Service Reliability Management release notes
These release notes describe recent changes to Harness Service Reliability Management (NextGen SaaS).
- Progressive deployment: Harness deploys changes to Harness SaaS clusters on a progressive basis. This means that the features described in these release notes may not be immediately available in your cluster. To identify the cluster that hosts your account, go to your Account Overview page in Harness. In the new UI, go to Account Settings, Account Details, General, Account Details, and then Platform Service Versions.
- Security advisories: Harness publishes security advisories for every release. Go to the Harness Trust Center to request access to the security advisories.
- More release notes: Go to Harness Release Notes to explore all Harness release notes, including module, delegate, Self-Managed Enterprise Edition, and FirstGen release notes.
April 2024
Version 1.5.0
Fixed issues
-
Fixed an issue where the View Deployment button in the change impact screen was not leading the user to the relevant page. (CHAOS-4517)
-
Fixed an issue where adding a new SLO to a composite SLO by editing it would re-calculate the weightage and override any value entered by the user. Now, the weights are calculated automatically only when a new composite SLO is created.(CHAOS-4534)
November 2023
Version 1.7.0
Fixed issues
- The Add Annotation drawer was opening even when clicking near the Add Annotation button. This issue has been resolved. Now, the Add Annotation drawer opens only when clicking on the Add Annotation button. (SRM-16062)
- The Add SLO screen wrongly indicated that a maximum of 20 SLOs could be selected, even though selecting a maximum of 30 SLOs was allowed. For example, when 30 SLOs were selected, it displayed "30/20 selected." This issue has been resolved. Now, the UI correctly indicates that a maximum of 30 SLOs can be selected. (SRM-16078)
- On the SLO tab, the Clear Filter option was not displayed when a filter was applied to the Evaluation field. This issue has been resolved. Now, the Clear Filter option is displayed when a filter is applied to the Evaluation field. (SRM-16079)
Version 1.6.1
New features and enhancements
- A new search functionality for the service and environment filters drop-down on the Changes page has been introduced. The filters now display a Search option when the drop-down list contains more than 10 options. (SRM-15946)
- The maximum number of simple SLOs that can contribute to a composite SLO has been increased from 20 to 30. (SRM-15972)
- Because a majority of change sources are now configured automatically, the behavior on the Change Impact screen has been modified. Now, when no change event is found in the selected time range, the "No change event" message is displayed instead of "Configure change source". (SRM-15985)
October 2023
Version 1.5.3
New features and enhancements
Added the option to set the start month of quarterly Service Level Objectives (SLOs). This enhancement helps you define your SLOs and match them with your organization's reporting and operational cycles. (SRM-15677)
Fixed issues
- The Changes page displayed all services and environments associated with an account, regardless of whether they were linked to a monitored service or not. This issue has been resolved. Now, the Service and Environment filters on the Changes page display only the services and environments linked to monitored services, whether they are at the account, organization, or project level. (SRM-15926)
- Simple SLO links on the Composite SLO details page were directing to blank pages. This issue has been resolved. Simple SLO links on the Composite SLO details page now correctly direct to the appropriate pages. (SRM-15957)
Version 1.4.2
New features and enhancements
On the SLO Details page, you can now view the count of contributing SLOs for composite SLOs. This enhancement simplifies the management of composite SLOs. (SRM-15825)
Fixed issues
- PagerDuty incidents were not captured in the free subscription environment. This issue has been resolved. Now, the PagerDuty incidents are being displayed in the free subscription environment. (SRM-10824)
- The change-event API was significantly slower when compared to other listing APIs, and the initial calls to the change-event API were failing. This issue has been resolved. Now, there is a significant improvement in the API response size and response time. (SRM-15709)
- On the Changes page, the Clear Filter button was enabled even when no filters were selected. This issue has been resolved. Now, the Clear Filter button is enabled only when the filters are selected. (SRM-15764)
