Group steps using step groups
Steps can be added to pipelines individually or as a step group.
Individual steps and steps in step groups can be run serially or in parallel.
Unlike individual steps, a step group can apply conditional execution (skip conditions) and a failure strategy to all steps in the group.
You can also run pipeline stages in parallel. Deploy multiple services simultaneously and perform flow control using Barriers. Go to synchronize deployments using barriers for more information. This topic describes how to add a step group in a stage.
Review the following topics before you add step groups.
Important notes
- Currently, Harness supports step groups in Build, Deploy, and Custom stages only.
- When you run steps in parallel you cannot reference the outputs of one step in another step. The output for one step might not be available when another step requests it.
- Delegate selectors can be configured for each step in the step group. You cannot configure a delegate selector at the group level.
Containerized step groups
By default, the tasks performed by Harness CD steps are run on the Harness Delegate host system, for example, the Kubernetes cluster where a Kubernetes delegate is running.
To provide greater control over the resources used for CD steps, Harness also lets you use your own Kubernetes cluster as the runtime infrastructure for CD steps.
You can use a CD step group that points to your cluster as the runtime infrastructure. Next, in the step group, you can add the steps supported by containerized step groups.
Containerized step groups cannot have nested step groups, but you can put groups of steps next to each other in a containerized step group:
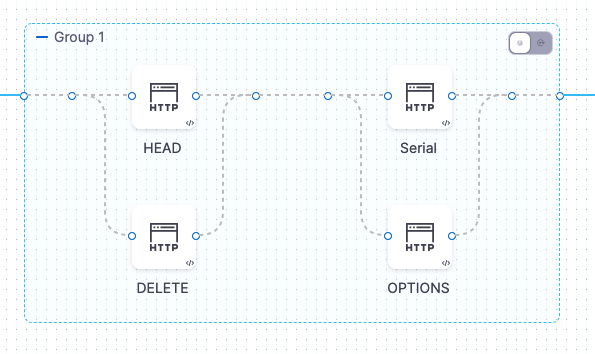
The steps in each group run in parallel but each group runs serially.
For more information, go to Containerize step groups.
Visual summary
This short video walks through step groups:
Common parallel steps
Running steps in parallel can be beneficial in many ways, such as:
- Simulating load using multiple HTTP steps.
- Running multiple Verify steps for different providers (AppDynamics, Splunk, Prometheus, etc).
- Running independent steps that don't need to be run serially.
- Running multiple Kubernetes Apply steps to deploy multiple Kubernetes resources at once.
- Deleting multiple resources at once.
- Creating or updating multiple Jira issues using Jira Create and Jira Update steps.
- Provisioning multiple resources using Terraform. Go to provision with the Terraform Apply step for more details.
- Save time. You might have 5 steps but you can run steps 2 and 3 in parallel because they are independent. Step 4 is run once they have completed.
Add and name the step group
In your stage, in Execution, select Add Step and then select Step Group.

The step group setting appear.
Enter a name for the step group.
Step group variables
Step group variables are custom variables that you can add and refer in your pipeline. They're available across the pipeline.
Variables of type string, secret, or number can be added in step group. Their values can be fixed value, runtime input, or expression.
You can refer step group variables within the step group using the expression, <+execution.steps.[step group id].variables.[variable name]>.
You can refer step group variables outside the step group using the expression, <+pipeline.stages.[stage Id].spec.execution.steps.[step group id].variables.[variable name]>.
Output variables
You can reference step group output variables using expressions using the step group name. Here's a sample expression:
<+execution.steps.<stepGroupID>.steps.stepID.outputVariables.[variable name]>.
If you are accessing the output variable in a step within the same step group you can use a shorter notation, <+stepGroup.steps.step1Identifier.output.outputVariables.[variable name]>.
If your step group is configured as a loop, an index is added at the end of the identifier to identify the unique loop instance. You can use this index to reference output variables. For example, <+execution.steps.<stepGroupID_[index]>.steps.stepID.outputVariables.[variable name]>.
Execution input is not supported for step group variables.
