Ingest results from unsupported scanners
You can ingest custom issues from any scanning tool. STO supports a generic JSON format for ingesting data from unsupported scanners that cannot publish to SARIF.
Important notes for importing data from unsupported scanners into STO
-
This workflow is intended for scanners that have no supported integration in STO. Harness recommends that you always use the documented workflow for supported scanners. For a list of all STO-supported scanners, go to What's supported and click Harness STO scanner support to expand.
-
SARIF is an open data format supported by many scan tools. If your scanner supports this format, publish your results to SARIF. For more information, go to Ingest SARIF results.
-
For STO to ingest your scan results, the ingestion file must match the JSON format specified below.
Required steps to ingest data from unsupported scanners into STO
-
Add a shared path such as
/shared/scan_resultsto the stage. Go to Overview > Shared Paths in the visual editor, or add it to the YAML like this:- stage:
spec:
sharedPaths:
- /shared/scan_results -
Generate your issues data in the required JSON format described below and then save it in the shared folder.
You might want to set up a Run step to generate your scans automatically whenever the pipeline runs. Go to Ingest Scan Results into an STO Pipeline for an example. -
Add a Custom Ingest step and configure the scanner to ingest the results of the scan. For information about how to configure this step, go to Custom Ingest settings reference.
JSON data format reference
The following example illustrates the required format for your data:
{
"meta":{
"key":[
"issueName",
"fileName"
],
"subproduct":"MyCustomScanner"
},
"issues":[
{
"subproduct":"MyCustomScanTool",
"issueName":"Cross Site Scripting",
"issueDescription":"Lorem ipsum...",
"fileName":"homepage-jobs.php",
"remediationSteps":"Fix me fast.",
"risk":"high",
"severity":8,
"status":"open",
"referenceIdentifiers":[
{
"type":"cwe",
"id":"79"
}
]
}
]
}
The basic schema includes a “meta” section, which requires the following:
-
“key”The name of the attribute used to deduplicate multiple occurrences of an issue. In the example data file above,
"key"="issueName". Thus if the data includes multiple occurrences of an issue with the same"issueName", the pipeline combines these occurrences into one issue. The resulting issue includes a list of all occurrences and the data for each individual occurrence.The key used for deduplication must be a Harness field. Do not try to deduplicate based on non-Harness fields.
-
“subproduct”The scan tool name to apply to the overall issue.
The full JSON takes the form:
"meta":
{ ... },
"issues": [
{ "issue-1" : "data" },
{ "issue-2" : "data" },
{ "issue-3" : "data" }
}
Required fields for Harness STO JSON schema
| Name | Format | Description |
issueName | String | Name of vulnerability, license issue, compliance issue, etc. |
issueDescription | String (long) | Description of vulnerability, license issue, compliance issue, etc. |
subProduct | String | The scan tool name to apply to the individual occurrence of the issue. |
severity | Float | CVSS 3.0 score (a number from 1.0-10.0) |
Recommended fields for Harness STO JSON schema
| Name | Format | Description |
confidence | Float | Derived from the tool output. |
cvss | String (long) | Derived from the tool output. |
fileName | String | Recommended to assist in triaging errors (if present). |
host | String | Recommended to assist in triaging errors (if present). |
ip | String | Recommended to assist in triaging errors (if present). |
issueType | String | Type of issue (e.g. vulnerability, license issue, compliance issue, etc.) |
lineNumber | String | Recommended to assist in triaging errors (if present). |
link | String | Recommended to assist in triaging errors (if present). |
port | Integer | Recommended to assist in triaging errors (if present). |
product | String | Logical metadata field that can be used for tracking of product(s). |
project | String | Logical metadata field that can be used for tracking of project(s) |
remediationSteps | String (long) | Remediation instructions, often provided by the scan tool. |
scanSeverity | String | The severity as reported by the scan tool. |
scanStatus | String | Recommended for measuring scan duration and status. |
tags | String | Logical metadata tags, which can be leveraged to describe asset owners, teams, business units, etc. |
url | String | Recommended to assist in triaging errors (if present). |
Optional fields for Harness STO JSON schema
| Name | Format | Description |
author | String | Logical metadata field designed to track the owner of the scan result. |
effort | String (long) | Logical metadata field designed to gauge the required effort to remediate a vulnerability. |
exploitabilityScore | Float | Derived from the tool output. |
imageLayerId | String | Metadata field to track image layer ID from containers. |
imageNamespace | String | Logical metadata field. |
impactScore | String | Derived from the tool output. |
libraryName | String | Derived from the tool output. |
license | String | Derived from the tool output. |
linesOfCodeImpacted | String | Recommended to assist in triaging errors (if present). |
referenceIdentifiers | Array | An array of Vulnerability identifiers, such as cve, cwe, etc. Here's an example. Note that the type value must be lowercase.