- Selecting a large number of values in the Services and Environment filters on the Changes page led to error 414 indicating that the URL is too long. This issue is resolved by limiting selections to a maximum of 10 values for Services and Environment filters. (SRM-15765)
- An alignment issue with the Change Event card has been fixed to ensure consistent information display. (SRM-15793)
- The Service Level Indicator (SLI) iterator attempted to create tasks that already existed. This issue has been resolved. Now, the SLI iterator correctly handles task creation, preventing unnecessary retries. (SRM15870)
Version 1.3.3
Fixed issues
- The monitored service dropdown filter on the SLO listing page was restricted to displaying a limited number of services. This issue has been resolved. Now, the monitored service dropdown filter displays up to 100 values. (SRM-15690)
- In certain scenarios, there were delays of up to a day in receiving the SLI data, leading to outdated information. This issue has been resolved. Now, the most recent SLI data is available without any delays. (SRM-15692)
- The SLO details view page does not adapt to the browser's size, resulting in an improper display. This issue has been resolved. Now, the SLO details view page properly fits the size of your browser. (SRM-15712)
September 2023
Version 1.2.5
New features and enhancements
Added new filters named Environment-Based and SLO Type to the SLO listing page. You can now filter the SLO list on environment or SLO type for improved management. (SRM-15506)
Fixed issues
Previously, when any of the simple service-level objectives (SLOs) reported NO_DATA for the entire duration, and the missing data was treated as IGNORE, the composite SLO faced challenges as it required data from all underlying simple SLOs to perform calculations. Consequently, the composite SLO failed to produce any records and became unresponsive. This issue has been resolved. Now, if one or more simple SLOs report NO_DATA throughout the duration, even if the missing data is treated as IGNORE, the composite SLO continues to generate records with data for the entire duration. Importantly, the error budget for those minutes remains unaffected. (SRM-15376)
Version 1.1.3
New features and enhancements
SRM dashboards now include comprehensive data for composite Service Level Objectives (composite SLOs). This enhancement gives you a holistic view of both simple and composite SLO performance. (SRM-15419)
Fixed issues
FireHydrant notifications were not being triggered as expected for monitored services without any configured Service Level Objectives (SLOs). This issue has been resolved. FireHydrant notifications will now be triggered for all monitored services, irrespective of whether SLOs are configured. (SRM-15458)
Version 1.0.8
Fixed issues
- PagerDuty events were not being deleted after the deletion of a project or organization. This issue has been resolved. Deleting a project or organization no longer leaves behind orphaned Pagerduty events. (SRM-15263)
- The API endpoint
/cv/api/monitored-service/versions_int1was not functioning correctly. This issue has been resolved. Now, in cases where the "sources" field is received as null, the system treats it as equivalent to{ healthSources: [], changeSources: [] }. (SRM-15321) - The SRM default dashboard was non-functional, rendering it unusable. This issue has been resolved. Now, the SRM default dashboard is fully operational. (SRM-15372)
Platform version 80402
New features and enhancements
The Service Health tab on the monitored service details page has been renamed to Change Impact. (SRM-15261)
July 2023
Platform version 79812
New features and enhancements
You can now seamlessly create and manage monitored services at the Project level, as well as within the SRM and CD modules. You can view and manage the monitored services, regardless of where they were created. The monitored service list presents specific insights based on where you are accessing it. (SRM-14580)
- Project level: Shows service names and health source count, while interactive module icons allow you to effortlessly navigate to specific modules for a detailed view.
- CD module: Presents monitored service names alongside configured health sources, providing a comprehensive overview of health status.
- SRM module: Provides information, including monitored service status, name, SLO specifics, recent changes, 24-hour health trends, score, and dependency status.
