Test Intelligence™ step
Test Intelligence accelerates your test cycles without compromising quality, by running only the unit tests that are relevant to the code changes that triggered the build. Rather than running all test, all the time Instead of always running all unit tests, Harness automatically skips unneeded tests, speeding up your builds. You can also configure Harness TI to automatically split tests and run them in parallel.
You can use this Test Intelligence step, also known as the Test step, to run unit tests with Python, Ruby, Java , C# , Scala and Kotlin programming languages.
Test Intelligence for JavaScript (Jest) and Kotest is now available in beta. If you're interested in joining the beta program, please contact Harness Support or your account representative.
- The test step requires downloading the agent. This download is supported only over HTTPS. For customers running in SMP or air-gapped environments, Harness Platform must be configured with HTTPS enabled.
- Test Intelligence requires that the code is cloned into the default workspace directory,
/harness/. If the code is placed elsewhere, Test Intelligence will not function correctly. - To use TI for Python, the image for the step must have Python 3 installed and accessible. Additionally, Virtual Environments for Python (
venv) are not supported by TI.
Configure the Test step
Add the Test step to the Build stage in a CI pipeline.
- step:
type: Test
name: Intelligent Tests
identifier: test
spec:
command: mvn test # Required. All other settings are optional.
shell: sh # Optional shell type.
connectorRef: YOUR_IMAGE_REGISTRY_CONNECTOR # Container registry connector.
image: repo/image # Container image to use to run the commands.
privileged: false
intelligenceMode: true # Enable Test Intelligence.
globs: # Test glob pattern.
- "some/glob/pattern"
reports: # Test report path.
- "**/*.xml"
envVariables:
MAVEN_OPTS: "-Djansi.force=true"
Metadata
- Name: Enter a name summarizing the step's purpose. Harness automatically assigns an ID based on the Name.
- Description: Optional text string describing the step's purpose.
Container Registry and Image
The build environment must have the necessary binaries for the Test step to execute your test commands. Depending on the stage's build infrastructure, Test steps can use binaries that exist in the build environment, or use Container Registry and Image to pull an image, such as a public or private Docker image, that contains the required binaries.
When are Container Registry and Image required?
The stage's build infrastructure determines whether these fields are required or optional:
- Kubernetes cluster build infrastructure: Container Registry and Image are always required.
- Local runner build infrastructure: Test steps can use binaries available on the host machine. The Container Registry and Image are required if the machine doesn't have the binaries you need.
- Self-managed AWS/GCP/Azure VM build infrastructure: Test steps can use binaries that you've made available on your build VMs. The Container Registry and Image are required if the VM doesn't have the necessary binaries. These fields are located under Additional Configuration for stages that use self-managed VM build infrastructure.
- Harness Cloud build infrastructure: Test steps can use binaries available on Harness Cloud machines, as described in the image specifications. The Container Registry and Image are required if the machine doesn't have the binaries you need. These fields are located under Additional Configuration for stages that use Harness Cloud build infrastructure.
What are the expected values for Container Registry and Image?
For Container Registry, provide a Harness container registry connector, such as a Docker connector, that connects to the container registry where the Image is located.
For Image, provide the FQN (fully-qualified name) or artifact name and tag of a Docker image that has the binaries necessary to run the commands in this step, such as maven:3.8-jdk-11. If you don't include a tag, Harness uses the latest tag.
You can use any Docker image from any Docker registry, including Docker images from private registries. Different container registries require different name formats:
- Docker Registry: Enter the name of the artifact you want to deploy, such as
library/tomcat. Wildcards aren't supported. FQN is required for images in private container registries. - ECR: Enter the FQN of the artifact you want to deploy. Images in repos must reference a path, for example:
40000005317.dkr.ecr.us-east-1.amazonaws.com/todolist:0.2. - GCR: Enter the FQN of the artifact you want to deploy. Images in repos must reference a path starting with the project ID that the artifact is in, for example:
us.gcr.io/playground-243019/quickstart-image:latest.
Command and Shell
Use these fields to define the commands that you need to run in this step.
For Shell, select the shell type. If the step includes commands that aren't supported for the selected shell type, the step fails. Required binaries must be available on the build infrastructure or through a specified Container Registry and Image. The default shell type, if unspecified, is Sh.
In the Command field, enter commands for this step. The script is invoked as if it were the entry point. If the step runs in a container, the commands are executed inside the container.
