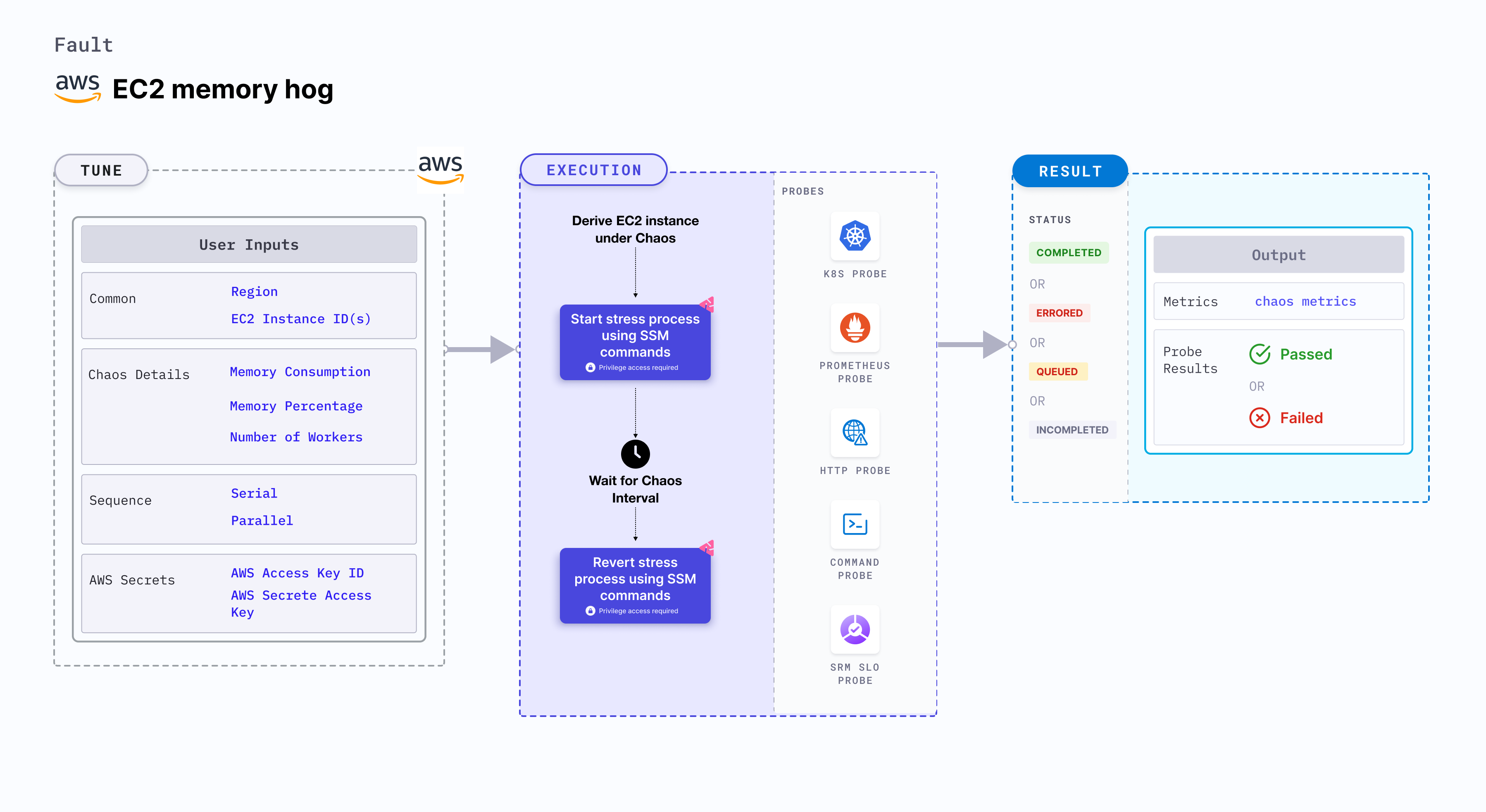
EC2 memory hog
EC2 memory hog disrupts the state of infrastructure resources. This fault:
- Induces stress on AWS EC2 instance using Amazon SSM Run command. The SSM Run command is executed using SSM documentation that is built into the fault.
- Causes memory exhaustion on the EC2 instance for a specific duration.
Use cases
EC2 memory hog:
- Causes memory stress on the target AWS EC2 instance(s).
- Simulates the situation of memory leaks in the deployment of microservices.
- Simulates application slowness due to memory starvation, and noisy neighbour problems due to hogging.
Prerequisites
- Kubernetes >= 1.17
- The EC2 instance should be in a healthy state.
- SSM agent should be installed and running on the target EC2 instance.
- The Kubernetes secret should have the AWS Access Key ID and Secret Access Key credentials in the
CHAOS_NAMESPACE. Below is a sample secret file:apiVersion: v1
kind: Secret
metadata:
name: cloud-secret
type: Opaque
stringData:
cloud_config.yml: |-
# Add the cloud AWS credentials respectively
[default]
aws_access_key_id = XXXXXXXXXXXXXXXXXXX
aws_secret_access_key = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
HCE recommends that you use the same secret name, that is, cloud-secret. Otherwise, you will need to update the AWS_SHARED_CREDENTIALS_FILE environment variable in the fault template with the new secret name and you won't be able to use the default health check probes.
