Preview with the Terraform Plan step
The Terraform Plan step runs a Terraform plan to preview infrastructure changes before applying them. You can use it with a Terraform Apply step to apply the plan, or standalone to preview changes only. This page explains how to configure the Terraform Plan step in your CD pipeline.
Before you begin
-
Harness account with Continuous Delivery module enabled: You need access to Continuous Delivery in Harness. For how to access or create a Harness account, go to Getting started with Harness Platform.
Contact Harness support:If the Continuous Delivery module does not appear, contact your account administrator or Harness Support.
-
Pipeline and environment permissions: You need View, Create/Edit, and Execute for Pipelines, and View and Create/Edit for Environments. To get these permissions, an administrator must assign you a role that includes them. Go to RBAC in Harness and Manage roles to understand how permissions are assigned.
-
Terraform or OpenTofu installed on Harness Delegate: Terraform must be installed on the delegate to use a Harness Terraform provisioner. You can install Terraform manually or use the
INIT_SCRIPTenvironment variable in the delegate YAML.Install Terraform on delegates
Go to Build custom delegate images with third-party tools to learn how to install Terraform on delegates.
-
Terraform configuration files in a Git repository or cloud storage: Your Terraform scripts must be accessible via a Harness connector. Go to Connect to a Git Repo to create a Git connector. Go to Artifactory Connector Settings Reference to configure Artifactory (see Artifactory with Terraform Scripts and Variable Definitions (.tfvars) Files).
-
Secret Manager configured: Terraform plans contain sensitive data. Harness encrypts the plan using a Secret Manager before storing it. Go to Harness Secrets Manager Overview to configure a Secret Manager.
-
Understanding of Terraform concepts: This guide assumes familiarity with Terraform workspaces, backends, modules, and state files. Go to Terraform documentation to understand Terraform input types, variables, and backend configuration.
-
Terraform Apply step (optional): Typically, the Terraform Plan step is used with the Terraform Apply step. First, you add the Terraform Plan step and define the Terraform script. Next, you add the Terraform Apply step, select Inherit from Plan in Configuration Type, and reference the Terraform Plan step using the same Provisioner Identifier. Go to Provision with the Terraform Apply Step to configure the Apply step. Go to Provision Target Deployment Infra Dynamically with Terraform to provision target infrastructure for deployments.
Configure the Terraform Plan step
You can add the Terraform Plan step in two locations: in the stage's Infrastructure > Dynamic Provisioning section (when provisioning target infrastructure for deployment), or anywhere in the Execution steps (for ad-hoc planning).
When you add the Terraform Plan step in Dynamic Provisioning, you must use a Terraform Apply step to apply the plan. When you add it in Execution steps, you can use a Terraform Apply step but it is not required.
Set the step name
In Name, enter a name for the step, for example, plan.
The name is important because you can use it in expressions to refer to settings in this step.
For example, if the name of the stage is Terraform and the name of the step is plan, and you want to echo its timeout setting, you would use:
<+pipeline.stages.Terraform.spec.execution.steps.plan.timeout>
Set the timeout
In Timeout, enter how long Harness should wait to complete the Terraform Plan step before failing the step.
Enable remote workspace
Enable this option to identify whether the Terraform configuration uses a Terraform remote backend.
When enabled, you cannot provide the workspace input in Harness. The workspace will be outlined in your configuration for the remote backend.
The remote backend is supported only when the Configuration Type is Inline.
terraform {
backend "remote" {
hostname = "app.terraform.io"
organization = "your-organization"
workspaces {
name = "your-workspace"
}
}
}
Select the command
In Command, select Apply or Destroy.
Select Apply if you will use a Terraform Apply step later to apply the plan. Select Destroy if you will use a Terraform Destroy step later to remove resources.
- Apply: The plan will be applied by a Terraform Apply step later in your stage. Even though you are only running a Terraform plan in this step, you identify that this step can be used with a Terraform Apply step later.
- Destroy: The plan will be applied by a Terraform Destroy step later in your stage.
Set the Provisioner Identifier
The Provisioner Identifier is a unique label that links this Terraform Plan step to a Terraform Apply step or other Terraform steps like Rollback and Destroy.
Enter a unique value in Provisioner Identifier.
The most common use of Provisioner Identifier is between the Terraform Plan and Terraform Apply steps. For the Terraform Apply step, to apply the provisioning from the Terraform Plan step, you use the same Provisioner Identifier.
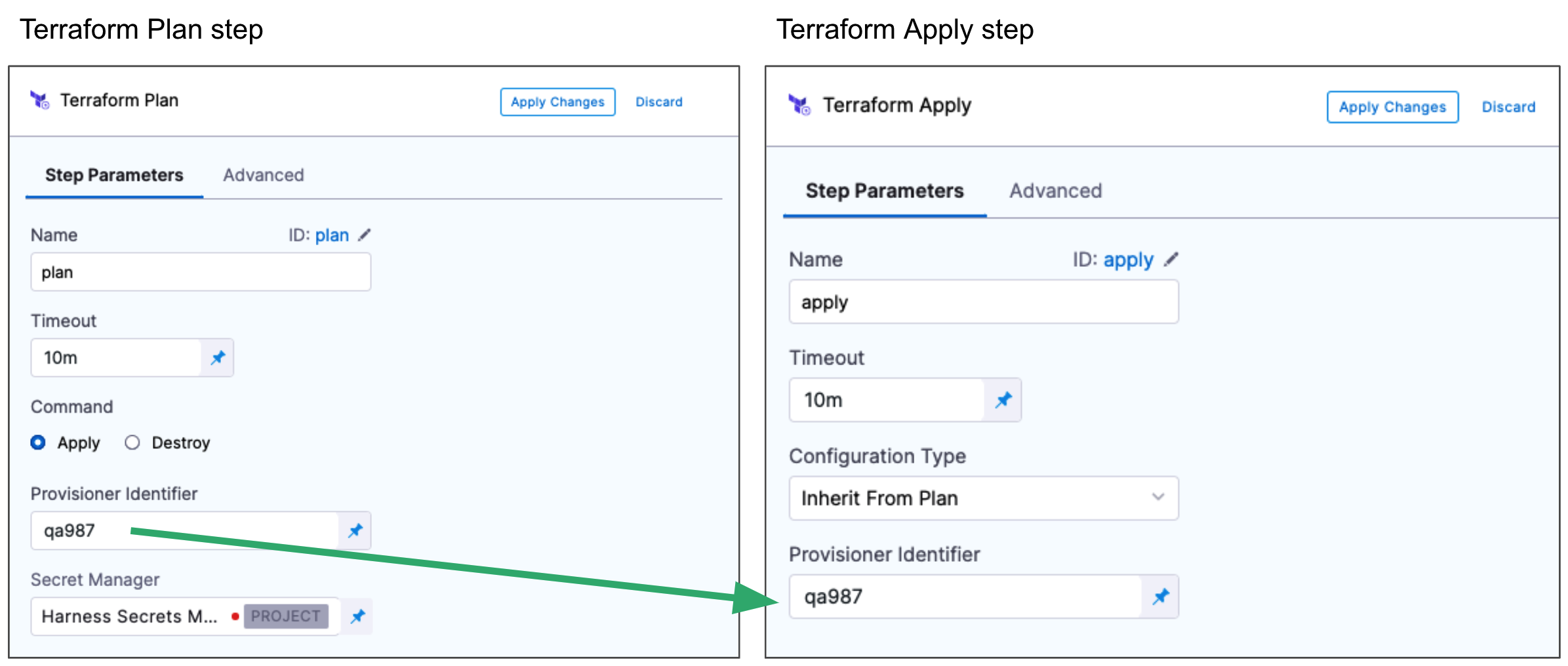
You also use the same Provisioner Identifier with the Terraform Destroy step to remove the provisioned resources.