Conditional execution
A step group can have its own conditional execution settings separate from the conditional execution settings for the stage. The conditional execution settings of the step group apply to all of its steps.
For more information, go to Define conditional executions for stages and steps.
The conditional execution settings of any step in a step group overrides the conditional execution settings of the step group.
If you do not use step group conditional execution settings, then the stage's conditional execution settings are used.
Step group failure strategy
A step group can have its own failure strategy separate from the failure strategy for the stage.
The failure strategy can execute the Rollback steps for the step/stage.
Go to step failure strategy settings for more information.
The failure strategy of any step in a step group overrides the Failure Strategy of the step group.
If you do not use a step group failure strategy, then the stage's failure strategy is used.
Add steps to the step group
Once the step group is added, in its Execution section, in the new step group, select Add Step.
Add any step and configure its Advanced settings.
A step's Advanced settings override the Advanced settings of the step group.
Reference step group steps
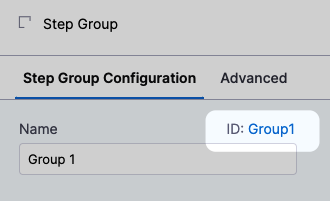
You reference steps in step groups using the step group Id.
The FQN format is:
<+pipeline.stages.[stage Id].spec.execution.steps.[step group Id].steps.[step Id].[step setting name]>
For example, to reference the URL setting in an HTTP step in a step group with the Id Group1, the FQN would be:
<+pipeline.stages.HTTP.spec.execution.steps.Group1.steps.OPTIONS.spec.url>
Override service variables in step groups
You can customize and override service variables during the execution of a step group. This provides significant flexibility and control over your pipelines. The expression <+serviceVariableOverrides.VARIABLE_NAME>overrides the original value of VARIABLE_NAME. You can use this expression in values YAML files and other parts of the pipeline where variables are used.
-
An overridden value is available only within the scope of the step group execution. In cases where a child group is included in a parent group, the child group override takes precedence.
The pipeline overrides variables based on the following priority:
- Step group override (child group, during execution)
- Step group override (parent group, during execution)
- Service environment overrides
- Environment configuration
- Service variable value (default)
-