Below is an example AWS policy to execute the fault.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ssm:GetDocument",
"ssm:DescribeDocument",
"ssm:GetParameter",
"ssm:GetParameters",
"ssm:SendCommand",
"ssm:CancelCommand",
"ssm:CreateDocument",
"ssm:DeleteDocument",
"ssm:GetCommandInvocation",
"ssm:UpdateInstanceInformation",
"ssm:DescribeInstanceInformation"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"ec2messages:AcknowledgeMessage",
"ec2messages:DeleteMessage",
"ec2messages:FailMessage",
"ec2messages:GetEndpoint",
"ec2messages:GetMessages",
"ec2messages:SendReply"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"ec2:DescribeInstanceStatus",
"ec2:DescribeInstances"
],
"Resource": [
"*"
]
}
]
}
- Go to AWS named profile for chaos to use a different profile for AWS faults, and the superset permission/policy to execute all AWS faults.
Mandatory tunables
| Tunable | Description | Notes |
|---|---|---|
| EC2_INSTANCE_ID | ID of the target EC2 instance. | For example, i-044d3cb4b03b8af1f. For more information, go to EC2 instance ID. |
| REGION | AWS region ID where the EC2 instance has been created. | For example, us-east-1. |
Optional tunables
| Tunable | Description | Notes |
|---|---|---|
| TOTAL_CHAOS_DURATION | Duration to insert chaos (in seconds). | Default: 30 s. For more information, go to duration of the chaos. |
| MACHINE | Whether chaos is applied on a Windows VM or a Linux VM. | |
| CHAOS_INTERVAL | Time interval between two successive instance terminations (in seconds). | Default: 60 s. For more information, go to chaos interval. |
| AWS_SHARED_CREDENTIALS_FILE | Path to the AWS secret credentials. | Defaults to /tmp/cloud_config.yml. |
| INSTALL_DEPENDENCIES | Install dependencies to run network chaos. It can be 'True' or 'False'. | If the dependency already exists, you can turn it off. Defaults to True. |
| MEMORY_CONSUMPTION | Amount of memory to be consumed by the EC2 instance (in megabytes). | Default: 500 MB. For more information, go to memory consumption in megabytes. |
| MEMORY_PERCENTAGE | Amount of memory to be consumed by the EC2 instance (in percentage). | Default: 0. For more information, go to memory consumption in percentage. |
| NUMBER_OF_WORKERS | Number of workers used to run the stress process. | Default: 1. For more information, go to workers. |
| SEQUENCE | Sequence of chaos execution for multiple instances. | Defaults to parallel. Supports serial and parallel. For more information, go to sequence of chaos execution. |
| RAMP_TIME | Period to wait before and after injecting chaos (in seconds). | For example, 30s. For more information, go to ramp time. |
Memory consumption in megabytes
It specifies the amount of memory to be utilized (in megabytes) on the EC2 instance. Tune it by using the MEMORY_CONSUMPTION environment variable.
The following YAML snippet illustrates the use of this environment variable:
# memory in mb to utilize
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
chaosServiceAccount: litmus-admin
experiments:
- name: ec2-memory-hog
spec:
components:
env:
- name: MEMORY_CONSUMPTION
VALUE: '1024'
# ID of the EC2 instance
- name: EC2_INSTANCE_ID
value: 'instance-1'
# region for the EC2 instance
- name: REGION
value: 'us-east-1'
Memory consumption by percentage
It specifies the amount of memory (in percentage) to be utilized on the EC2 instance. Tune it by using the MEMORY_PERCENTAGE environment variable.
The following YAML snippet illustrates the use of this environment variable:
# memory percentage to utilize
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
chaosServiceAccount: litmus-admin
experiments:
- name: ec2-memory-hog
spec:
components:
env:
- name: MEMORY_PERCENTAGE
value: '50'
# ID of the EC2 instance
- name: EC2_INSTANCE_ID
value: 'instance-1'
# region for the EC2 instance
- name: REGION
value: 'us-east-1'
Multiple EC2 instances
It specifies multiple EC2 instances as comma-separated IDs that are targeted in one chaos run. Tune it by using the EC2_INSTANCE_ID environment variable.
The following YAML snippet illustrates the use of this environment variable:
# multiple instance targets
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
chaosServiceAccount: litmus-admin
experiments:
- name: ec2-memory-hog
spec:
components:
env:
# ids of the EC2 instances
- name: EC2_INSTANCE_ID
value: 'instance-1,instance-2,instance-3'
# region for the EC2 instance
- name: REGION
value: 'us-east-1'
Multiple workers
It specifies the CPU threads that need to be run to increase the file system utilization. This increases the amount of file system consumed. Tune it using the NUMBER_OF_WORKERS environment variable.
The following YAML snippet illustrates the use of this environment variable:
# multiple workers to utilize resources
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
chaosServiceAccount: litmus-admin
experiments:
- name: ec2-memory-hog
spec:
components:
env:
- name: NUMBER_OF_WORKERS
value: '3'
# ID of the EC2 instance
- name: EC2_INSTANCE_ID
value: 'instance-1'
# region for the EC2 instance
- name: REGION
value: 'us-east-1'