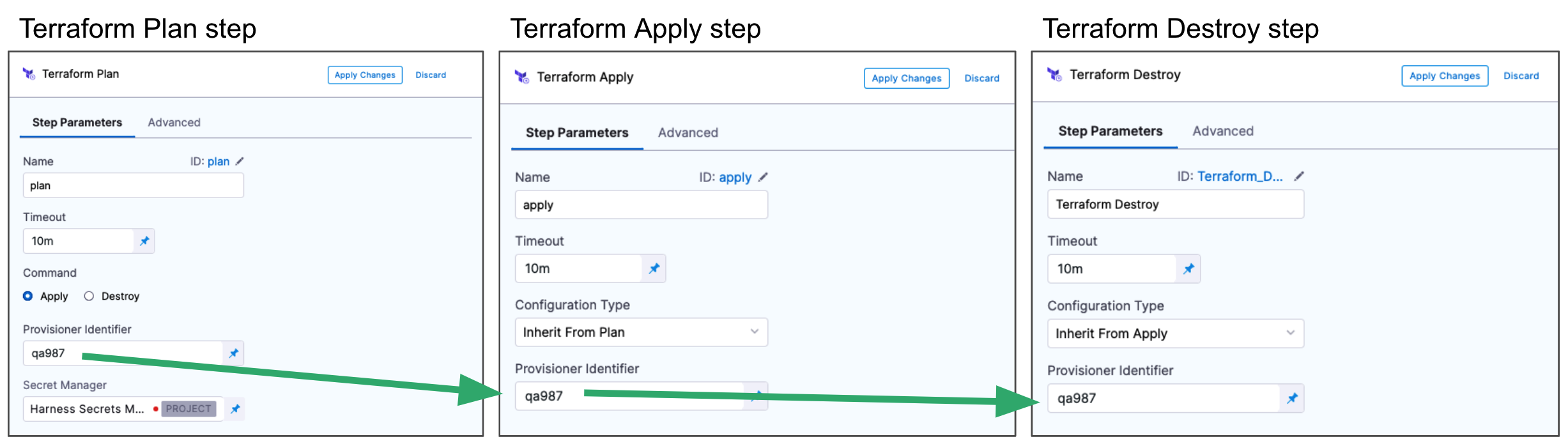
You also use the same Provisioner Identifier with the Terraform Rollback step to rollback the provisioned resources.
Provisioner Identifier Scope
The Provisioner Identifier is a Project-wide setting. You can reference it across Pipelines in the same Project.
For this reason, it is important that all your Project members know the Provisioner Identifiers. This will prevent one member building a Pipeline from accidentally impacting the provisioning of another member's Pipeline.
Select a Secret Manager
Terraform plans contain sensitive data. Harness encrypts the plan using a Secret Manager before storing it.
Select a Secrets Manager to use for encrypting/decrypting and saving the Terraform plan file.
Go to Harness Secrets Manager Overview to learn about Secret Managers.
A Terraform plan is a sensitive file that could be misused to alter resources if someone has access to it. Harness avoids this issue by never passing the Terraform plan file as plain text.
Harness only passes the Terraform plan between the Harness Manager and Delegate as an encrypted file using a Secrets Manager.
When the terraform plan command runs on the Harness Delegate, the Delegate encrypts the plan and saves it to the Secrets Manager you selected. The encrypted data is passed to the Harness Manager.
When the plan is applied, the Harness Manager passes the encrypted data to the Delegate.
The Delegate decrypts the encrypted plan and applies it using the terraform apply command.
Limitations
The Terraform plan size must not exceed the secret size limit for secrets in your default Harness secret manager. For example, the AWS secrets manager has a limitation of 64KB. Other supported secrets managers support larger file sizes, typically, 256KB.
Connect to your Terraform script repository
Configuration File Repository is where the Terraform script and files you want to use are located.
Here, you will add a connection to the Terraform script repo.
Click Specify Config File or edit icon.
The Terraform Config File Store settings appear.
Click the provider where your files are hosted.

Select or create a Connector for your repo. Go to Connect to a Git Repo to create a Git connector. Go to Artifactory Connector Settings Reference to configure Artifactory (see Artifactory with Terraform Scripts and Variable Definitions (.tfvars) Files).
For Git providers
In Git Fetch Type, select Latest from Branch or Specific Commit ID. When you run the Pipeline, Harness will fetch the script from the repo.
Specific Commit ID also supports Git tags. If you think the script might change often, you might want to use Specific Commit ID. For example, if you are going to be fetching the script multiple times in your Pipeline, Harness will fetch the script each time. If you select Latest from Branch and the branch changes between fetches, different scripts are run.
In Branch, enter the name of the branch to use.
In Folder Path, enter the path from the root of the repo to the folder containing the script.
For example, here is a Terraform script repo, the Harness Connector to the repo, and the Config Files settings for the branch and folder path:
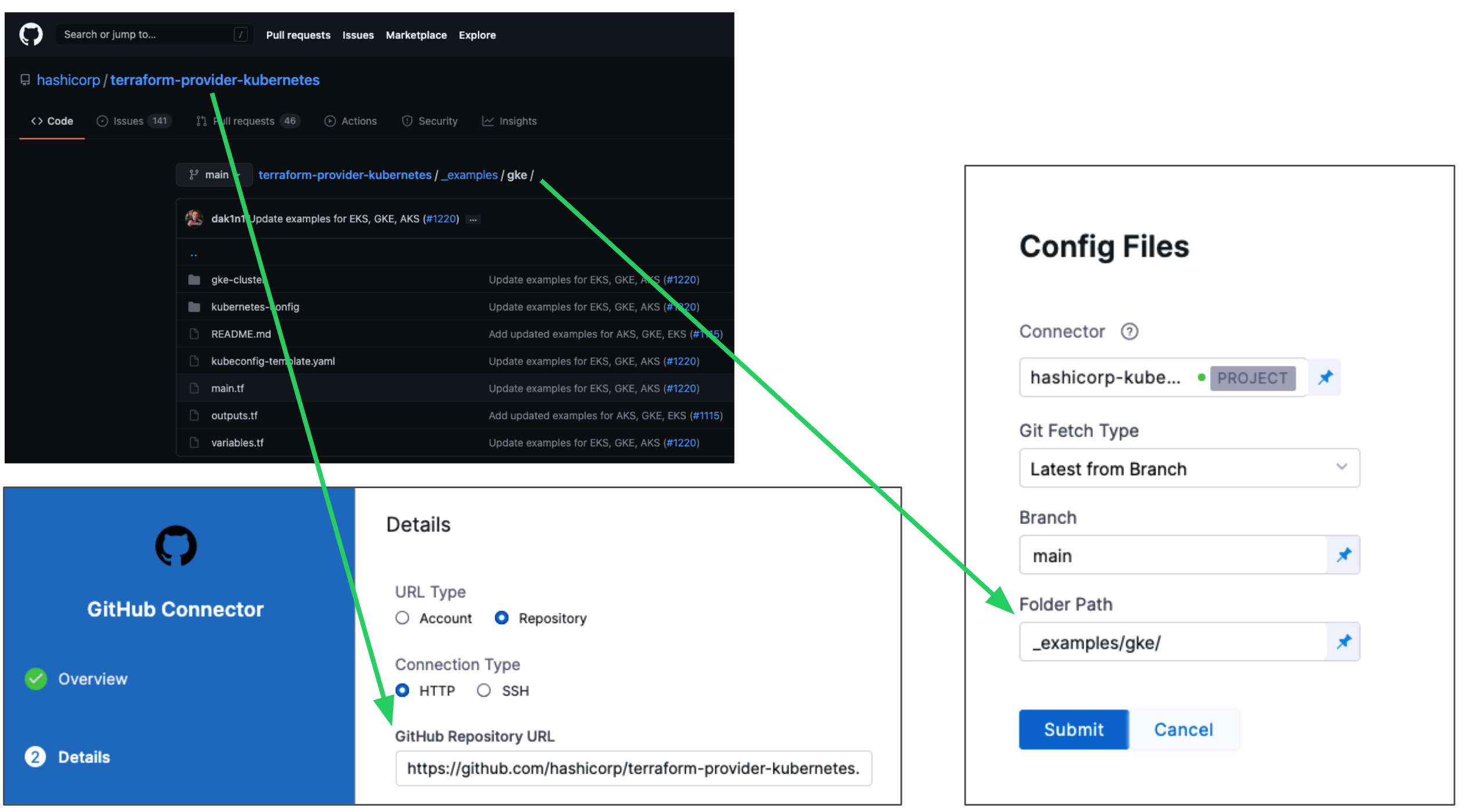
Click Submit.