Fixed issues
- During monitored service creation, when adding a health source that supported metrics, both Errors and Performance metric packs were automatically selected as default options. However, if the user chose to select only one of the options, when the monitored service was reopened, both metric options remained selected. This issue has been resolved. The selected metric pack option during monitored service creation will now be correctly reflected upon opening the monitored service. (SRM-14998)
June 2023
Platform version 79709
Fixed issues
- When configuring a health source, you were unable to input zero (0) in the Lesser Than and Greater Than fields. This issue has been fixed. You can now input zero (0) in both the fields. (SRM-14936)
- When using a template that has a service and an environment as input values to create a monitored service in a Verify step, you were unable to select the environment and service at the account, organization, or project levels. This issue has been resolved, and you can now select the desired environment and service in these cases as expected. (SRM-14944)
SocketTimedOuterror messages were not displayed in the call log. This issue has been fixed. The call log now showsSocketTimedOuterror messages. (OIP-537)- The HTTP capability checks were considering status codes as an important factor, even when proper headers were not being sent. This issue has been resolved. Now, the behavior of the HTTP capability checks has been modified to ignore status codes. (OIP-499)
- In the metrics analysis section, time-series graphs exhibit data shifting when the first applicable timestamp is missing. This issue has been fixed, and now the graphs reflect the intended starting points. (OIP-526)
Platform version 79608
Hotfix
Optimized Prometheus API calls by grouping per-host calls into a single call using the 'by' clause. As a result, the number of API calls to the Prometheus server during verification is reduced, leading to improved overall performance and efficiency in data retrieval and processing. (OIP-552)
Platform version 79600
Fixed issues
- SLOs were getting stuck in the recalculation state even after the recalculation process was complete. This issue has been resolved. Now, the SLOs transition to the appropriate state once the recalculation has finished successfully. (SRM-14849)
- When configuring a Deploy stage and selecting a value in the Propagate from field to propagate a service from the previous parallel stage, an error would occur when attempting to create a monitored service. This issue has been resolved. You can now successfully create a monitored service even when selecting a value in the Propagate from field to propagate a service from the previous parallel stage. (SRM-12454)
- The Monitored Service Listing page was not displaying the latest updated monitored service first. This issue has been resolved. Now, the monitored service list is sorted in the following order: (SRM-14845)
- A monitored service with the most recent update will be displayed at the top of the list.
- If a monitored service has been updated with new analysis data, it is given higher priority and displayed before other services on the list.
Platform version 79517
Fixed issues
Unable to select multiple environments when creating a monitored service for infrastructure. This issue has been resolved. You can now select multiple environments when creating a monitored service for infrastructure. (SRM-14794)
Platform version 79413
New features and enhancements
Now a summary of changes related to the number of feature flags and chaos experiments is also displayed on the Monitored Service listing page, along with the other custom change sources. (SRM-14742)
Fixed issues
- The ErrorBudgetReset API is incorrectly accepting Rolling type SLOs along with Calendar type SLOs. This issue has been resolved. Now, the ErrorBudgetReset API only accepts Calendar type SLOs. (SRM-14692)
- Unable to create SLO using SignalFX metrics. This issue has been resolved. Now, SignalFX's health source supports SLI functionality, and you can create SLOs using SignalFX metrics. (OIP-406)
May 2023
Platform version 79307
New features and enhancements
- Continuous Error Tracking (CET) is a separate module in Harness now and no longer available as a health source in SRM. To learn more about CET, go to the Continuous Error Tracking Documentation. (SRM-14701)
- Clicking on a Prometheus metrics entry in the Service Health page of a monitored service directly navigates you to the Prometheus metrics dashboard. (SRM-14699)
- In the event of an SLO encountering an error, it is now displayed in the respective Simple and Composite SLOs. Additionally, when the underlying issue causing data collection failures is resolved, the missed data that couldn't be collected during the error period will be restored. However, there is a time limit for data restoration, which is set at 24 hours. For example, if the issue is resolved within 48 hours, only the last 24 hours of data is restored. (SRM-14672)
- Verify step in CV has a new icon. (OIP-3)
- You can now configure your monitored service to trigger notifications whenever there are updates or changes related to chaos experiments or feature flags. (SRM-14553)
- New errors are introduced to provide a comprehensive insight into SLO's performance. Now, errors are displayed in the following scenarios: (SRM-14549)
- Ongoing Problem: Errors are displayed when an SLO experiences an ongoing problem, such as an issue with the health of a connector.
- Missing Data: Errors are shown when there is missing data in an SLO, even if there is no current error. This helps identify any gaps in historical SLO records.
- Contributing SLO Issues: Errors in contributing SLOs are now reflected in the composite SLO, ensuring a complete picture of performance when individual components encounter problems.