Step group overrides are not recommended for artifacts and other objects fetched in the Service section of a pipeline stage. The one exception is scripts in custom remote manifests, because they can also be used during the Execution section of a pipeline stage.
Pipeline example: overriding variables in step groups
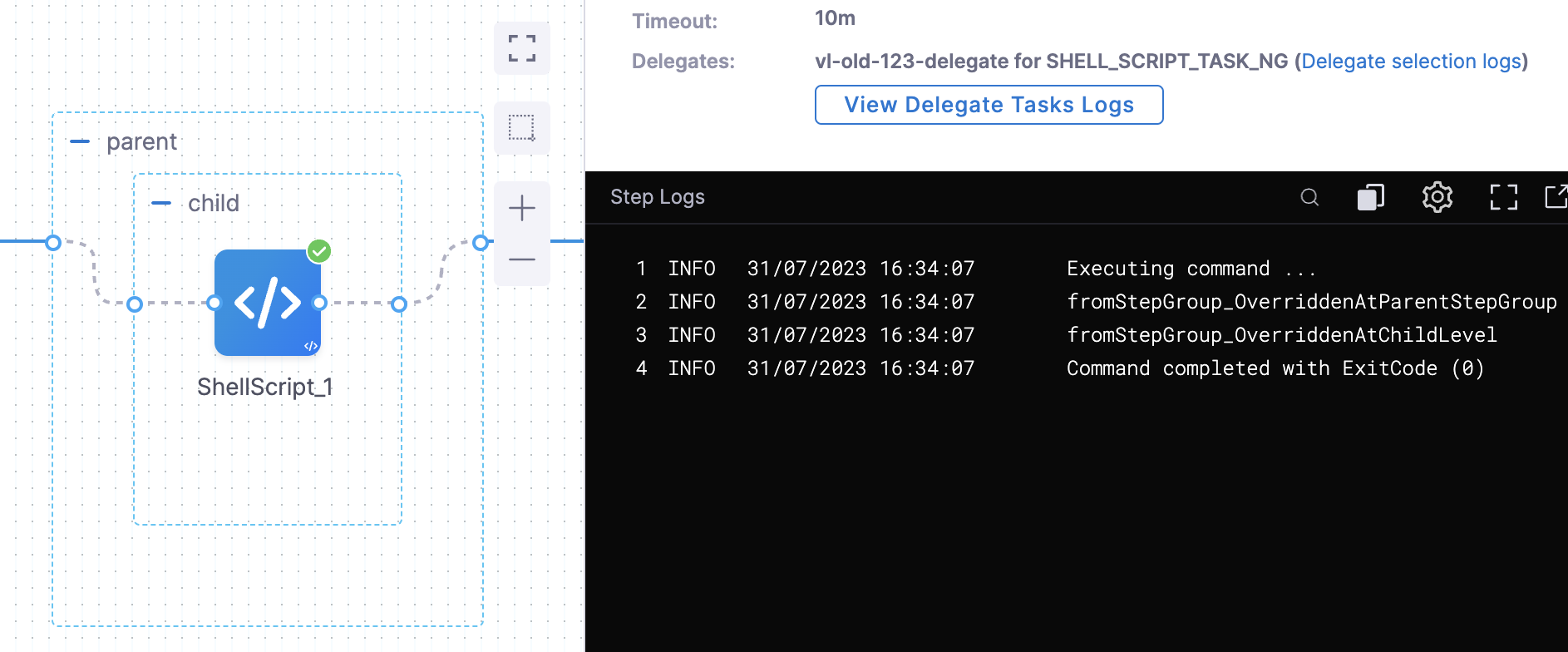
The following pipeline illustrates how to override service variables. The service definition has two defined variables, svar1 and svar2. The pipeline overrides these variables as follows:
- The
parentstep group overridessvar1with the valuefromStepGroup_OverriddenAtParentStepGroup. - The
parentstep group also has a variablesvarParentwith the valueDefinedAtParentLevel. Thechildstep group overrides this with the valueOverridenByChildStepGroup. - The
childstep group overridessvar2with the valuefromStepGroup_OverriddenAtChildLevel.
pipeline:
projectIdentifier: svcredesignhinger
orgIdentifier: harness
tags: {}
stages:
- stage:
name: dep
identifier: dep
description: ""
type: Deployment
spec:
deploymentType: Kubernetes
service:
serviceRef: TestStepGroupOverridesService
environment:
environmentRef: qa
environmentInputs:
identifier: qa
type: PreProduction
variables:
- name: rtvar1123
type: String
value: <+input>
deployToAll: false
infrastructureDefinitions:
- identifier: delegateInfra2
execution:
steps:
- stepGroup:
name: parent
identifier: parent
steps:
- step:
type: ShellScript
name: ShellScript_2
identifier: ShellScript_2
spec:
shell: Bash
onDelegate: true
source:
type: Inline
spec:
script: echo <+serviceVariableOverrides.svarParent>
environmentVariables: []
outputVariables: []
timeout: 10m
- stepGroup:
name: child
identifier: child
steps:
- step:
type: ShellScript
name: ShellScript_1
identifier: ShellScript_1
spec:
shell: Bash
onDelegate: true
source:
type: Inline
spec:
script: |+
echo <+serviceVariableOverrides.svar1>
echo <+serviceVariableOverrides.svar2>
echo "child overriding parent value"
echo <+serviceVariableOverrides.svarParent>
environmentVariables: []
outputVariables: []
timeout: 10m
variables:
- name: svar2
type: String
value: fromStepGroup_OverriddenAtChildLevel
description: ""
required: false
- name: svarParent
type: String
value: OverridenByChildStepGroup
description: ""
required: false
variables:
- name: svar1
type: String
value: fromStepGroup_OverriddenAtParentStepGroup
description: ""
required: false
- name: svarParent
type: String
value: DefinedAtParentLevel
description: ""
required: false
rollbackSteps: []
tags: {}
failureStrategies:
- onFailure:
errors:
- AllErrors
action:
type: StageRollback
identifier: StepGroupLevelOverrides
name: StepGroupLevelOverrides