Your Terraform Plan step is now ready. You can now configure a Terraform Apply, Destroy, or Rollback step that can use the Terraform script from this Terraform Plan step.
The following sections cover common Terraform Plan step options.
For Artifactory
Go to Artifactory Connector Settings Reference to configure Artifactory connectors (see Artifactory with Terraform Scripts and Variable Definitions (.tfvars) Files).
When working with Terraform in conjunction with Artifactory, ensure the following:
Paths in Variable Files:
Ensure that the paths specified in your configuration include the full path, including the repository name. For example, instead of specifying just variables.tf, specify the full path like repo_name/variables.tf to ensure accurate referencing.
File Archival:
The file should be archived into a .zip format before being uploaded to Artifactory. This ensures proper handling and file integrity when stored in the repository.
For AWS S3
-
In Region, select the region where your bucket is stored.
-
In Bucket, select the bucket where your Terraform files are stored (all buckets from the selected region that are available to the connector will be fetched).
-
In Folder Path, enter the path from the root of the repo to the folder containing the script.
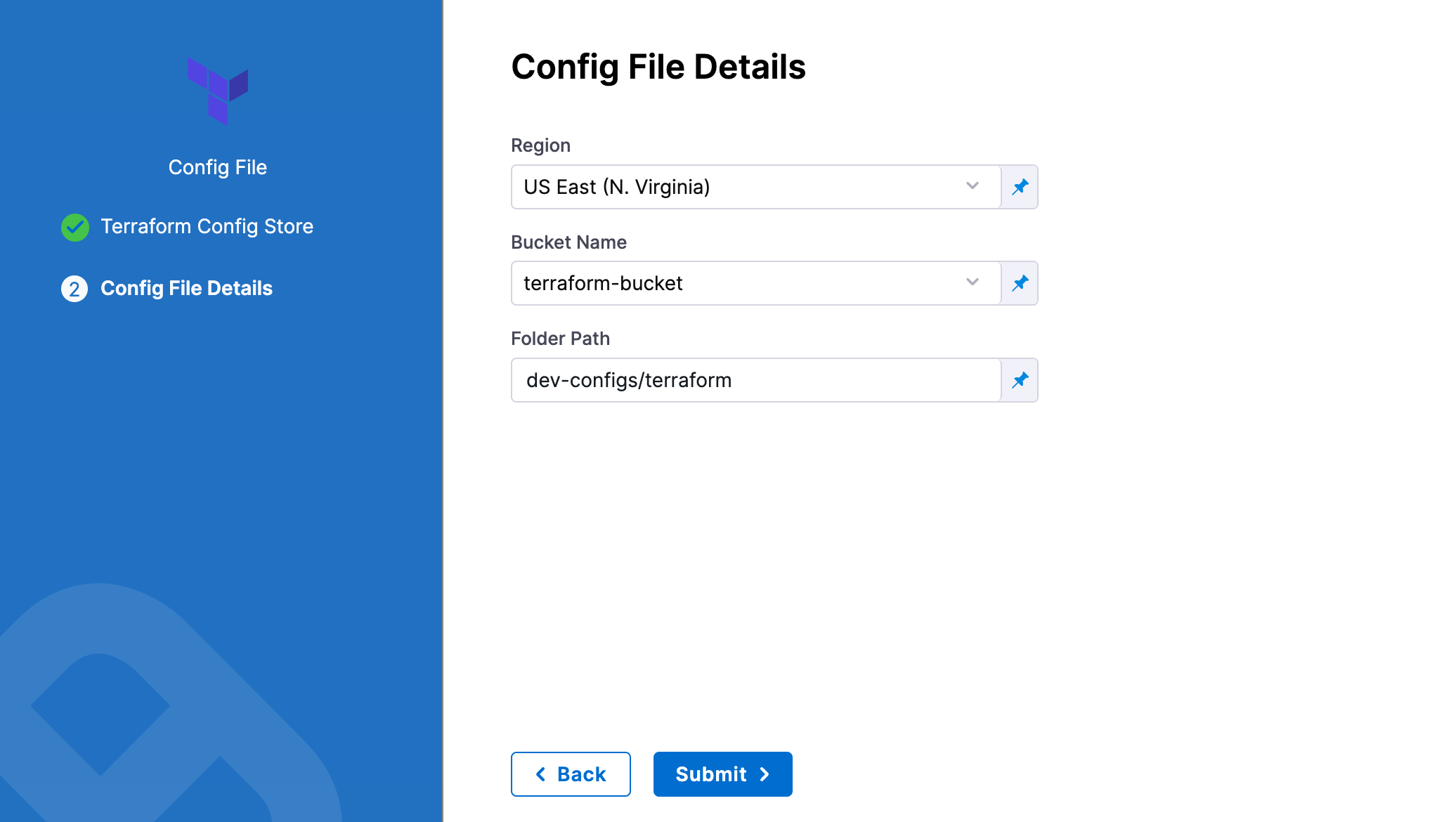
Harness will fetch all files from specified folder.
Configure module source credentials
When you set up the file repo in Configuration File Repository, you use a Harness Connector to connect to the repo where the Terraform scripts are located.
Some scripts will reference module sources in other repos and Harness will pull the source code for the desired child module at runtime (during terraform init).
In Source Module, you can select Use Connector credentials to have Harness use the credentials of the Connector to pull the source code for the desired child module(s).
If you do not select Use Connector credentials, Terraform will use the credentials that have been set up in the system.
The Use Connector credentials setting is available to Harness Git Connectors using SSH authentication or HTTPS.
When configuring the SSH key for the connector, exporting an SSH key with a passphrase for the module source is not supported. Configure an SSH Key without the passphrase.
Here is a syntax example to reference the Terraform module using the SSH protocol:
source = "git@github.com:your-username/your-private-module.git"
Here is a syntax example to reference the Terraform module using the HTTPS protocol:
source = "git::https://github.com/your-organization/your-private-module.git"
The ability to authenticate with HTTPS is new! The Minimum required delegate version is: 83401. Here is a demo on its functionality:
Configure workspace settings
A Terraform workspace is a separate instance of state data, allowing you to manage multiple environments (Dev, QA, Production) from the same Terraform configuration.