Harness uses a built-in environment variable named JAVA_TOOL_OPTIONS.
You can append additional settings to this value, but do not override the default value.
Incremental builds don't work for Bazel if you give the entire repo in the Command. All modules are built for Bazel.
For C# support, Harness uses a built-in environment variable named CORECLR_PROFILER.
You shouldn't override this variable.
Intelligence Mode
Enable Intelligence Mode to enable Test Intelligence.
Test Globs
Specify a glob pattern to match the test files you want to include.
By default, we use the following globs for test selection:
- Ruby:
**/spec/**/*_spec.rb - Python:
"**/test_*.py,**/*_test.py" - Java:
**/*.java - C#:
**/*.cs
You can override the default test globs pattern, for example:
The default for RSpec is **/spec/**/*_spec.rb, and you could override it with any other pattern, such as spec/features/**/*_spec.rb, which would look for a /spec directory at the root level, rather than anywhere in the workspace.
Since test selection is at the file-level, the test globs pattern references file names. You can include directory structures, such as microservice1/**/test_*.py.
Report Paths
This setting is optional. If unspecified, Harness uses the default JUnit report path **/*.xml or **/*.trx for C#.
You can use this setting if your test reports are stored in a non-default location or have a non-default name pattern.
For example:
- step:
type: Test
name: Intelligent Tests
identifier: test
spec:
...
reports:
- tmp/junit.xml
You can add multiple paths. If you specify multiple paths, make sure the files contain unique tests to avoid duplicates. Glob is supported. Test results must be in JUnit XML format.
When using .Net, make sure to enable log reporting when running the tests, e.g. dotnet test -l:trx, or otherwise no tests would be shown in the Tests tab.
Output Variables
Output variables expose values for use by other steps or stages in the pipeline.
YAML example: Output variable
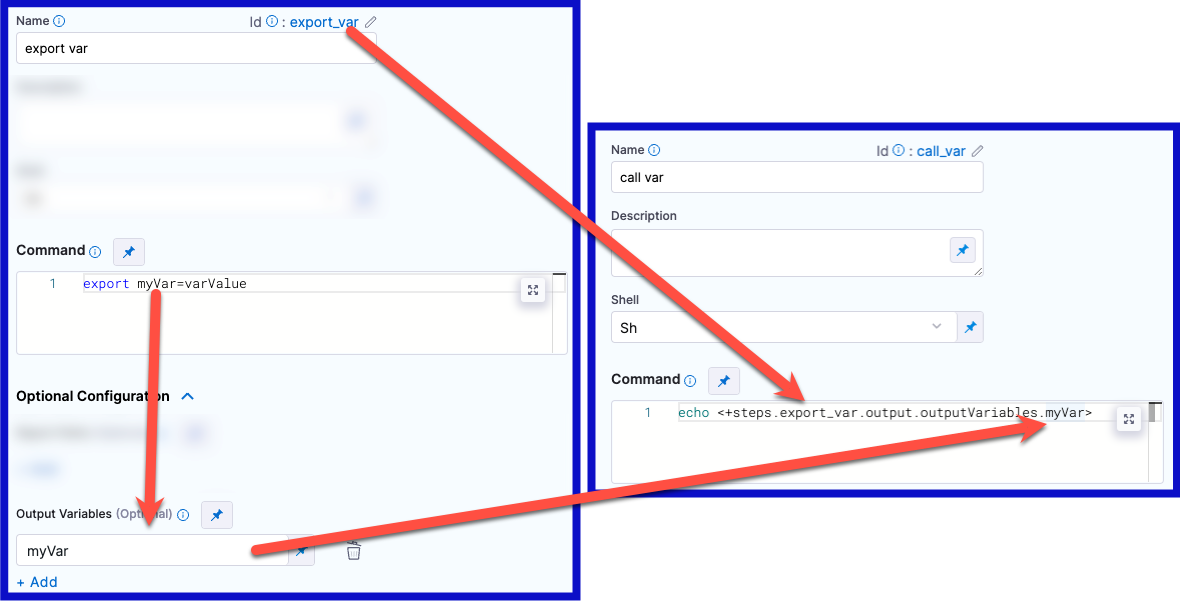
In the following YAML example, step alpha exports an output variable called myVar, and then step beta references that output variable.