Fixed issues
- Error budget burn rate notifications are not being sent for Request Based SLO. This issue has been resolved, and error budget burn rate notifications are now being sent for Request Based SLO also. (SRM-14705)
- Error budget burn rate notifications are not being sent for composite SLOs. This issue has been resolved, and error budget burn rate notifications are now being sent for composite SLOs. (SRM-14658)
- Encountering an error when configuring monitored services using the Harness Terraform Provider. The Harness Terraform Provider was sending the Terraform resource incorrectly, resulting in the error. This issue has been resolved. (SRM-14684)
- On the Composite SLO Details page, the environment links under the monitored services were broken. This issue has been resolved. Now, clicking on the environment link correctly displays the SLOs page for the respective monitored service. (SRM-14645)
- The last updated date and time of monitored services and SLOs are changing automatically even when no configuration changes were made. This issue has been resolved. Now, the last updated date and time will change only when modifications are made to the configuration of the monitored services and SLOs. (SRM-14543)
- Missing data in SLOs was not considered in error budget burn rate notifications. This issue has been resolved. Now the missing data is treated according to user preference (GOOD, BAD, or IGNORE), contributes to error budget burn rate, and is included in notifications.(SRM-14682)
Platform version 79214
New features and enhancements
An icon appears on the SLO performance trend chart timeline to indicate when the error budget was reset and the amount of budget that was added. (SRM-14550)
Fixed issues
- The Error Budget Burn Rate is above SLO notification setting was not triggering notifications, even when the condition was met. This issue has been resolved and notifications are being triggered when the Error Budget Burn Rate is above condition is met. (SRM-14613)
April 2023
Platform version 79111
New features and enhancements
- Added new advanced fields for consecutive error budgets in SLO. These fields are optional. (SRM-14507)
- Removed the mandatory check for the presence of Tier in the AppDynamics complete metric path. (SRM-14463)
Fixed issues
- The title in the expressions modal of health sources has been updated from Shell (Bash) to Query. (SRM-14478)
- Monitored service cannot be deleted if it is created with an invalid connector. To fix this issue, the UI connector component is now enabled when the provided connector is not found. (SRM-14403)
- For CloudWatch CV connector, IRSA was not supported for connectivity. Support for IRSA connectivity was added. (SRM-13907)
- Unable to create notifications while configuring composite SLO at account level. This issue has been resolved. Now, you can create notifications for composite SLOs at the account level. (14474)
Platform version 79015
New features and enhancements
Filters applied to the monitored services list on the Monitored Services page will get reset when you switch to a different project. (SRM-14383)
Fixed issues
- When switched to a different project while a template was open, the health sources from the previous template would remain visible in the template, even though they were not part of the new project. This issue has been resolved. Now, when you switch to a different project while a template is open, you will be redirected to the templates listing page. (SRM-12236)
- The SLO health summary cards displayed in a monitored service's health dashboard show summarized data for SLOs associated with all the monitored services in the project, even if the SLOs are not connected to the selected monitored service. This issue has been resolved. Now, the SLO health summary cards displayed in a monitored service's health dashboard will show summarized data only for the SLOs associated with the selected monitored service. (SRM-14462)
March 2023
Platform version 78914
Fixed issues