Harness supports Terraform workspaces. A Terraform workspace is a logical representation of one your infrastructures, such as Dev, QA, Stage, Production.
Workspaces are useful when testing changes before moving to a production infrastructure. To test the changes, you create separate workspaces for Dev and Production.
A workspace is really a different state file. Each workspace isolates its state from other workspaces. For more information, go to When to use Multiple Workspaces from Hashicorp.
Here is an example script where a local value names two workspaces, default and production, and associates different instance counts with each:
locals {
counts = {
"default"=1
"production"=3
}
}
resource "aws_instance" "my_service" {
ami="ami-7b4d7900"
instance_type="t2.micro"
count="${lookup(local.counts, terraform.workspace, 2)}"
tags {
Name = "${terraform.workspace}"
}
}
In the workspace interpolation sequence, you can see the count is assigned by applying it to the Terraform workspace variable (terraform.workspace) and that the tag is applied using the variable also.
Harness will pass the workspace name you provide to the terraform.workspace variable, thus determining the count. If you provide the name production, the count will be 3.
In the Workspace setting, you can simply select the name of the workspace to use.
You can also use a stage variable in Workspace.
Later, when the Pipeline is deployed, you specify the value for the stage variable and it is used in Workspace.
This allows you to specify a different workspace name each time the Pipeline is run.
You can even set a Harness Trigger where you can set the workspace name used in Workspace.
Configure connector credentials
You can use a connector to authenticate with the target cloud provider. This is an optional configuration that takes the connector reference. The Terraform step uses this connector to authenticate with the cloud provider targeted for infrastructure provisioning.
This connector configuration is available in the Terraform Plan step. It also appears in the Terraform Apply and Terraform Destroy steps when the Configuration Type is set to Inline.

AWS Connector
This feature requires Harness Delegate version 81202. This feature is available only to paid customers. Contact Harness Support to enable the feature.
You can use an AWS connector to have the Terraform Plan and Apply step assume a role to perform infrastructure provisioning. It is an optional configuration that takes the AWS connector, a region and Role ARN. The Terraform step uses these parameters to authenticate the AWS account targeted for infrastructure provisioning.
By default, AWS assumes the role session duration as 900 seconds. To increase the AWS role session duration, a built-in environment variable, HARNESS_AWS_ASSUME_ROLE_DURATION is introduced, which can be used to override the assume role session duration. HARNESS_AWS_ASSUME_ROLE_DURATION is designed for use in Terraform steps in the environment variable section. The value must be set in seconds. This new environment variable requires Harness Delegate version 82700.
When configured the optional configuration for AWS Connector these fields can be passed as a fixed value, runtime input, or an expression.
Sample YAML
- step:
type: TerraformApply
name: Apply
identifier: Apply
spec:
provisionerIdentifier: provision
configuration:
type: Inline
spec:
workspace: <+input>
configFiles: {}
providerCredential:
type: Aws
spec:
connectorRef: <+input>
region: <+input>
roleArn: <+input>
timeout: 10m
Terraform variable files
You can specify Terraform variables inline and fetch remote variable files during run time. For more information, go to Specify Terraform variables.
Artifactory
Go to Artifactory Connector Settings Reference to configure Artifactory connectors (see Artifactory with Terraform Scripts and Variable Definitions (.tfvars) Files).
AWS S3
-
In Identifier, enter an identifier, so you can refer to variables using expressions if needed.
-
In Region, select the region where your bucket is stored.
-
In Bucket, select the bucket where your Terraform var files are stored (all buckets from the selected region that are available to the connector will be fetched).
-
In File Paths, add one or more file paths from the root of the bucket to the variable file. Ensure the file is archived as a
.zip, and the file paths should include the full path, including the repo.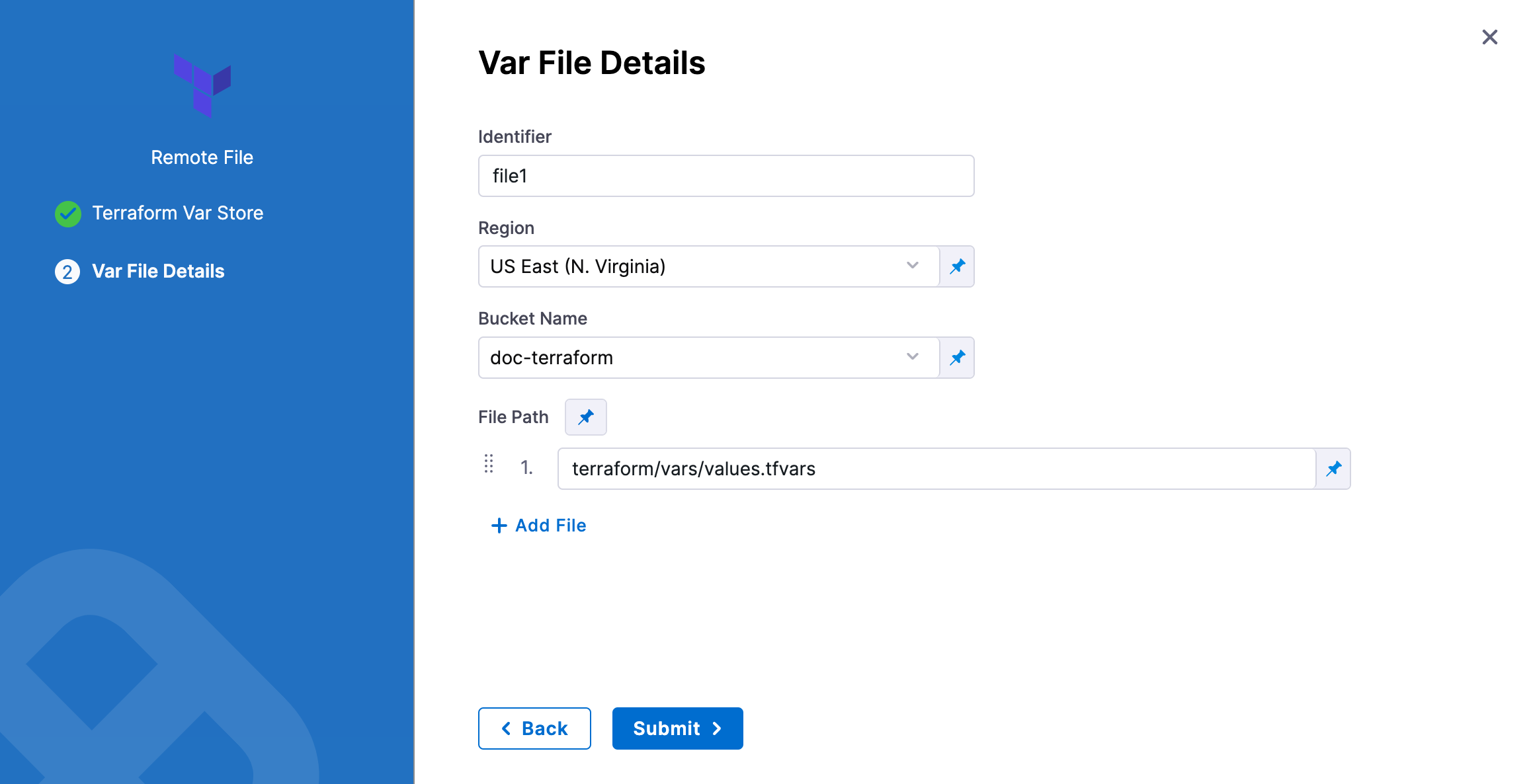
Click Submit. The remote file(s) are added.