- step:
type: Run
name: alpha
identifier: alpha
spec:
shell: Sh
command: export myVar=varValue
outputVariables:
- name: myVar
- step:
type: Run
name: beta
identifier: beta
spec:
shell: Sh
command: |-
echo <+steps.alpha.output.outputVariables.myVar>
echo <+execution.steps.alpha.output.outputVariables.myVar>
- Secrets in output variables exposed in logs: If an output variable value contains a secret, be aware that the secret will be visible in the build details. Such secrets are visible on the Output tab of the step where the output variable originates and in the build logs for any later steps that reference that variable. For information about best practices for using secrets in pipelines, go to the Secrets documentation.
- 64KB length limit: If an output variable's length is greater than 64KB, steps can fail or truncate the output. If you need to export large amounts of data, consider uploading artifacts or exporting artifacts by email.
- Single line limit: By default, output variables are limited to a single line. To enable multi-line output variables, use the feature flag
CI_ENABLE_MULTILINE_OUTPUTS_SECRETS. To export multi-line data, you can also consider uploading artifacts or exporting artifacts by email. - Exit Codes: In the event that an exit code is defined and set in the script, the output variables will not be available as an output from the step because it is a "forced" exit. The output from the step will be empty which can be desired depending on the situation.
This includes
exit 0definitions. Therefore, customers should not define an exit 0 situation, as "completing the script" to the end is what is expected as a "healthy" completion of the script.
Create an output variable
To create an output variable, do the following in the step where the output variable originates:
-
In the Command field, export the output variable. For example, the following command exports a variable called
myVarwith a value ofvarValue:export myVar=varValue -
In the step's Output Variables, declare the variable name, such as
myVar.
Reference an output variable
To reference an output variable in a later step or stage in the same pipeline, use a variable expression that includes the originating step's ID and the variable's name.
Use either of the following expressions to reference an output variable in another step in the same stage:
<+steps.[stepID].output.outputVariables.[varName]>
<+execution.steps.[stepID].output.outputVariables.[varName]>
To reference an output variable in a stage other than the one where the output variable originated, use either of the following expressions:
<+stages.[stageID].spec.execution.steps.[stepID].output.outputVariables.[varName]>
<+pipeline.stages.[stageID].spec.execution.steps.[stepID].output.outputVariables.[varName]>
Early access feature: Secret type selection
Currently, this early access feature is behind the feature flag CI_ENABLE_OUTPUT_SECRETS. Contact Harness Support to enable the feature.
You can enable type selection for output variables in Run steps.

If you select the Secret type, Harness treats the output variable value as a secret and applies secrets masking where applicable.
Early access feature: Output variables as environment variables
Currently, this early access feature is behind the feature flag CI_OUTPUT_VARIABLES_AS_ENV. Contact Harness Support to enable the feature.
With this feature flag enabled, output variables from steps are automatically available as environment variables for other steps in the same Build (CI) stage. This means that, if you have a Build stage with three steps, an output variable produced from step one is automatically available as an environment variable for steps two and three.
In other steps in the same stage, you can refer to the output variable by its key without additional identification. For example, an output variable called MY_VAR can be referenced later as simply $MY_VAR. Without this feature flag enabled, you must use an expression to reference the output variable, such as <+steps.stepID.output.outputVariables.MY_VAR>.
With or without this feature flag, you must use an expression when referencing output variables across stages, for example:
name: <+stages.[stageID].spec.execution.steps.[stepID].output.outputVariables.[varName]>
name: <+pipeline.stages.[stageID].spec.execution.steps.[stepID].output.outputVariables.[varName]>
YAML examples: Referencing output variables
In the following YAML example, a step called alpha exports an output variable called myVar, and then a step called beta references that output variable. Both steps are in the same stage.
- step:
type: Run
name: alpha
identifier: alpha
spec:
shell: Sh
command: export myVar=varValue
outputVariables:
- name: myVar
- step:
type: Run
name: beta
identifier: beta
spec:
shell: Sh
command: |-
echo $myVar
The following YAML example has two stages. In the first stage, a step called alpha exports an output variable called myVar, and then, in the second stage, a step called beta references that output variable.