- Monitored service creation fails when using a monitored service template that has Org or Account level service and environment. This restriction is removed. Now, you can create a monitored service using a monitored service template with Org or Account level service and environment. (SRM-14291)
- On the Monitored Services list page, a help panel appears for every monitored service listed. This is resulting in an overwhelming number of help panels that need to be closed individually. This issue has been resolved. Now, only one help panel appears for all monitored services listed on the page. (SRM-14266)
- SLO error budget notifications are being triggered even when the notification rule is disabled. This issue has been resolved. Now, SLO error budget notifications are not triggered if the notification rule is disabled. (SRM-13997)
Platform version 78817
New features and enhancements
- When you try editing an existing SLO, you will see the Tags (optional) field autopopulated even if no value was entered while creating the SLO. Harness uses the selected SLI type as value to autopopulate the Tags (optional) field. (SRM-14121)
- There is a new user interface (UI) for Elasticsearch health source configuration. This update is designed to improve the overall user experience and make it easier to configure Elasticsearch health sources. (SRM-14180)
Fixed issues
- The Time Window in the Service Health tab does not display the information for an event by default when accessed using the link in the event notification. Users had to manually search for the information by moving the Time Window to the event's date and time. This issue has been resolved. The Time Window now displays the event information automatically when accessed using the link in the notification. Users no longer need to manually search for the information by moving the Time Window to the event's date and time. (SRM-14071)
- Error encountered when setting up monitored service in verify step with Org or Account level service and environment. This restriction is removed. You can create a monitored service in the verify step even if the service and environments are at the Org or Account level. (SRM-14191)
- Unable to set the duration in the Verify step as an expression or use a value from other fields or variables. This restriction has been removed. You can now set the Verify step duration using an expression or a value from other fields or variables. (SRM-13981)
- If a monitored service is updated in an SLO, the Monitored Service List page does not display the updated information in the SLO/ERROR BUDGET column. Instead, it shows that the SLO is still linked to the previous monitored service. This issue has been resolved, and the SLO/ERROR BUDGET column will now display the updated information when a monitored service is updated in an SLO. (SRM-14078)
- The verify step fails when a monitored service is deleted and recreated within two hours with a different connector ID. This issue has been resolved, and now the Verify step does not fail if the health source is deleted and recreated within 2 hours with a different connector ID. (SRM-14021)
- If there is no data received from one of the metric packs while configuring AppDynamics as a health source, the validation fails. This issue has been resolved. Now, the validation passes if there is incoming data from any one of the metric packs.(SRM-13597)
- The Source Code tab on the Automated Root Cause (ARC) screen shows blank during decompilation of source code instrumented with JaCoCo. This issue has been fixed. (CET-1175)
- The impacted services values were shown as "0 Service(s)" in the Event list. This issue has been fixed. (CET-1136)
Platform version 78712
New features and enhancements
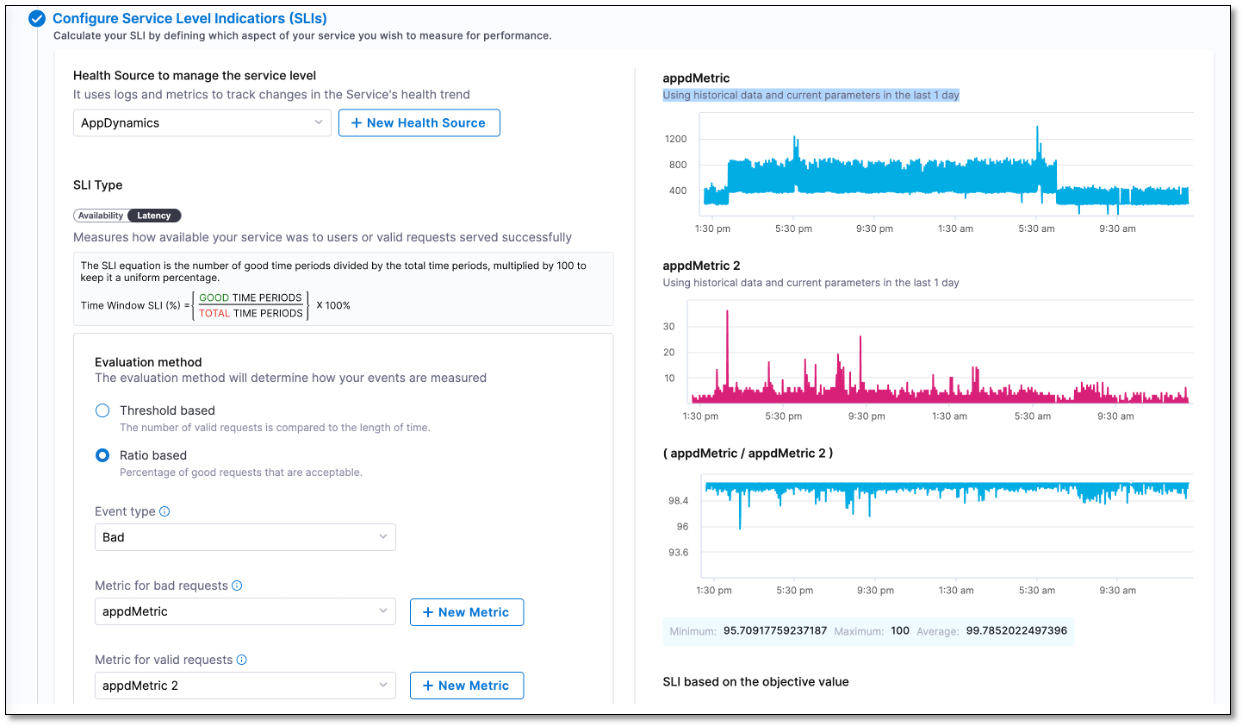
Metrics graphs are now added to the Create SLO screen. (SRM-14025)
When configuring Service Level Indicators (SLIs) in the Create SLO screen, you will now see a metric graph based on the last 24 hours of data received from your health monitoring tool. Additionally, the recommended minimum, maximum, and average values specific to the SLI parameter that you are configuring will be displayed.