Azure Connector
Harness Terraform steps now support authenticating with Azure using Azure connectors for target provisioning. This enables seamless integration with Azure infrastructure when running Terraform Plan, Apply, and Destroy steps with inline Terraform configuration.
Key Features
- Azure Connector support: Authenticate Terraform operations using Azure connectors configured in Harness.
- Authentication methods: Manual credentials, Delegate-based credentials, OIDC token-based authentication are supported. Certificate-based authentication is not supported yet.
- Additional options: Default configuration can be overridden with environment variables like ARM_TENANT_ID and ARM_MSI_ENDPOINT for advanced scenarios.
For more information on how to setup an Azure connector, go to Azure Connector Settings Reference.
YAML Configuration Example
Sample YAML
- step:
type: TerraformPlan
name: TerraformPlan_1
identifier: TerraformPlan_1
spec:
provisionerIdentifier: planoidc
configuration:
command: Apply
configFiles:
store:
spec:
connectorRef: githubConnector
repoName: play
gitFetchType: Branch
branch: main
folderPath: tf/azure
type: Github
providerCredential:
type: Azure
spec:
connectorRef: AzureConnector
subscriptionId: 20xxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
GCP Connector
This feature requires Harness Delegate version 88303 or later.
Harness Terraform steps support authenticating with Google Cloud Platform (GCP) using GCP connectors for target infrastructure provisioning. This enables seamless integration with GCP resources when running Terraform Plan, Apply, and Destroy steps with inline Terraform configuration.
For information on setting up a GCP connector, go to Connect to Google Cloud Platform (GCP).
Authentication Methods
GCP connectors support three authentication methods for Terraform steps:
Manual Credentials (ManualConfig)
Use this method to explicitly provide GCP service account credentials stored in Harness Secret Manager. The connector references a secret containing the GCP Service Account Key in JSON format. This approach gives you direct control over which credentials are used for provisioning.
Inherit From Delegate (InheritFromDelegate)
This method uses credentials from the delegate's IAM role, such as a GCE instance service account or GKE workload identity. At least one delegate selector must be specified for this configuration. This is ideal when your delegates already have appropriate GCP permissions attached.
OIDC Authentication (OidcAuthentication)
This method enables federated authentication using OpenID Connect for workload identity federation. It requires configuring a GCP Workload Identity Pool, an OIDC Provider, and a service account for impersonation. This is the recommended approach for production environments as it eliminates the need to manage long-lived credentials.
YAML Configuration Example
Sample YAML
- step:
type: TerraformPlan
name: TerraformPlan_1
identifier: TerraformPlan_1
spec:
provisionerIdentifier: gcp_terraform_provision
configuration:
command: Apply
configFiles:
store:
spec:
connectorRef: githubConnector
repoName: terraform-repo
gitFetchType: Branch
branch: main
folderPath: tf/gcp
type: Github
providerCredential:
type: Gcp
spec:
connectorRef: gcpOidcConnector
project: cd-play
timeout: 10m
GCP Connector Configuration Examples
Manual Credentials Connector
Use this configuration when you want to provide GCP service account credentials explicitly via Harness Secret Manager.
connector:
type: Gcp
spec:
credential:
type: ManualConfig
spec:
secretKeyRef: account.gcp_service_account_key
delegateSelectors:
- gcp-delegate
Inherit From Delegate Connector
Use this configuration when your delegate already has GCP credentials via IAM role (GCE instance service account or GKE workload identity).
connector:
type: Gcp
spec:
credential:
type: InheritFromDelegate
spec:
delegateSelectors:
- gcp-delegate-with-iam
OIDC Authentication Connector
Use this configuration for federated authentication using OpenID Connect workload identity federation.
connector:
type: Gcp
spec:
credential:
type: OidcAuthentication
spec:
workloadPoolId: projects/123456789/locations/global/workloadIdentityPools/harness-pool
providerId: harness-oidc-provider
gcpProjectId: my-gcp-project-id
serviceAccountEmail: harness-workload-identity@my-gcp-project-id.iam.gserviceaccount.com
Configure the backend
The Backend Configuration section contains the remote state values.
You can use an inline or remote state file.
Using a remote Backend Config File
- In Backend Configuration, select Remote.
- Click Specify Backend Config File
- Select your provider (GitHub, Artifactory, S3, etc.) and then select or create a Connector to the repo where the files are located. Typically, this is the same repo where your Terraform script is located, so you can use the same Connector.
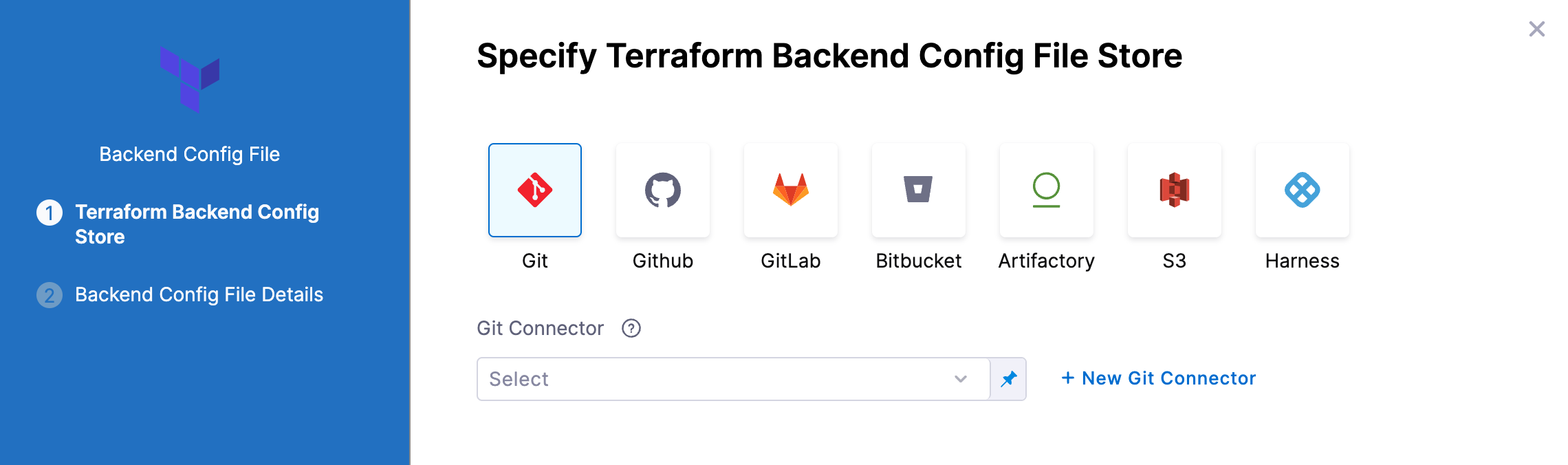
Git providers
-
In Git Fetch Type, select Latest from Branch or Specific Commit ID.
-
In Branch, enter the name of the branch.
-
In File Path, add file path from the root of the repo to the backend config file.
-
Click Submit. The remote file(s) are added.