- stage:
name: stage1
identifier: stage1
type: CI
spec:
...
execution:
steps:
- step:
type: Run
name: alpha
identifier: alpha
spec:
shell: Sh
command: export myVar=varValue
outputVariables:
- name: myVar
- stage:
name: stage2
identifier: stage2
type: CI
spec:
...
execution:
steps:
- step:
type: Run
name: beta
identifier: beta
spec:
shell: Sh
command: |-
echo <+stages.stage1.spec.execution.steps.alpha.output.outputVariables.myVar>
If multiple variables have the same name, variables are chosen according to the following hierarchy:
- Environment variables defined in the current step
- Output variables from previous steps
- Stage variables
- Pipeline variables
This means that Harness looks for the referenced variable within the current step, then it looks at previous steps in the same stage, and then checks the stage variables, and, finally, it checks the pipeline variables. It stops when it finds a match.
If multiple output variables from previous steps have the same name, the last-produced variable takes priority. For example, assume a stage has three steps, and steps one and two both produce output variables called NAME. If step three calls NAME, the value of NAME from step two is pulled into step three because that is last-produced instance of the NAME variable.
For stages that use looping strategies, particularly parallelism, the last-produced instance of a variable can differ between runs. Depending on how quickly the parallel steps execute during each run, the last step to finish might not always be the same.
To avoid conflicts with same-name variables, either make sure your variables have unique names or use an expression to specify a particular instance of a variable, for example:
name: <+steps.stepID.output.outputVariables.MY_VAR>
name: <+execution.steps.stepGroupID.steps.stepID.output.outputVariables.MY_VAR>
YAML examples: Variables with the same name
In the following YAML example, step alpha and zeta both export output variables called myVar. When the last step, beta, references myVar, it gets the value assigned in zeta because that was the most recent instance of myVar.
- step:
type: Run
name: alpha
identifier: alpha
spec:
shell: Sh
command: export myVar=varValue1
outputVariables:
- name: myVar
- step:
type: Run
name: zeta
identifier: zeta
spec:
shell: Sh
command: export myVar=varValue2
outputVariables:
- name: myVar
- step:
type: Run
name: beta
identifier: beta
spec:
shell: Sh
command: |-
echo $myVar
The following YAML example is the same as the previous example except that step beta uses an expression to call the value of myVar from step alpha.
- step:
type: Run
name: alpha
identifier: alpha
spec:
shell: Sh
command: export myVar=varValue1
outputVariables:
- name: myVar
- step:
type: Run
name: zeta
identifier: zeta
spec:
shell: Sh
command: export myVar=varValue2
outputVariables:
- name: myVar
- step:
type: Run
name: beta
identifier: beta
spec:
shell: Sh
command: |-
echo <+steps.alpha.output.outputVariables.myVar>
Early access feature: Multi-line Output Variables
- Multiline Output Variables: CI steps support multiline output variables, including special characters such as
\n,\t,\r,\b, maintaining shell-like behavior. - Complete Output Support: Output variables support both output secrets and output strings.
- JSON Preservation: JSON data can be passed as-is without automatic minification.
- Increased Output Variable Capacity: The maximum output variable size is approximately 131,072 characters, up from 65,536.
Technical Limitations
- The maximum size of output variables is constrained by the operating system's
ARG_MAXparameter, which limits command line arguments and environment variables. - Exceeding this limit will result in the error:
fork/exec /bin/sh: argument list too long
- This limitation is imposed by the operating system, not by the implementation of this feature.
Behavior Changes: Current vs. New
The following table outlines changes in how special characters are handled in output variables:
| Command | Current Behavior | New Behavior |
|---|---|---|
export out="\b" | "\b" | Backspace |
export out="\f" | "\f" | Form feed |
export out="\n" | "\n" | Newline character |
export out="\r" | "\r" | Carriage return |
export out="\t" | "\t" | Tab character |
export out="\v" | "\v" | Vertical tab |
Best Practices
Python Shell
For multiline strings in Python, use triple quotes (""" or ''') to maintain formatting properly.
Step 1: Export an output variable:
out = """line1,
line2,
line3"""
os.environ["out"] = out
Step 2: Read the output variable:
str_value = """<+execution.steps.Step_name.output.outputVariables.out>"""
PowerShell
For PowerShell, use the @"..."@ syntax to handle multiline strings effectively.
Step 1: Export an output variable:
$out=@"
line1,
line2,
line3
"@
$env:out = $out
Step 2: Read the output variable:
$str_value = @"
<+execution.steps.Step_name.output.outputVariables.out>
"@
These best practices ensure proper handling of multiline strings across different environments while maintaining consistency in CI workflows.