This feature eliminates the need for switching between the Harness Create SLO screen and your health monitoring tool dashboard to determine the most appropriate value for the SLI parameter you are configuring. For instance, if you opt for the ratio-based evaluation method while configuring your SLI, you can refer to the metric graphs and accompanying suggested values to determine the ideal percentage of valid requests to be considered for your SLI.
Fixed issues
- Continuous Verification (CV) fails due to timestamp format difference. This issue is fixed by updating the timestamp format in the API request. (SRM-14167)
- Long Prometheus metric links overflow outside the METRIC NAME column and obstruct adjacent column values in the console view during pipeline runs. This issue is fixed and the long Prometheus metric links are now contained within the METRIC NAME column, preventing them from obstructing values in the adjacent column. (SRM-14107)
- After saving and reopening a monitored service template, the Save button remained enabled even if no changes are made. This issue is fixed, and the Save button is now enabled only if changes are made to the monitored service template. Additionally, an unsaved changes alert now appears next to the Save button when changes are made to the template values. (SRM-14085)
Platform version 78619
New features and enhancements
You can specify metric thresholds for the health source when creating a monitored service template. This helps you predefine the metric thresholds and removes the hassle of specifying them every time you create a new monitored service. (SRM-13972)
February 2023
Platform version 78507
Early access features
This release introduces the standalone Harness Error Tracking (ET) experience. With this, you can quickly start using ET by installing the ET Agent on your Java Virtual Machine (JVM) and configuring it with Harness SRM. This feature is behind the feature flag SRM_ET_EXPERIMENTAL. (SRM-12696)
January 2023
Platform version 78105
Fixed issues
- Saving the verify step in a stage template throws the
Invalid YAML. Can't find pipelineerror if the pipeline key is missing in YAML. You can now save the verify step in a stage template even if the pipeline key is missing in YAML. (SRM-13320) - Even though metric data is not available from the health source for a time period, the Overall Health Score timeline displays green bars and shows the service score as 100. Now, on the Service Health page, the Overall Health Score timeline displays grey bars if metric data is unavailable from the health source for a specific time period. It does not show the health score. (SRM-13336)
Previous releases
2022 releases
2022 releases
December 2022
Platform version 77808
Early access features
Continuous Verification (CV) fails if the data for configured deployment strategy is not available. (SRM-12731)
Harness was automatically applying an alternate deployment strategy even if the required data for the deployment configured in the Verify step was not available.
Now, Harness does not automatically apply an alternate deployment strategy if the required data is not available. Instead, Harness fails the CV. Harness automatically applies an alternate deployment strategy only if you choose the Auto option in the Continuous Verification Type dropdown list when configuring the Verify step.
Platform version 77716
New features and enhancements
Increased limit for number of PagerDuty services. The PagerDuty Service dropdown list, which displayed up to 25 services, can now display up to 100 services. (SRM-13102)
Fixed issues
Pipeline deployment throws an exception with the message RuntimeException: name cannot be more than 64 characters long. if the name of the monitored service exceeds 64 characters. This restriction is now removed, and the name of the monitored service can contain up to 128 characters. (SRM-12811)
November 2022
Platform version 77608
New features and enhancements
To prevent inadvertently configuring invalid metric thresholds, the following changes have been made to the Customize Health Source tab's Advanced (Optional) configuration section: (SRM-12386)
- Under the Ignore Thresholds settings, only the Less than option is available for the Percentage Deviation criteria. The Greater than option is removed.
- Under the Fail-Fast Thresholds settings, only the Greater than option is available for the Percentage Deviation criteria. The Less than option is removed.