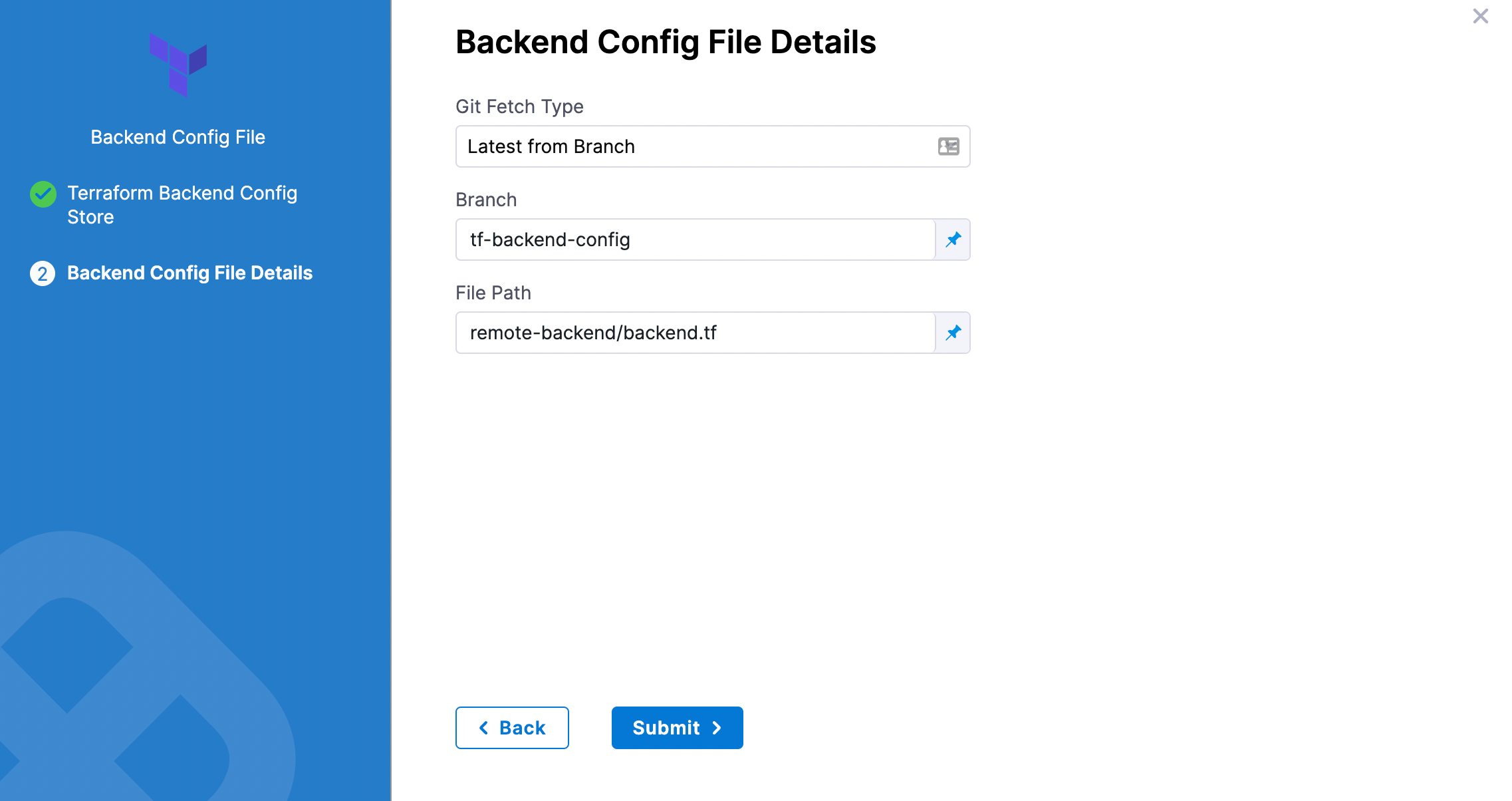
Artifactory
Go to Artifactory Connector Settings Reference to configure Artifactory connectors (see Artifactory with Terraform Scripts and Variable Definitions (.tfvars) Files).
AWS S3
-
In Region, select the region where your bucket is stored.
-
In Bucket, select the bucket where your backend config file is stored (all buckets from the selected region that are available to the connector will be fetched).
-
In File Path, add file path from the root of the bucket to the backend config file.
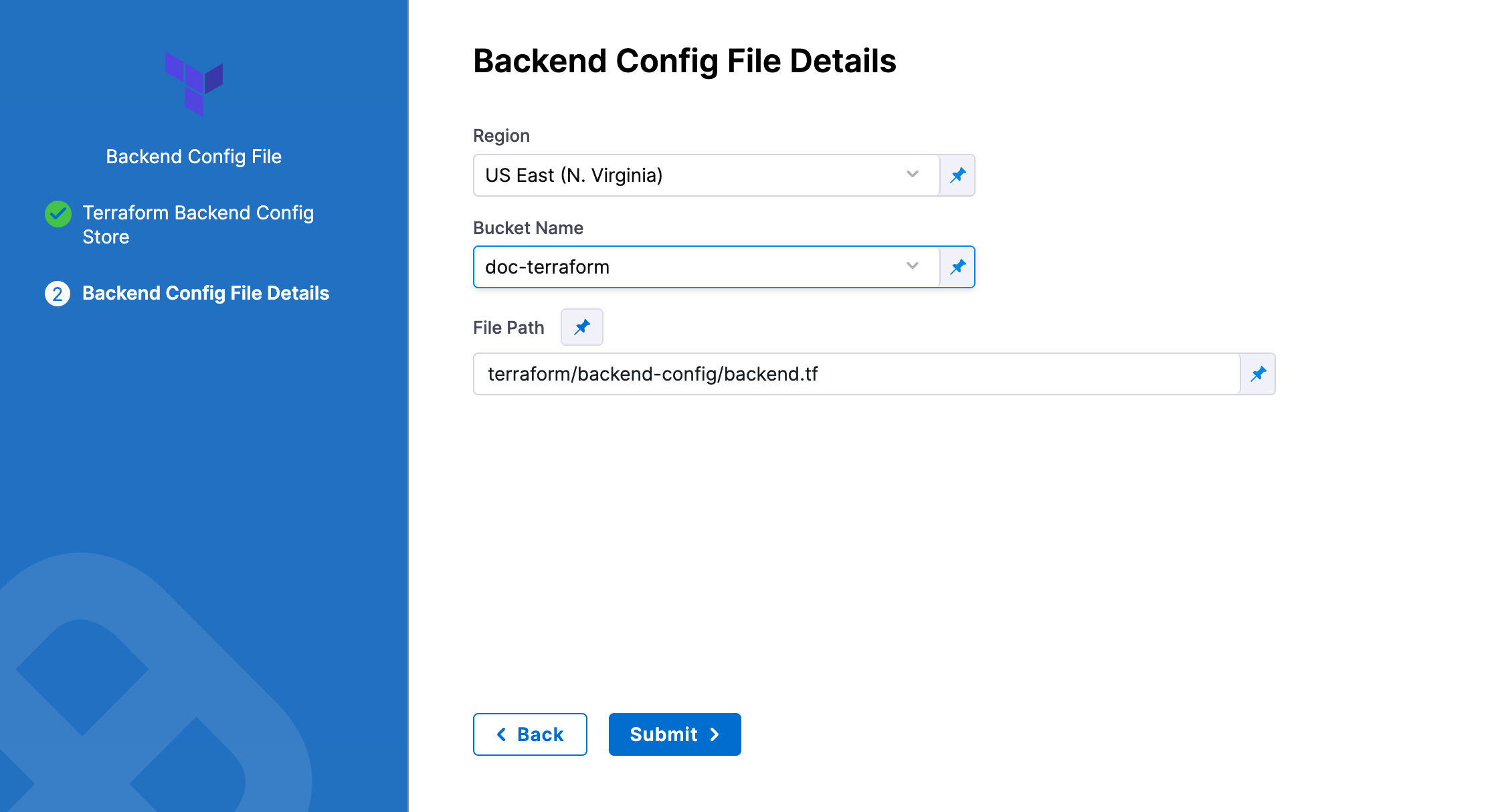
You can also use files in the Harness File Store.