Environment Variables
You can inject environment variables into the step container and use them in the step's commands. You must input a Name and Value for each variable.
You can reference environment variables in the Command by name, such as $var_name.
Variable values can be fixed values, runtime inputs, or expressions. For example, if the value type is expression, you can input a value that references the value of some other setting in the stage or pipeline.
Stage variables are inherently available to steps as environment variables.
Parallelism (Test Splitting)
To enable parallelism (test splitting) in a Test step, specify the number of parallel workloads to divide the tests into. These workloades will be executed in parallel steps.
When using tests splitting, Intelligence Mode must be enabled.
The Test step does not support the matrix looping strategy. Using the Test step inside a matrix produces undefined behavior and is not a supported configuration.
If you need matrix looping to run different services or modules in parallel, use the Run step instead.
For example:
- step:
type: Test
name: Intelligent Tests
identifier: test
spec:
...
parallelism : 4 # Divide tests into 4 parallel workloads executed by 4 steps.
Additional container settings
Settings specific to containers are not applicable in a stages that use VM or Harness Cloud build infrastructure.
Image Pull Policy
If you specified a Container Registry and Image, you can specify an image pull policy:
- Always: The kubelet queries the container image registry to resolve the name to an image digest every time the kubelet launches a container. If the kubelet encounters an exact digest cached locally, it uses its cached image; otherwise, the kubelet downloads (pulls) the image with the resolved digest, and uses that image to launch the container.
- If Not Present: The image is pulled only if it isn't already present locally.
- Never: The image is not pulled.
Run as User
If you specified a Container Registry and Image, you can specify the user ID to use for running processes in containerized steps.
For a Kubernetes cluster build infrastructure, the step uses this user ID to run all processes in the pod. For more information, go to Set the security context for a pod.
Privileged
For container-based build infrastructures, you can enable this option to run the container with escalated privileges. This is equivalent to running a container with the Docker --privileged flag.
Set Container Resources
These settings specify the maximum resources used by the container at runtime. These setting are only available for container-based build infrastructures, such as a Kubernetes cluster build infrastructure.
- Limit Memory: The maximum memory that the container can use. You can express memory as a plain integer or as a fixed-point number using the suffixes
GorM. You can also use the power-of-two equivalentsGiandMi. The default is500Mi. - Limit CPU: The maximum number of cores that the container can use. CPU limits are measured in CPU units. Fractional requests are allowed. For example, you can specify one hundred millicpu as
0.1or100m. The default is400m. For more information go to Resource units in Kubernetes.
Timeout
You can set the step's timeout limit. Once the timeout is reached, the step fails and pipeline execution proceeds according to any Step Failure Strategy settings or Step Skip Condition settings.
Compatibility
The following are the languages, OSes & versions that are supported by Harness' Test Intelligence:
- Java
- Ruby
- Python
- C#
- JavaScript (Beta)
Supported Operating Systems
All cloud available versions of Linux, Windows & Mac are supported.
| Language | Minimum Version |
|---|---|
| Java | 8+ |
| Kotlin | 1.5+ |
| Scala | 2.13+ |
| Build Tool | Minimum Version | Maximum Version | Comments |
|---|---|---|---|
| Gradle | 7.x+ | 9.0.2 | |
| Maven | 3.6.x+ | 3.9.x | |
| Bazel | 7.x+ | 8.x |
Supported Operating Systems
All cloud available versions of Linux, Windows & Mac are supported.
| Language | Minimum Version |
|---|---|
| Ruby | 2.7+ |
| Test Framework | Minimum Version | Maximum Version | Comments |
|---|---|---|---|
| RSpec | 7.x+ | 8.x |
Supported Operating Systems
All cloud available versions of Linux, Windows & Mac are supported.
| Language | Minimum Version |
|---|---|
| Python | 3.8+ |
| Test Framework | Minimum Version | Maximum Version | Comments |
|---|---|---|---|
| Pytest | 8.0+ | 9.0.2 | Supports pytest-xdist 3.6.1+ and pytest-cov 7+ |
Care needs to be taken when using virtual environments. Test Intelligence does support virtual environments through the use of environment variables such as PYTEST_PLUGINS and PYTHON_PATH so make sure not to override them. There might be cases where this integration would not work smoothly and test selection might not work, so please contact Harness Support or your account representative.