Fixed issues
- When the metrics feature was selected for the Splunk health source, the Continuous Verification and Service Health options were getting selected by default, even though those options are not supported for Splunk. This was causing continuous verification to fail. Now, if you select the metrics feature for the Splunk health service, the continuous verification and service health options are disabled. Only the SLI option is available. (SRM-12793)
- Custom metric configuration for the Splunk and New Relic health sources fails if the Metric Value JSON Path and Timestamp Field/Locator JSON Path queries contain a period (
.). Now, the Metric Value JSON Path and Timestamp Field/Locator JSON Path queries are automatically wrapped with square brackets and single quotes. This prevents the custom metric configuration from failing even if your JSON path queries contain a period (.). (SRM-12552)
September 2022
Platform version 76619
Fixed issues
- Metric Threshold configurations weren't persisting if the criteria was percentage deviation and you selected Lesser than for the Fail-Fast Thresholds. (SRM-11696)
- Fixed and issue where you couldn't update the Prometheus source. (SRM-11578, ZD-33879)
August 2022
Platform version 76518
Fixed issues
- Fixed an error that occurred while setting up a CV step in a Harness NG pipeline. (SRM-11553, ZD-33562)
- The ServiceMethodId udpates when you select Dynatrace service from the dropdown menu.
Platform version 76321
Fixed issues
- Fixed an issue where request body place holders weren't serialized properly unless surrounded by double quotes (
" "). The request body for custom log source was not getting serialized properly due to the treatment of numbers in Gson library which we use. By upgrading the version of the library, we now have support to customize this behavior. Now we have defined how a number will be deserialized. (SRM-11217) - Fix the text wrapping in Health Sources table in Verify step. (SRM-11185)
Platform version 76128
Fixed issues
- Fetching Audits and JSON DTO Issues in Audit List API. Sequence in which services are deleted when project is deleted was incorrect. Now while deleting the project we can see both Monitored service and SLO audits. (SRM-11140)
- Monitored Service with New Relic health source displays error message "same identifier is used by multiple entities" even though there is no other health source with same ID. (SRM-10999)
Platform version 76030
Fixed issues
Verification wasn't happening correctly when we configure Monitored Service using templates. Verify step for Template type Monitored Service was not working due to a missing record in the database. For such use cases, we use a transient entity. Updated to code to support both transient and persisted entities. (SRM-11097)
July 2022
Platform version 75921
Fixed issues
- Data Collection for CustomLogs failed in Verification step. The Custom Log Health Source feature was unable to collect and process the data in the Verify step. This feature uses different DSL scripts to collect log data and service instance (host) data. If the log data collection DSL can also provide the host data, we do not need the host data DSL explicitly. However, in this case, the log collection DSL was also being used to collect the host data, which led to a Type mismatch error during the data processing. By removing the use of log collection DSL as the host collection DSL, we are able to pull the host data from the log data itself and it also ceases the exception. This feature is now working correctly. (SRM-11003)
- Creation of Custom Health Source Metrics for Service based failed. The Custom Metric Source Health did not work if the data query type was of type Service. The issue was happening due to a validation on the field metricPath in the Json response mapping, which is not present for the given query type. The given field is now optional. This issue has been resolved. (SRM-11002)
- GCP Metric Verify step null pointer exception in execution logs for GCP metric Health Source. Fixed a null pointer exception in data collection for verify step. (SRM-10674)
- Not able to create an SLO with GCP as metrics. Improved logging related to this issue. (SRM-10594)
Platform version 75829
Fixed issues
- Continuous Verification not appearing in Deployment Stage template. Continuous Verification step was not appearing. Continuous Verification step now appears. (SRM-10934)
- Email Notification failing with invalid template message. Added the message body into a string and formatted with HTML. (SRM-10923)
- SLO says "recalculating" for over a day. (SRM-10864)
- Continuous Verification filter taking default monitored service for configured and template use case. Implemented Continuous Verification filter logic for configured and template use case. (SRM-10839)
- Custom Health Host Metric data collection not collecting data for all hosts. (SRM-10831)
- Prometheus Continuous Verification perpetual task failing. Caused by comparability issues in decrypting data. Handling it gracefully now. Fixed compatibility issues with perpetual task. (SRM-10829)