To use the same remote state file set in the Terraform Plan step, Terraform Apply steps must use the same Provisioner Identifier.
For an example of how the config file should look, go to Backend Configuration from HashiCorp.
Here is an example.
main.tf (note the empty backend S3 block):
variable "global_access_key" {type="string"}
variable "global_secret_key" {type="string"}
variable "env" {
default= "test"
}
provider "aws" {
access_key = "${var.global_access_key}"
secret_key = "${var.global_secret_key}"
region = "us-east-1"
}
resource "aws_s3_bucket" "bucket" {
bucket = "prannoy-test-bucket"
}
terraform {
backend "s3" {
}
}
backend.tf:
access_key = "1234567890"
secret_key = "abcdefghij"
bucket = "terraform-backend-config-test"
key = "remotedemo.tfstate"
region = "us-east-1"
Using Inline State
Enter values for each backend config (remote state variable).
For example, if your config.tf file has the following backend:
terraform {
backend "gcs" {
bucket = "tf-state-prod"
prefix = "terraform/state"
}
}
In Backend Configuration, you provide the required configuration variables for the backend type.
For a remote backend configuration, the variables should be in .tfvars file.
Example:
bucket = "tf-state-prod"
prefix = "terraform/state"
In your Terraform .tf config file, only the definition of the Terraform backend is required:
terraform {
backend "gcs" {}
}
Go to Configuration variables in Terraform's gcs Standard Backend doc to understand backend configuration variables.
Specify Terraform targets
You can use the Targets setting to target one or more specific modules in your Terraform script, just like using the terraform plan -target command. Go to Resource Targeting from Terraform to understand resource targeting.
You simply identify the module using the standard format module.name, like you would using terraform plan -target="module.s3_bucket".
If you have multiple modules in your script and you do not select one in Targets, all modules are used.
Add environment variables
If your Terraform script uses environment variables, you can provide values for those variables here.
For example:
TF_LOG_PATH=./terraform.log
TF_VAR_alist='[1,2,3]'
You can use Harness encrypted text for values. Go to Add Text Secrets to create encrypted text secrets.
Export JSON representation of plan
Enable this setting to use a JSON representation of the Terraform plan that is implemented in a Terraform Plan step.
In subsequent Execution steps, such as a Shell Script step, you can reference the Terraform plan using this expression format:
<+execution.steps.[Terraform Plan step Id].plan.jsonFilePath>
For example, if you had a Terraform Plan step with the Id Plan_Step, you could use the expression in a Shell Script step like this:
cat "<+execution.steps.Plan_Step.plan.jsonFilePath>"
If the Terraform Plan step is located in Dynamic Provisioning steps in Infrastructure, and the Terraform Plan step Id is TfPlan, then expression is:
<+infrastructure.infrastructureDefinition.provisioner.steps.TfPlan.plan.jsonFilePath>
For information on Terraform Plan in the Dynamic Provisioning steps in Infrastructure, go to Provision Target Deployment Infra Dynamically with Terraform.
JSON representation of Terraform plan can be accessed across different stages as well. In this case, the FQN for the step is required in the expression.
For example, if the Terraform Plan step with the Id TfPlan is in the Execution steps of a stage with the Id TfStage, then the expression is like this:
<+pipeline.stages.TfStage.spec.execution.steps.TfPlan.plan.jsonFilePath>
When Terraform plan is present in a step group, then the expression to access jsonFilePath is like this:
<+pipeline.stages.[stage name].spec.execution.steps.[step group name].steps.[step name].plan.jsonFilePath>
When the Run on Remote Workspace option is selected, you will not be able to export the JSON representation of terraform plan.
Scope of Expression
JSON representation of the Terraform plan is available only between the Terraform Plan step and subsequent Terraform Apply step. The expression will fail to resolve if used after the Terraform Apply step.
If used across stages, the Terraform Plan step can be used in one stage and the Terraform Apply step can be used in a subsequent stage. The expression will resolve successfully in this case.
The JSON of the Terraform Plan step is not available after Rollback.
Export human-readable representation
Enable this option to view the Terraform plan file path and contents as human-readable JSON is subsequent steps, such as a Shell Script step.
Once you enable this option and run a CD stage with the Terraform Plan step, you can click in the Terraform Plan step's Output tab and copy the Output Value for the humanReadableFilePath output.
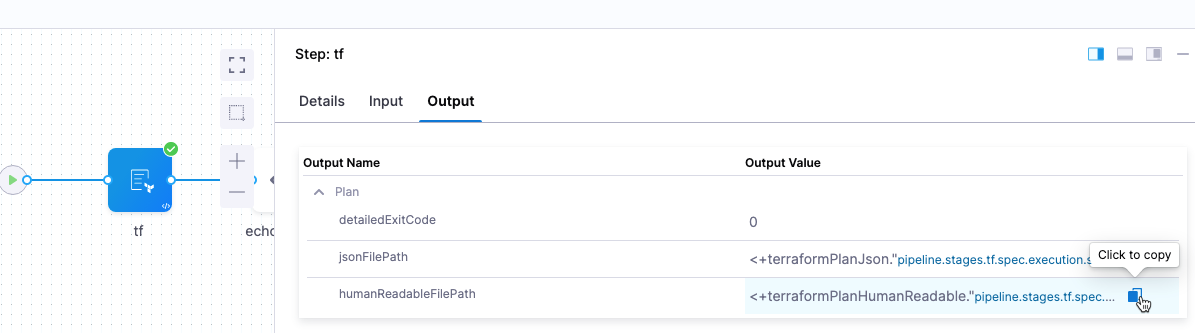
The format for the expression is:
- humanReadableFilePath:
<+terraformPlanHumanReadable."pipeline.stages.[stage Id].spec.execution.steps.[step Id].[Provisioner Identifier]_planHumanReadable">
For example, if the Terraform Plan stage, step Ids, and Terraform provisioner identifier are tf then you would get the following expressions:
- humanReadableFilePath:
<+terraformPlanHumanReadable."pipeline.stages.tf.spec.execution.steps.tf.tf_planHumanReadable">
Next, you can enter those expressions in a subsequent Shell Script step step and Harness will resolve them to the human-readable paths and JSON.
For example, here is a script using the variables:
echo "<+terraformPlanHumanReadable."pipeline.stages.tf.spec.execution.steps.tf.tf_planHumanReadable">"
echo "Plan is"
cat "<+terraformPlanHumanReadable."pipeline.stages.tf.spec.execution.steps.tf.tf_planHumanReadable">"
Note that if there are no changes in the plan, the standard Terraform message is shown in the Shell Step's logs:
No changes. Your infrastructure matches the configuration.
Terraform has compared your real infrastructure against your configuration
and found no differences, so no changes are needed.
Store plan on Harness Delegate
Use this option when your Secret Manager has file size limits or you want to avoid storing plans in Secret Manager. Warning: Plans are lost if the delegate pod restarts.
This setting requires Harness Delegate version 24.04.82705 or later.
Enable the Store terraform plan on delegate option on the Terraform Plan step to store the Terraform Plan on Harness Delegate temporarily. This is particularly useful if you do not want to save the Terraform Plan files on Secrets Manager or if there is a file size limit on Secrets Manager.