| Operating System | Supported Versions | Architectures |
|---|---|---|
| Linux/Centos | 8+ | AMD64 |
| Linux/RedHat | 9+ | AMD64 & ARM64 |
| Linux/Debian | 12+ | AMD64 & ARM64 |
| Linux/Suse | 15.5+ | AMD64 & ARM64 |
| Linux/Ubuntu | 20.04+ | AMD64 & ARM64 |
| Alpine | 3.17+ | AMD64 & ARM64 |
| Windows | TBD | AMD64 |
| Implementation | Minimum Version |
|---|---|
| .Net Core | 6+ |
| .Net Framework | TBD |
Test Intelligence for JavaScript (Jest) is available in beta. If you're interested in joining the beta program, please contact Harness Support or your account representative.
Supported Operating Systems
All cloud available versions of Linux & Windows are supported.
| Language | Minimum Version | Maximum Version |
|---|---|---|
| JavaScript | ES2017 | ES2024 |
| Typescript | v4.x+ | v5.x |
| Engine | Minimum Version | Maximum Version |
|---|---|---|
| Node.JS | v18.x+ | v24.x |
| Test Framework | Minimum Version | Maximum Version | Comments |
|---|---|---|---|
| Jest | 26.x+ | 30.x |
Care needs to be taken when using Babel.JS or Jest transformers as they might interfere with the way Test Intelligence is working.
Trigger Test Selection
Test Intelligence (TI) uses a baseline call graph to determine which tests to run. The process to establish this baseline differs for branch runs and pull request (PR) runs.
For Branch Runs (Manual or Triggered by Push)
Branch runs do not require webhook triggers.
Required Steps:
- Push changes to the branch, or manually run the pipeline from the UI.
- Select Git Branch as the build type and enter the branch name.
- Wait for the build to complete. This run establishes the baseline.
- Push further changes to the same branch and rerun the pipeline.
- TI will apply test selection based on code differences from the baseline.
This method works regardless of whether the pipeline is triggered manually or automatically. Triggers are optional for branch-based runs.
For Pull Request (PR) Runs
For PR-based pipelines, webhook triggers are required to make TI function correctly. Specifically:
- A trigger for the PR Opened event is needed to capture the initial call graph.
- A trigger for the PR Closed (Merged) event is required so that the platform can finalize the baseline. The merge event does not need to start a pipeline execution; it just needs to emit the event.
Required Steps:
- Create a webhook trigger that listens for:
- Pull Request Opened
- Pull Request Closed (Merged)
- Open a PR against the target branch. The PR trigger should automatically start a pipeline run using Git Pull Request as the build type.
- Merge the PR. The trigger listening for PR merge must fire. This event is used by Harness in the background to finalize the baseline for that branch. It does not need to execute any stage or pipeline.
- Once the baseline is established, new PRs targeting the same base branch will apply test selection during their pipeline runs.
- If a new PR is created against a different base branch, you must repeat steps 2 and 3 to establish a new baseline for that branch.
Test selection will not apply to PRs unless the close/merge event trigger has fired for that base branch.
Why do I have to run the pipeline twice?
The first time you run a pipeline after adding the Run Test step, Harness creates a baseline for test selection in future builds. Test selection isn't applied to this run because Harness has no baseline against which to compare changes and select tests. You'll start seeing test selection and time savings on the second run after you have added the Test step.
Ignore tests or files
If you want Test Intelligence to ignore certain tests or files, create a .ticonfig.yaml file in your codebase, and list the tests and files to ignore. For example:
config:
ignore:
- "README.md"
- ".ticonfig.yaml"
- "**/*.go"
- "**/Dockerfile*"
- "licenses/**/*"
- "img/**/*"
Troubleshoot Test Intelligence
Go to the CI Knowledge Base for more questions and issues related to Test Intelligence, including:
- Does Test Intelligence split tests? Can I use parallelism with Test Intelligence?
- Test Intelligence call graph is empty.
- Ruby Test Intelligence can't find rspec helper file.
- Test Intelligence fails due to Bazel not installed, but the container image has Bazel.
- Does Test Intelligence support dynamic code?
- Errors when running TI on Python code.
- Test Intelligence fails to find all classes on C# code.