The default option is All.
- Deployment version: Choose a deployment version in order to view the data associated with the monitored services of that specific version. You can select multiple deployment versions. The default option is All.
Based on the filter settings, the dashboard displays the total number of services being monitored by Continuous Error Tracking and the number of services that have generated new events. An event is considered as new if it is observed for the first time in a monitored service.
View Events list
The Events list screen displays a summary of the total events, exceptions, log events, HTTP errors, and custom errors. It also displays a list of all the events. Each row provides deep contextual information about the event type, its location in the code, and impact in terms of volume and spread across the service.
You can filter the Events list by time period, services, environments, deployment version, and status.
To view the Events list, do the following:
- On the Events dashboard, select a monitored service. The list of events captured by that monitored service is displayed.
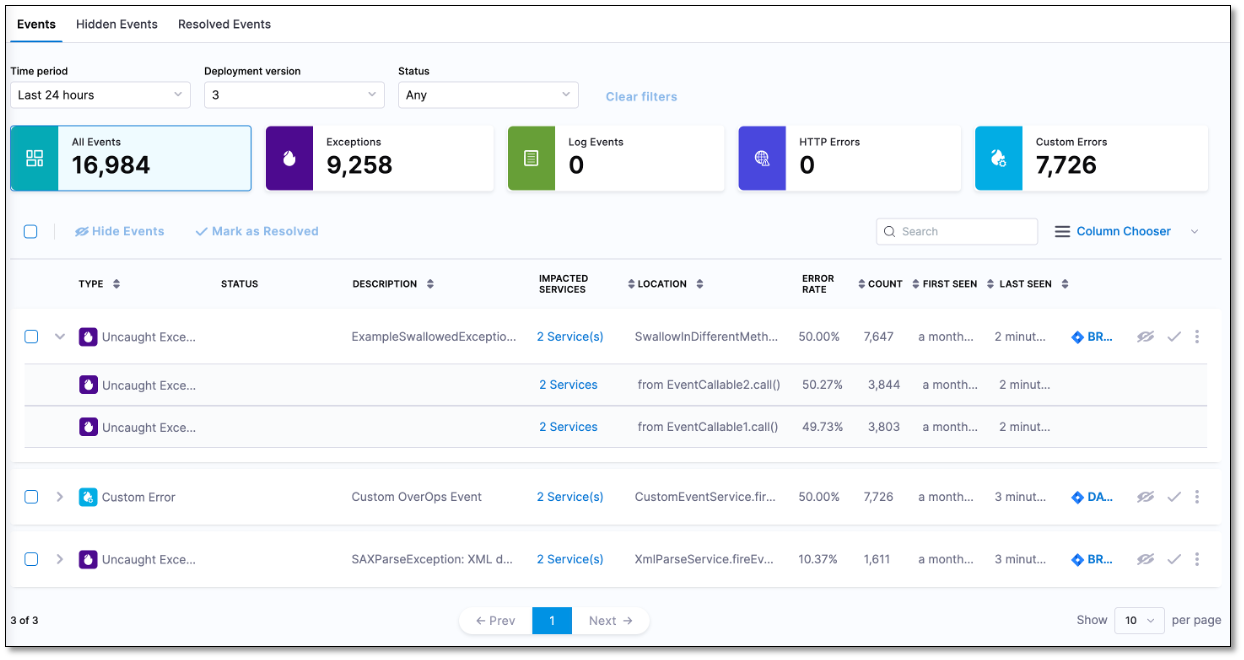
The Events list displays the following information:
-
Type: Displays the event type. The event type can be one of the following:
- Caught Exception - Exceptions captured and handled by the user’s service.
- Uncaught Exception - Exceptions that were not captured by the user’s service.
- Swallowed Exception - Exceptions that were captured but ignored by the user’s service.
- Log Error - Events logged as errors in the user’s service.
- Log Warning - Events logged as warnings in the user’s service.
- HTTP Error - HTTP communication errors.
- Custom Error - Events that occur in the custom SDK.
-
Description: Name of the event. In case of an exception, this is the exception class name. For example, AmazonException, NullPointerException, and so on. You can see the complete exception message of an event by hovering over the Description field.
-
Location: Service class and method in which the event occurred. You can also view the actual line of code in which the error occurred even if the error was caused by a third party or core JDK framework. This can help you quickly identify the root cause of the error. Event location can also be filtered according to packages.
-
Count: Number of times the event has occurred in the selected time period. This value indicates the severity of the event.
-
Error Rate: Percentage of time the event occurs in comparison to all the calls made to the event's location. This is calculated by dividing the number of occurrences by the total number of calls to that location.
-
First Seen: Time when the event was first detected in the environment.
-
Last Seen: Last time this event was detected in the environment. This value indicates whether the event is still impacting your application.
-
Impacted Services: List of monitored services in which the event was detected. For example, Producer-Service, Consumer-Service, Web-frontend, and so on.
Event Distribution Graph
A key element in the dashboard is the interactive graph. It displays a visual representation of the event volume present in the current timeframe and view.
The Event Distribution Graph is a crucial component of the dashboard. It provides an interactive visual representation of event volume within the selected timeframe and view. It is a powerful tool for analyzing historical performance metrics and tracking error counts within your specified time interval.
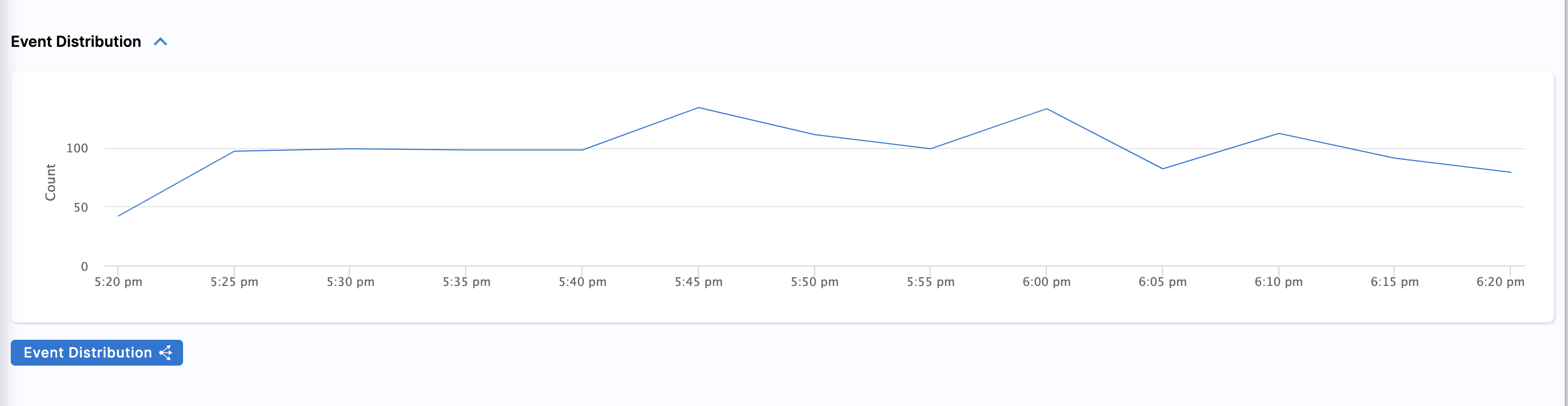
To learn more, go to Event Distribution Graph
Next steps
- Get to the root cause of events in production and lower environments using Automated Root Cause (ARC).