After you enable this option, select the Inherit From Plan option in the Apply Inherit or Destroy Inherit steps' Configuration Type field and enter the Provisioner Id used by the Terraform Plan step.
Important notes
- You must execute the Terraform Plan and Terraform Apply/Destroy steps on the same pod to be able to use the stored plan file. If your delegate has multiple pod replicas, make sure to Run the Terraform steps on the pod.
- Harness stores the Terraform Plan files at the
./tf-plan/directory inside the working directory (default path,/opt/harness-delegate/) of the delegate, i.e., the files are stored at,/opt/harness-delegate/./tf-plan/. - If the delegate pods are restarted, the Terraform plan files disappear from the location where they are stored. To not lose the Terraform plan files during the new delegate deployment rollout or restart, you have to set up a persistent volume and mount the directory where the Terraform plan files are stored. If your delegate has multiple pod replicas, you must set up a persistent volume with the access mode,
ReadWriteMany. Go to this example to learn how to set the persistent volume for Google GKE. - The Terraform plan file is cleaned up after the Terraform Apply/Destroy step is executed or after the pipeline execution is complete.
Here is a video demo of how to store Terraform Plan files on delegate:
Skip state storage
The following feature requires a minimum Harness Delegate version of 812xx.
While running Terraform commands on the delegate, Harness by default will try to detect if there is a local state file in the Terraform working directory.
If local state file is identified, at the end of the execution it is saved on Harness storage with a key based on the provisioner identifier.
That state file is downloaded in the Terraform working directory for subsequent executions, and the updated state is uploaded after execution ends.
This method allows the maintaining of the state of the infrastructure even if there is no Terraform backend configured.
This is more for testing purposes. For production environments, Harness advises you configure a backend in your Terraform config files. For information, go to Backend Configuration.
With the Skip state storage option enabled, Harness allows you to skip the local state upload and download operations mentioned above.
This option makes is useful only if you do not have a Terraform backed configured in your Terraform config files. If you have a Terraform backed configured, then the Terraform CLI will not create any local state files.
Create remote workspace with prefix
This option is available only on delegate version 86400 or later.
When using a remote backend with a workspace prefix, Terraform does not automatically create the workspace if it does not already exist. This can cause pipeline failures with errors like:
Error: Currently selected workspace "my-app-dev" does not exist
To address this, Harness provides the Create remote workspace with prefix option. When this option is enabled:
- If the remote workspace does not exist, Harness automatically creates it and continues the execution.
- If the remote workspace does exist, Harness exports it to the
TF_WORKSPACEenvironment variable so Terraform uses it. - If both the step configuration and environment variable specify a workspace, the step configuration takes precedence.
To enable automatic workspace selection when a workspace is configured in the step settings, this flag must be enabled.
If you prefer not to use this flag, you can manually configure the workspace using the TF_WORKSPACE environment variable.
Rollback does not delete workspaces created using this option. Workspace cleanup must be handled manually.
This is how the YAML would look like
- step:
type: TerraformPlan
name: TerraformPlan
identifier: TerraformPlan
timeout: 10m
spec:
provisionerIdentifier: <+input>
configuration:
command: Apply
configFiles: {}
secretManagerRef: <+input>
skipStateStorage: false
createRemoteWorkspaceWithPrefix: true
skipRefreshCommand: false
Add command line options
This setting allows you to set the Terraform CLI options for Terraform commands depending on the Terraform step type. For example: -lock=false, -lock-timeout=0s.
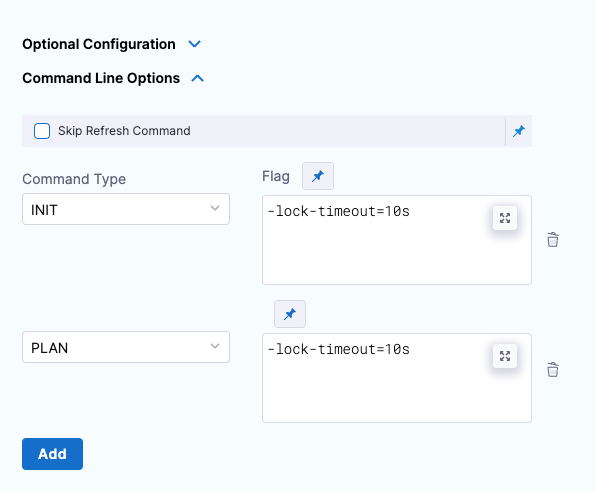
Skip Terraform refresh
Terraform refresh command will not be running when this setting is selected.
Use detailed exit code
You can use the standard terraform plan command option detailed-exitcode with the Harness Terraform Plan step.
If you use the -detailed-exitcode option in a step that follows the Harness Terraform Plan step, such as a Shell Script step, Harness will return a detailed exit code:
0: succeeded with empty diff (no changes)1: error2: succeeded with non-empty diff (changes present)|
Exit codes are available as Terraform Plan step outputs that can be accessed using expressions with the following format:
<+pipeline.stages.STAGE_ID.spec.execution.steps.STEP_ID.plan.detailedExitCode>
For example:
<+pipeline.stages.TfStage.spec.execution.steps.TfPlan.plan.detailedExitCode>
Understand working directory cleanup
Each Terraform step runs in a specific working directory on the delegate.
The Terraform working directory is located at /opt/harness-delegate/./terraform-working-dir/.
To that directory path, Harness adds additional directories that are named after the organization, account, project, and provisionerId (from the step) such that the final working directory is /opt/harness-delegate/./terraform-working-dir/org-name/account-name/project-name/provisionerId/.
In this final working directory, Harness stores the Terraform configuration and all fetched files such as var-files and backend-config.
Once the Terraform step execution is complete, Harness cleans up the main working directory /opt/harness-delegate/./terraform-working-dir/. This cleanup happens immediately after the step completes successfully or fails.
If you generate any local resources on the delegate in the directory where Terraform configurations are located, those resources are also removed. If you need those resources, make sure to generate them outside the Terraform working directory.
Configure advanced settings
In Advanced, you can use the following options:
Troubleshooting
Terraform Plan step fails with 'Provisioner Identifier not found' error in Harness CD
Ensure the Provisioner Identifier is unique within the project. If using with Terraform Apply, verify both steps use the exact same identifier (case-sensitive).
Terraform Plan step fails with Secret Manager encryption error
Verify the Secret Manager is configured correctly and the delegate can access it. Check that the Terraform plan size does not exceed the secret size limit (e.g., AWS Secrets Manager has a 64KB limit).
Terraform Plan step fails to fetch configuration files from Git repository
Verify the Git connector is configured correctly with valid credentials. Check the branch name and folder path are correct. For SSH authentication, ensure the SSH key has no passphrase.
Terraform Plan remote workspace does not exist error
Enable 'Create remote workspace with prefix' in the Terraform Plan step settings, or manually create the workspace in your Terraform Cloud/Enterprise instance before running the pipeline.
Terraform execution on a Docker delegate managed by ECS fails with NoCredentialProviders error
When your Docker delegate is managed by ECS and set to assume an IAM role, ensure the delegate has permissions to assume the role. If using a proxy, ensure the proxy instance also has permissions. Set HTTP_PROXY and HTTPS_PROXY environment variables in Terraform steps if needed.
Next steps
You have configured the Terraform Plan step to preview infrastructure changes in your CD pipeline. Harness will now execute your Terraform script and generate an encrypted plan that you can apply using a Terraform Apply step.