“referenceIdentifiers”: [ {“type” : “cve”,“id” : “79”}, {"type" : "cwe", "id" : "83"}] |
Custom fields for Harness STO JSON schema
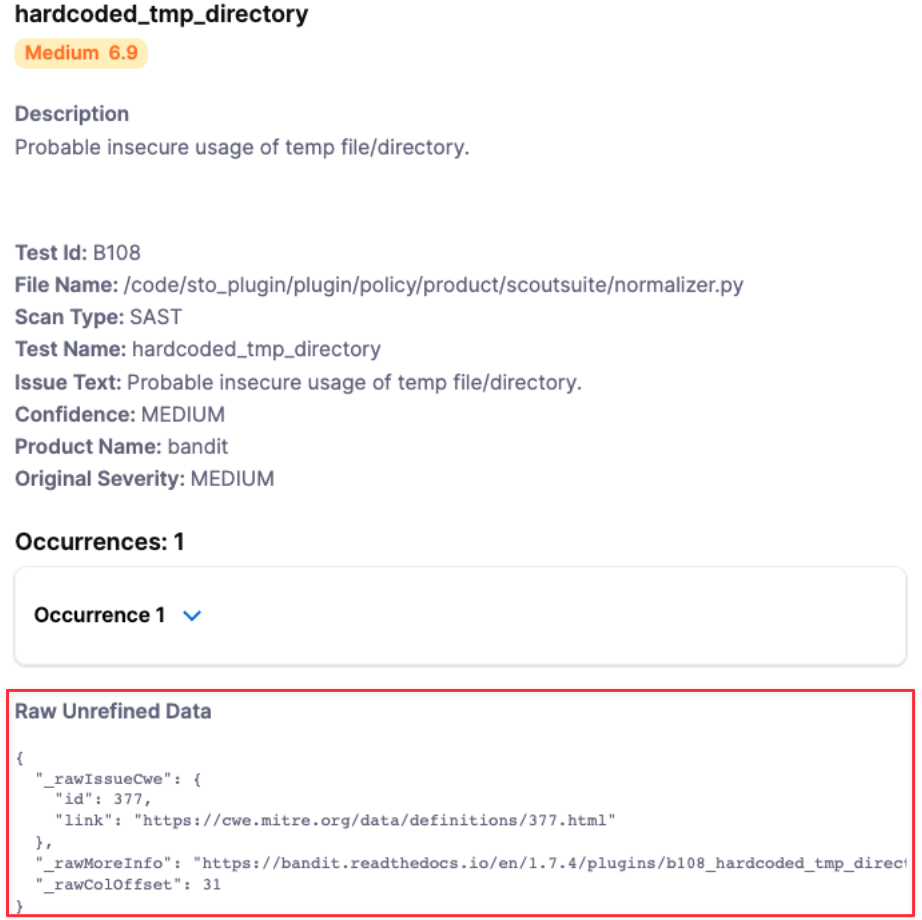
You can add custom fields to an issue. The only restriction is that you cannot use any of the reserved keywords listed above. To include raw, unrefined data, add the prefix "_raw" to the field name. For example, you can add the following "_raw" fields to an issue:
{
"testName":"hardcode_tmp_directory",
......
"referenceIdentifiers":[
{
"type":"cwe",
"id":"79"
}
],
"_rawIssueCwe": {
"id" : 377,
"link" : "https://cwe.mitre.org/data.definitions/377.html"
},
"_rawMoreInfo" : "https://bandit.readthedocs.io/en/1.7.4/plugins/b108_hardcoded_tmp_directory.html",
"_rawColOffset":31
}
The custom fields will get grouped together at the end of the issue details like this:
Reserved keywords for Harness STO JSON schema
The following keywords are reserved and cannot be used in your JSON file:
alertRulesetscustomerIddiscoveryIssueIddiscoveryRunTimediscoveryTimespanignoreignoreRulesetsjobIdpolicyIdpolicyNamerefinementVersionremediationRunTimeremediationTimespanrunTimescenarioIdseverityCodetargettargetId
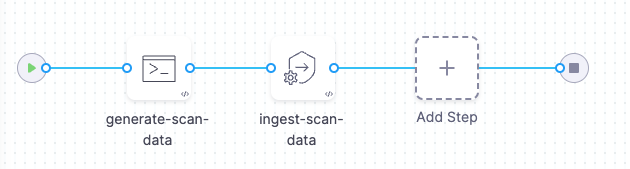
Pipeline example for ingesting data from an unsupported schema into STO
The following pipeline shows an end-to-end ingestion workflow. The pipeline consist of a Security stage with two steps:
-
A Run step that generates a JSON data file
/shared/scan_results/example.jsonin the format described above. -
A Custom Ingest step that ingests and normalizes the data from
/shared/scan_results/example.json.
pipeline:
projectIdentifier: myProject
orgIdentifier: default
tags: {}
stages:
- stage:
name: custom-scan-stage
identifier: customscanstage
type: SecurityTests
spec:
cloneCodebase: false
execution:
steps:
- step:
type: Run
name: generate-scan-data
identifier: Run_1
spec:
connectorRef: CONTAINER_IMAGE_REGISTRY_CONNECTOR
image: alpine:latest
shell: Sh
command: |-
cat <<EOF >> /shared/scan_results/example.json
{
"meta":{
"key":[
"issueName",
"fileName"
],
"subproduct":"MyCustomScanner"
},
"issues":[
{
"subproduct":"MyCustomScanTool",
"issueName":"Cross Site Scripting",
"issueDescription":"Lorem ipsum...",
"fileName":"homepage-jobs.php",
"remediationSteps":"Fix me fast.",
"risk":"high",
"severity":8,
"status":"open",
"referenceIdentifiers":[
{
"type":"cwe",
"id":"79"
}
]
}
]
}
EOF
ls /shared/scan_results
cat /shared/scan_results/example.json
- step:
type: CustomIngest
name: ingest-scan-data
identifier: CustomIngest_1
spec:
mode: ingestion
config: default
target:
name: external-scanner-test
type: repository
variant: main
advanced:
log:
level: info
ingestion:
file: /shared/scan_results/example.json
sharedPaths:
- /shared/scan_results
caching:
enabled: false
paths: []
platform:
os: Linux
arch: Amd64
runtime:
type: Cloud
spec: {}
identifier: custom_ingestion_JSON_test
name: custom ingestion JSON test