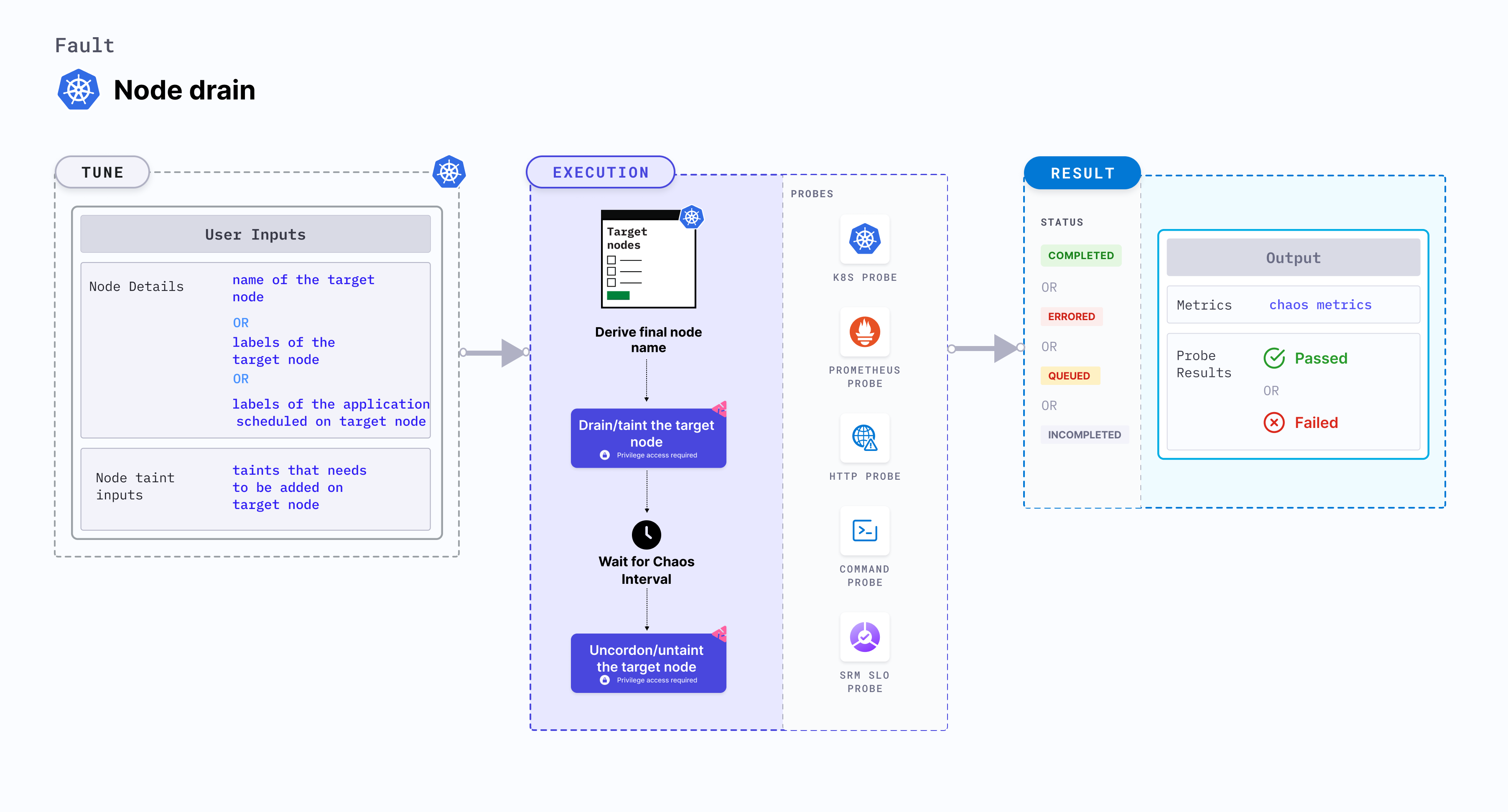
Node drain
Node drain drains the node of all its resources running on it. Due to this, services running on the target node should be rescheduled to run on other nodes.
Use cases
- Node drain fault drains all the resources running on a node.
- It determines the resilience of the application when the application replicas scheduled on a node are removed.
- It validates the application failover capabilities when a node suddenly becomes unavailable.
- It simulates node maintenance activity (hardware refresh, OS patching, Kubernetes upgrade).
- It verifies resource budgeting on cluster nodes (whether request (or limit) settings are honored on available nodes).
- It verifies whether topology constraints are adhered to (node selectors, tolerations, zone distribution, affinity(or anti-affinity) policies) or not.
Permissions required
Below is a sample Kubernetes role that defines the permissions required to execute the fault.
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: hce
name: node-drain
spec:
definition:
scope: Cluster
permissions:
- apiGroups: [""]
resources: ["pods"]
verbs: ["create", "delete", "get", "list", "patch", "deletecollection", "update"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "get", "list", "patch", "update"]
- apiGroups: [""]
resources: ["chaosEngines", "chaosExperiments", "chaosResults"]
verbs: ["create", "delete", "get", "list", "patch", "update"]
- apiGroups: [""]
resources: ["pods/log"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["pods/exec"]
verbs: ["get", "list", "create"]
- apiGroups: ["batch"]
resources: ["jobs"]
verbs: ["create", "delete", "get", "list", "deletecollection"]
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "patch", "update"]
- apiGroups: [""]
resources: ["pod eviction"]
verbs: ["get", "list", "create]
Prerequisites
- Kubernetes > 1.16
- Node specified in the
TARGET_NODEenvironment variable should be cordoned before executing the chaos fault. This ensures that the fault resources are not scheduled on it (or subject to eviction). This is achieved by the following steps:- Get node names against the applications pods using command
kubectl get pods -o wide. - Cordon the node using command
kubectl cordon <nodename>.
- Get node names against the applications pods using command
- The target nodes should be in the ready state before and after injecting chaos.
Mandatory tunables
| Tunable | Description | Notes |
|---|---|---|
| TARGET_NODES | Comma-separated list of nodes subject to node CPU hog. | For more information, go to target nodes. |
| NODE_LABEL | It contains the node label that is used to filter the target nodes. | It is mutually exclusive with the TARGET_NODES environment variable. If both are provided, TARGET_NODES takes precedence. For more information, go to node label. |
Optional tunables
| Tunable | Description | Notes |
|---|---|---|
| TOTAL_CHAOS_DURATION | Duration that you specify, through which chaos is injected into the target resource (in seconds). | Default: 60 s. For more information, go to duration of the chaos. |
| NODES_AFFECTED_PERC | Percentage of total nodes to target, that takes numeric values only. | Default: 0 (corresponds to 1 node). For more information, go to node affected percentage. |
| SEQUENCE | Sequence of chaos execution for multiple target pods. | Default: parallel. Supports serial sequence as well. For more information, go to sequence of chaos execution. |
Drain node
Name of the target node. Tune it by using the TARGET_NODE environment variable.
The following YAML snippet illustrates the use of this environment variable:
# drain the targeted node
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: node-drain
spec:
components:
env:
# name of the target node
- name: TARGET_NODE
value: 'node01'
- name: TOTAL_CHAOS_DURATION
VALUE: '60'